 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTable as Thought: Exploring Structured Thoughts in LLM Reasoning
Jan 04, 2025Large language models' reasoning abilities benefit from methods that organize their thought processes, such as chain-of-thought prompting, which employs a sequential structure to guide the reasoning process step-by-step. However, existing approaches focus primarily on organizing the sequence of thoughts, leaving structure in individual thought steps underexplored. To address this gap, we propose Table as Thought, a framework inspired by cognitive neuroscience theories on human thought. Table as Thought organizes reasoning within a tabular schema, where rows represent sequential thought steps and columns capture critical constraints and contextual information to enhance reasoning. The reasoning process iteratively populates the table until self-verification ensures completeness and correctness. Our experiments show that Table as Thought excels in planning tasks and demonstrates a strong potential for enhancing LLM performance in mathematical reasoning compared to unstructured thought baselines. This work provides a novel exploration of refining thought representation within LLMs, paving the way for advancements in reasoning and AI cognition.
Chumor 2.0: Towards Benchmarking Chinese Humor Understanding
Dec 23, 2024



Existing humor datasets and evaluations predominantly focus on English, leaving limited resources for culturally nuanced humor in non-English languages like Chinese. To address this gap, we construct Chumor, the first Chinese humor explanation dataset that exceeds the size of existing humor datasets. Chumor is sourced from Ruo Zhi Ba, a Chinese Reddit-like platform known for sharing intellectually challenging and culturally specific jokes. We test ten LLMs through direct and chain-of-thought prompting, revealing that Chumor poses significant challenges to existing LLMs, with their accuracy slightly above random and far below human. In addition, our analysis highlights that human-annotated humor explanations are significantly better than those generated by GPT-4o and ERNIE-4-turbo. We release Chumor at https://huggingface.co/datasets/dnaihao/Chumor, our project page is at https://dnaihao.github.io/Chumor-dataset/, our leaderboard is at https://huggingface.co/spaces/dnaihao/Chumor, and our codebase is at https://github.com/dnaihao/Chumor-dataset.
Chumor 1.0: A Truly Funny and Challenging Chinese Humor Understanding Dataset from Ruo Zhi Ba
Jun 18, 2024

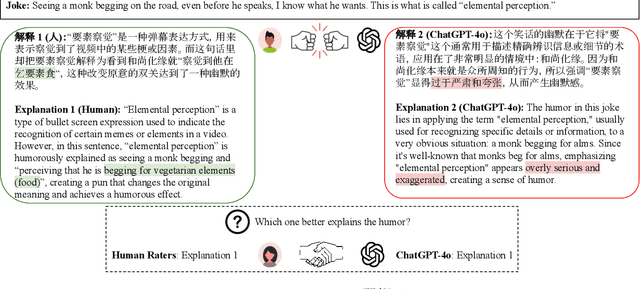
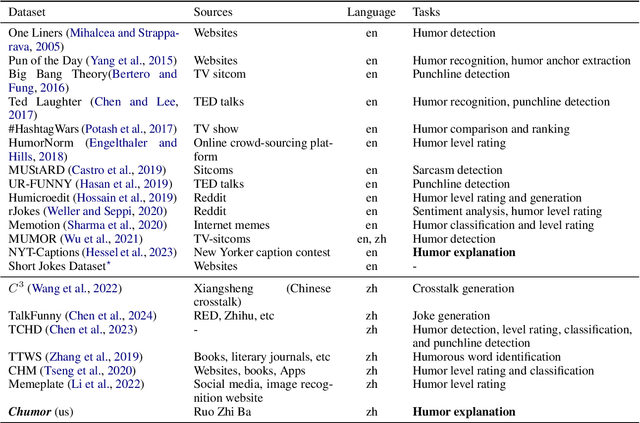
Existing humor datasets and evaluations predominantly focus on English, lacking resources for culturally nuanced humor in non-English languages like Chinese. To address this gap, we construct Chumor, a dataset sourced from Ruo Zhi Ba (RZB), a Chinese Reddit-like platform dedicated to sharing intellectually challenging and culturally specific jokes. We annotate explanations for each joke and evaluate human explanations against two state-of-the-art LLMs, GPT-4o and ERNIE Bot, through A/B testing by native Chinese speakers. Our evaluation shows that Chumor is challenging even for SOTA LLMs, and the human explanations for Chumor jokes are significantly better than explanations generated by the LLMs.
Tables as Images? Exploring the Strengths and Limitations of LLMs on Multimodal Representations of Tabular Data
Feb 23, 2024

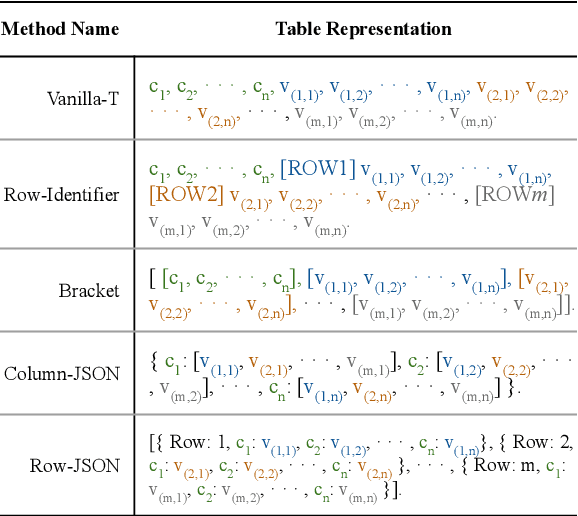

In this paper, we investigate the effectiveness of various LLMs in interpreting tabular data through different prompting strategies and data formats. Our analysis extends across six benchmarks for table-related tasks such as question-answering and fact-checking. We introduce for the first time the assessment of LLMs' performance on image-based table representations. Specifically, we compare five text-based and three image-based table representations, demonstrating the influence of representation and prompting on LLM performance. Our study provides insights into the effective use of LLMs on table-related tasks.
Observatory: Characterizing Embeddings of Relational Tables
Oct 05, 2023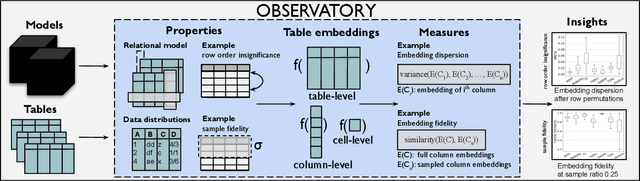
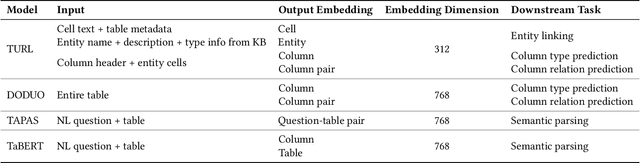
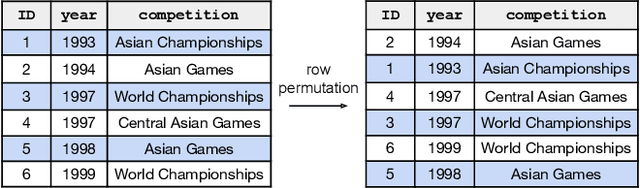
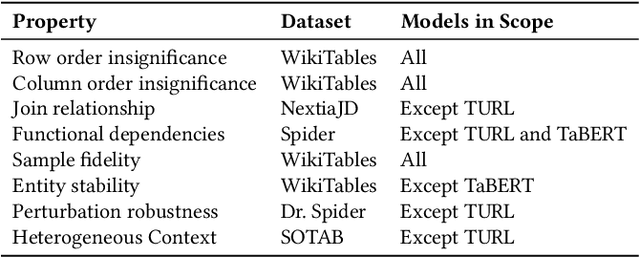
Language models and specialized table embedding models have recently demonstrated strong performance on many tasks over tabular data. Researchers and practitioners are keen to leverage these models in many new application contexts; but limited understanding of the strengths and weaknesses of these models, and the table representations they generate, makes the process of finding a suitable model for a given task reliant on trial and error. There is an urgent need to gain a comprehensive understanding of these models to minimize inefficiency and failures in downstream usage. To address this need, we propose Observatory, a formal framework to systematically analyze embedding representations of relational tables. Motivated both by invariants of the relational data model and by statistical considerations regarding data distributions, we define eight primitive properties, and corresponding measures to quantitatively characterize table embeddings for these properties. Based on these properties, we define an extensible framework to evaluate language and table embedding models. We collect and synthesize a suite of datasets and use Observatory to analyze seven such models. Our analysis provides insights into the strengths and weaknesses of learned representations over tables. We find, for example, that some models are sensitive to table structure such as column order, that functional dependencies are rarely reflected in embeddings, and that specialized table embedding models have relatively lower sample fidelity. Such insights help researchers and practitioners better anticipate model behaviors and select appropriate models for their downstream tasks, while guiding researchers in the development of new models.