 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObservatory: Characterizing Embeddings of Relational Tables
Paper and Code
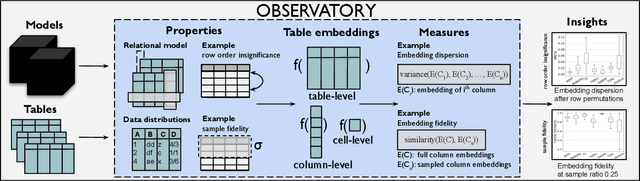
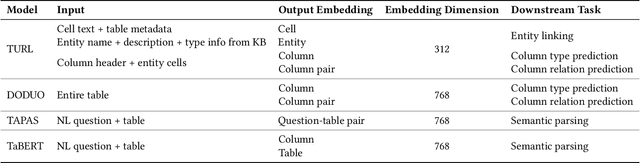
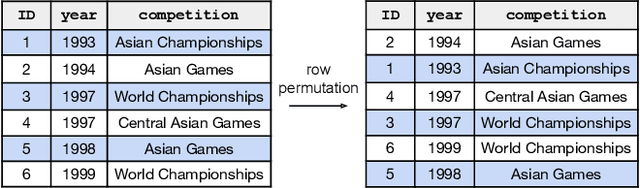
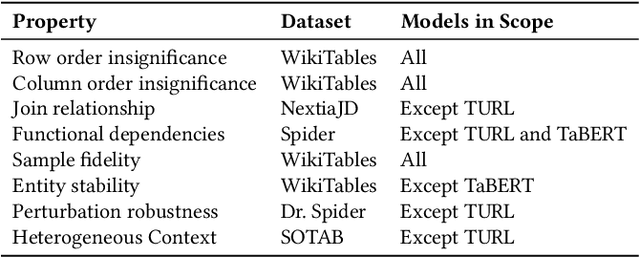
Language models and specialized table embedding models have recently demonstrated strong performance on many tasks over tabular data. Researchers and practitioners are keen to leverage these models in many new application contexts; but limited understanding of the strengths and weaknesses of these models, and the table representations they generate, makes the process of finding a suitable model for a given task reliant on trial and error. There is an urgent need to gain a comprehensive understanding of these models to minimize inefficiency and failures in downstream usage. To address this need, we propose Observatory, a formal framework to systematically analyze embedding representations of relational tables. Motivated both by invariants of the relational data model and by statistical considerations regarding data distributions, we define eight primitive properties, and corresponding measures to quantitatively characterize table embeddings for these properties. Based on these properties, we define an extensible framework to evaluate language and table embedding models. We collect and synthesize a suite of datasets and use Observatory to analyze seven such models. Our analysis provides insights into the strengths and weaknesses of learned representations over tables. We find, for example, that some models are sensitive to table structure such as column order, that functional dependencies are rarely reflected in embeddings, and that specialized table embedding models have relatively lower sample fidelity. Such insights help researchers and practitioners better anticipate model behaviors and select appropriate models for their downstream tasks, while guiding researchers in the development of new models.