 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObservatory: Characterizing Embeddings of Relational Tables
Oct 05, 2023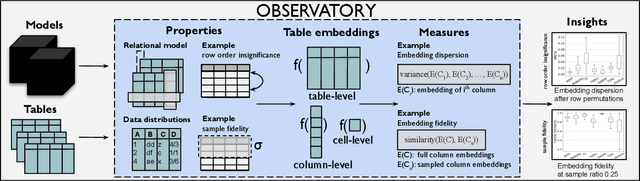
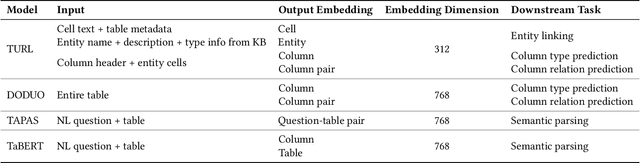
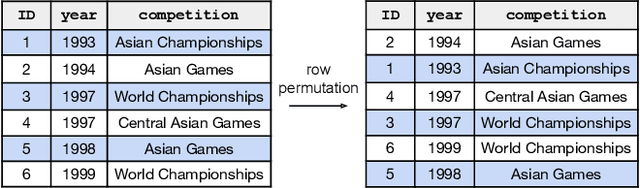
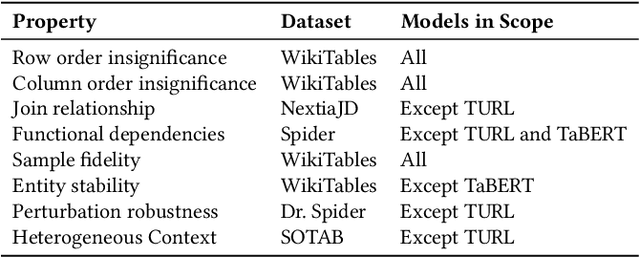
Language models and specialized table embedding models have recently demonstrated strong performance on many tasks over tabular data. Researchers and practitioners are keen to leverage these models in many new application contexts; but limited understanding of the strengths and weaknesses of these models, and the table representations they generate, makes the process of finding a suitable model for a given task reliant on trial and error. There is an urgent need to gain a comprehensive understanding of these models to minimize inefficiency and failures in downstream usage. To address this need, we propose Observatory, a formal framework to systematically analyze embedding representations of relational tables. Motivated both by invariants of the relational data model and by statistical considerations regarding data distributions, we define eight primitive properties, and corresponding measures to quantitatively characterize table embeddings for these properties. Based on these properties, we define an extensible framework to evaluate language and table embedding models. We collect and synthesize a suite of datasets and use Observatory to analyze seven such models. Our analysis provides insights into the strengths and weaknesses of learned representations over tables. We find, for example, that some models are sensitive to table structure such as column order, that functional dependencies are rarely reflected in embeddings, and that specialized table embedding models have relatively lower sample fidelity. Such insights help researchers and practitioners better anticipate model behaviors and select appropriate models for their downstream tasks, while guiding researchers in the development of new models.
Pylon: Semantic Table Union Search in Data Lakes
Jan 13, 2023The large size and fast growth of data repositories, such as data lakes, has spurred the need for data discovery to help analysts find related data. The problem has become challenging as (i) a user typically does not know what datasets exist in an enormous data repository; and (ii) there is usually a lack of a unified data model to capture the interrelationships between heterogeneous datasets from disparate sources. In this work, we address one important class of discovery needs: finding union-able tables. The task is to find tables in a data lake that can be unioned with a given query table. The challenge is to recognize union-able columns even if they are represented differently. In this paper, we propose a data-driven learning approach: specifically, an unsupervised representation learning and embedding retrieval task. Our key idea is to exploit self-supervised contrastive learning to learn an embedding model that takes into account the indexing/search data structure and produces embeddings close by for columns with semantically similar values while pushing apart columns with semantically dissimilar values. We then find union-able tables based on similarities between their constituent columns in embedding space. On a real-world data lake, we demonstrate that our best-performing model achieves significant improvements in precision ($16\% \uparrow$), recall ($17\% \uparrow $), and query response time (7x faster) compared to the state-of-the-art.
Can Attention Masks Improve Adversarial Robustness?
Dec 21, 2019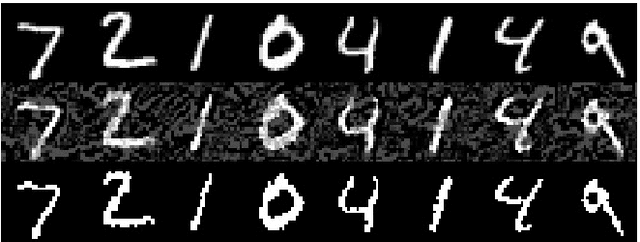


Deep Neural Networks (DNNs) are known to be susceptible to adversarial examples. Adversarial examples are maliciously crafted inputs that are designed to fool a model, but appear normal to human beings. Recent work has shown that pixel discretization can be used to make classifiers for MNIST highly robust to adversarial examples. However, pixel discretization fails to provide significant protection on more complex datasets. In this paper, we take the first step towards reconciling these contrary findings. Focusing on the observation that discrete pixelization in MNIST makes the background completely black and foreground completely white, we hypothesize that the important property for increasing robustness is the elimination of image background using attention masks before classifying an object. To examine this hypothesis, we create foreground attention masks for two different datasets, GTSRB and MS-COCO. Our initial results suggest that using attention mask leads to improved robustness. On the adversarially trained classifiers, we see an adversarial robustness increase of over 20% on MS-COCO.