 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end Adaptive Distributed Training on PaddlePaddle
Dec 06, 2021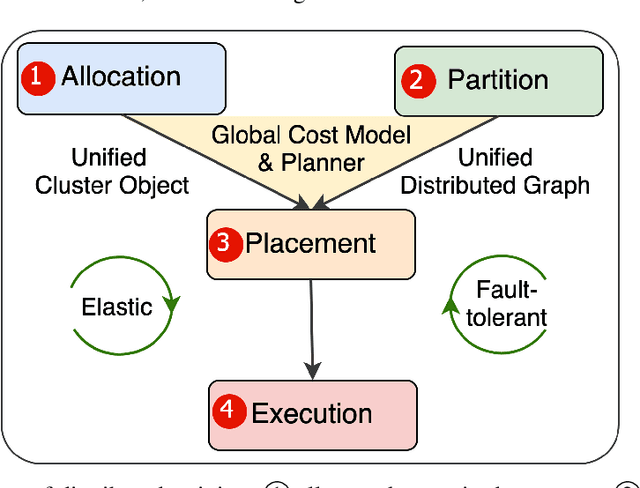
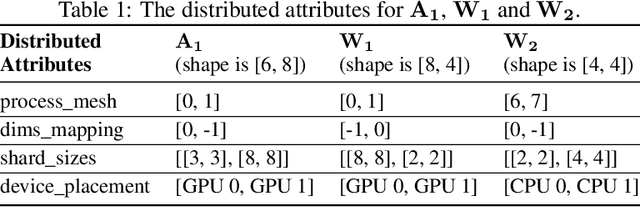
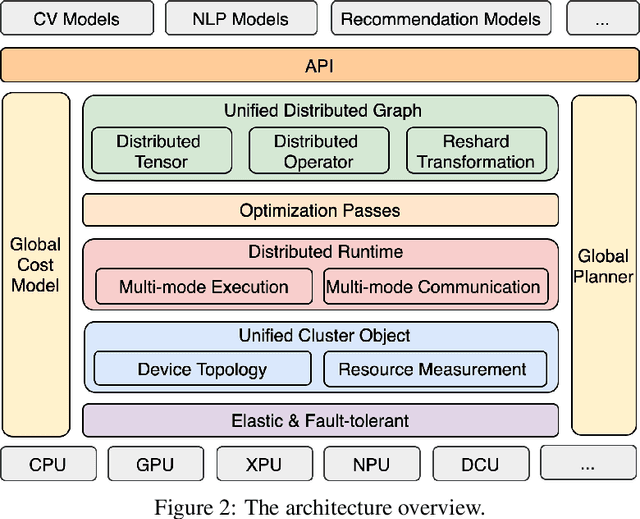
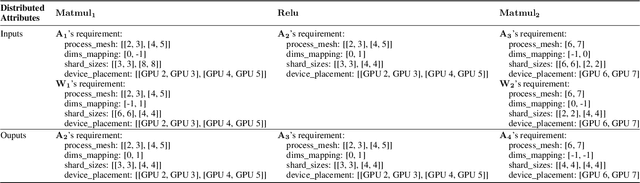
Distributed training has become a pervasive and effective approach for training a large neural network (NN) model with processing massive data. However, it is very challenging to satisfy requirements from various NN models, diverse computing resources, and their dynamic changes during a training job. In this study, we design our distributed training framework in a systematic end-to-end view to provide the built-in adaptive ability for different scenarios, especially for industrial applications and production environments, by fully considering resource allocation, model partition, task placement, and distributed execution. Based on the unified distributed graph and the unified cluster object, our adaptive framework is equipped with a global cost model and a global planner, which can enable arbitrary parallelism, resource-aware placement, multi-mode execution, fault-tolerant, and elastic distributed training. The experiments demonstrate that our framework can satisfy various requirements from the diversity of applications and the heterogeneity of resources with highly competitive performance. The ERNIE language model with 260 billion parameters is efficiently trained on thousands of AI processors with 91.7% weak scalability. The throughput of the model from the recommender system by employing the heterogeneous pipeline asynchronous execution can be increased up to 2.1 times and 3.3 times that of the GPU-only and CPU-only training respectively. Moreover, the fault-tolerant and elastic distributed training have been successfully applied to the online industrial applications, which give a reduction of 34.49% in the number of failed long-term training jobs and an increase of 33.91% for the global scheduling efficiency in the production environment.
HeterPS: Distributed Deep Learning With Reinforcement Learning Based Scheduling in Heterogeneous Environments
Nov 20, 2021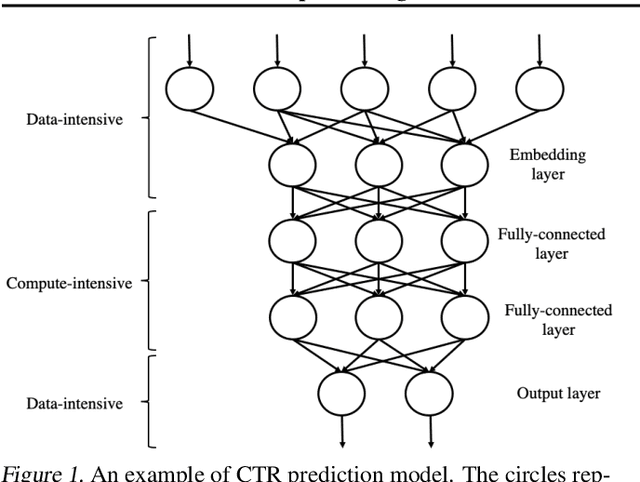


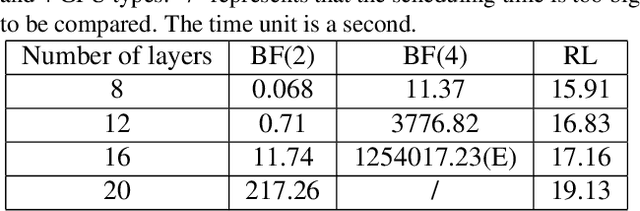
Deep neural networks (DNNs) exploit many layers and a large number of parameters to achieve excellent performance. The training process of DNN models generally handles large-scale input data with many sparse features, which incurs high Input/Output (IO) cost, while some layers are compute-intensive. The training process generally exploits distributed computing resources to reduce training time. In addition, heterogeneous computing resources, e.g., CPUs, GPUs of multiple types, are available for the distributed training process. Thus, the scheduling of multiple layers to diverse computing resources is critical for the training process. To efficiently train a DNN model using the heterogeneous computing resources, we propose a distributed framework, i.e., Paddle-Heterogeneous Parameter Server (Paddle-HeterPS), composed of a distributed architecture and a Reinforcement Learning (RL)-based scheduling method. The advantages of Paddle-HeterPS are three-fold compared with existing frameworks. First, Paddle-HeterPS enables efficient training process of diverse workloads with heterogeneous computing resources. Second, Paddle-HeterPS exploits an RL-based method to efficiently schedule the workload of each layer to appropriate computing resources to minimize the cost while satisfying throughput constraints. Third, Paddle-HeterPS manages data storage and data communication among distributed computing resources. We carry out extensive experiments to show that Paddle-HeterPS significantly outperforms state-of-the-art approaches in terms of throughput (14.5 times higher) and monetary cost (312.3% smaller). The codes of the framework are publicly available at: https://github.com/PaddlePaddle/Paddle.