 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Real-Time Super-Resolution: Benchmarking and Fine-Tuning for Streaming Content
Feb 14, 2026Recent advancements in real-time super-resolution have enabled higher-quality video streaming, yet existing methods struggle with the unique challenges of compressed video content. Commonly used datasets do not accurately reflect the characteristics of streaming media, limiting the relevance of current benchmarks. To address this gap, we introduce a comprehensive dataset - StreamSR - sourced from YouTube, covering a wide range of video genres and resolutions representative of real-world streaming scenarios. We benchmark 11 state-of-the-art real-time super-resolution models to evaluate their performance for the streaming use-case. Furthermore, we propose EfRLFN, an efficient real-time model that integrates Efficient Channel Attention and a hyperbolic tangent activation function - a novel design choice in the context of real-time super-resolution. We extensively optimized the architecture to maximize efficiency and designed a composite loss function that improves training convergence. EfRLFN combines the strengths of existing architectures while improving both visual quality and runtime performance. Finally, we show that fine-tuning other models on our dataset results in significant performance gains that generalize well across various standard benchmarks. We made the dataset, the code, and the benchmark available at https://github.com/EvgeneyBogatyrev/EfRLFN.
3D Engine-ready Photorealistic Avatars via Dynamic Textures
Mar 19, 2025As the digital and physical worlds become more intertwined, there has been a lot of interest in digital avatars that closely resemble their real-world counterparts. Current digitization methods used in 3D production pipelines require costly capture setups, making them impractical for mass usage among common consumers. Recent academic literature has found success in reconstructing humans from limited data using implicit representations (e.g., voxels used in NeRFs), which are able to produce impressive videos. However, these methods are incompatible with traditional rendering pipelines, making it difficult to use them in applications such as games. In this work, we propose an end-to-end pipeline that builds explicitly-represented photorealistic 3D avatars using standard 3D assets. Our key idea is the use of dynamically-generated textures to enhance the realism and visually mask deficiencies in the underlying mesh geometry. This allows for seamless integration with current graphics pipelines while achieving comparable visual quality to state-of-the-art 3D avatar generation methods.
Machine vision-aware quality metrics for compressed image and video assessment
Nov 11, 2024A main goal in developing video-compression algorithms is to enhance human-perceived visual quality while maintaining file size. But modern video-analysis efforts such as detection and recognition, which are integral to video surveillance and autonomous vehicles, involve so much data that they necessitate machine-vision processing with minimal human intervention. In such cases, the video codec must be optimized for machine vision. This paper explores the effects of compression on detection and recognition algorithms (objects, faces, and license plates) and introduces novel full-reference image/video-quality metrics for each task, tailored to machine vision. Experimental results indicate our proposed metrics correlate better with the machine-vision results for the respective tasks than do existing image/video-quality metrics.
JPEG AI Image Compression Visual Artifacts: Detection Methods and Dataset
Nov 11, 2024
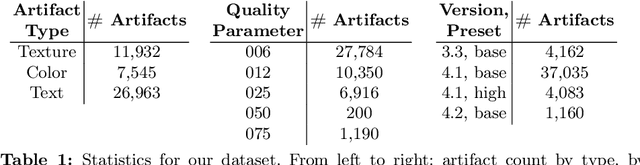

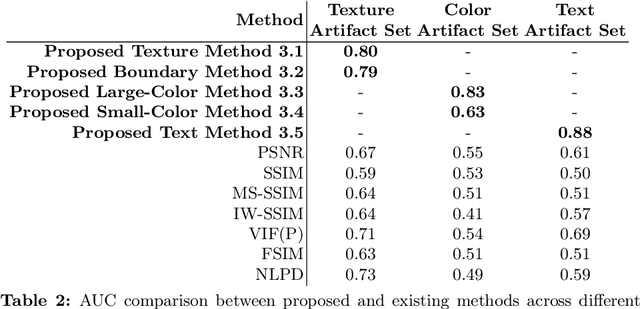
Learning-based image compression methods have improved in recent years and started to outperform traditional codecs. However, neural-network approaches can unexpectedly introduce visual artifacts in some images. We therefore propose methods to separately detect three types of artifacts (texture and boundary degradation, color change, and text corruption), to localize the affected regions, and to quantify the artifact strength. We consider only those regions that exhibit distortion due solely to the neural compression but that a traditional codec recovers successfully at a comparable bitrate. We employed our methods to collect artifacts for the JPEG AI verification model with respect to HM-18.0, the H.265 reference software. We processed about 350,000 unique images from the Open Images dataset using different compression-quality parameters; the result is a dataset of 46,440 artifacts validated through crowd-sourced subjective assessment. Our proposed dataset and methods are valuable for testing neural-network-based image codecs, identifying bugs in these codecs, and enhancing their performance. We make source code of the methods and the dataset publicly available.
AIM 2024 Challenge on Video Super-Resolution Quality Assessment: Methods and Results
Oct 05, 2024



This paper presents the Video Super-Resolution (SR) Quality Assessment (QA) Challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ECCV 2024. The task of this challenge was to develop an objective QA method for videos upscaled 2x and 4x by modern image- and video-SR algorithms. QA methods were evaluated by comparing their output with aggregate subjective scores collected from >150,000 pairwise votes obtained through crowd-sourced comparisons across 52 SR methods and 1124 upscaled videos. The goal was to advance the state-of-the-art in SR QA, which had proven to be a challenging problem with limited applicability of traditional QA methods. The challenge had 29 registered participants, and 5 teams had submitted their final results, all outperforming the current state-of-the-art. All data, including the private test subset, has been made publicly available on the challenge homepage at https://challenges.videoprocessing.ai/challenges/super-resolution-metrics-challenge.html
Can No-Reference Quality-Assessment Methods Serve as Perceptual Losses for Super-Resolution?
May 30, 2024Perceptual losses play an important role in constructing deep-neural-network-based methods by increasing the naturalness and realism of processed images and videos. Use of perceptual losses is often limited to LPIPS, a fullreference method. Even though deep no-reference image-qualityassessment methods are excellent at predicting human judgment, little research has examined their incorporation in loss functions. This paper investigates direct optimization of several video-superresolution models using no-reference image-quality-assessment methods as perceptual losses. Our experimental results show that straightforward optimization of these methods produce artifacts, but a special training procedure can mitigate them.
Compressed Video Quality Assessment for Super-Resolution: a Benchmark and a Quality Metric
May 08, 2023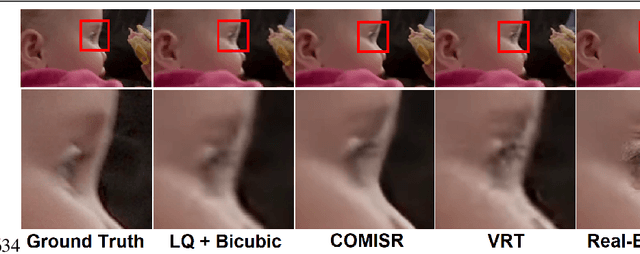
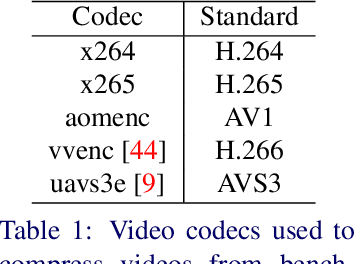
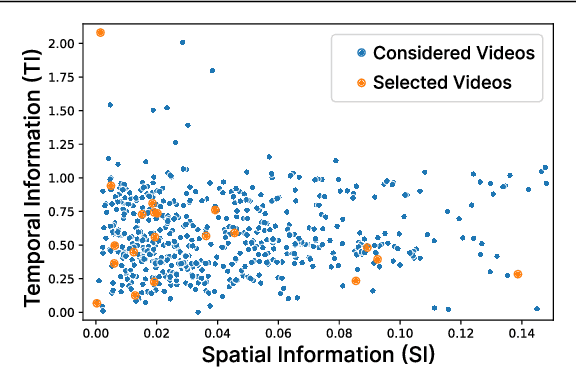
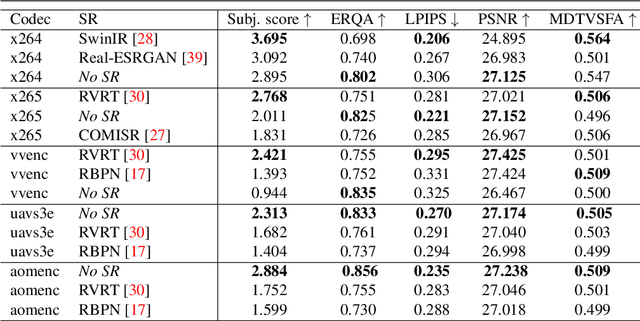
We developed a super-resolution (SR) benchmark to analyze SR's capacity to upscale compressed videos. Our dataset employed video codecs based on five compression standards: H.264, H.265, H.266, AV1, and AVS3. We assessed 17 state-ofthe-art SR models using our benchmark and evaluated their ability to preserve scene context and their susceptibility to compression artifacts. To get an accurate perceptual ranking of SR models, we conducted a crowd-sourced side-by-side comparison of their outputs. The benchmark is publicly available at https://videoprocessing.ai/benchmarks/super-resolutionfor-video-compression.html. We also analyzed benchmark results and developed an objective-quality-assessment metric based on the current bestperforming objective metrics. Our metric outperforms others, according to Spearman correlation with subjective scores for compressed video upscaling. It is publicly available at https://github.com/EvgeneyBogatyrev/super-resolution-metric.
Combining Contrastive and Supervised Learning for Video Super-Resolution Detection
May 20, 2022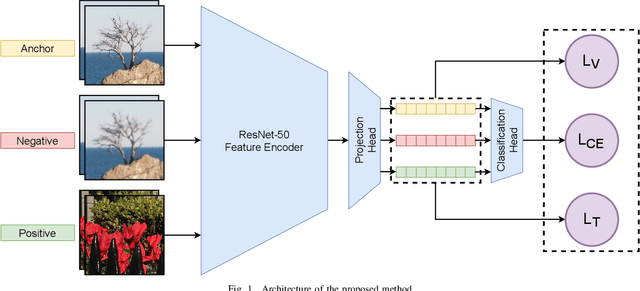
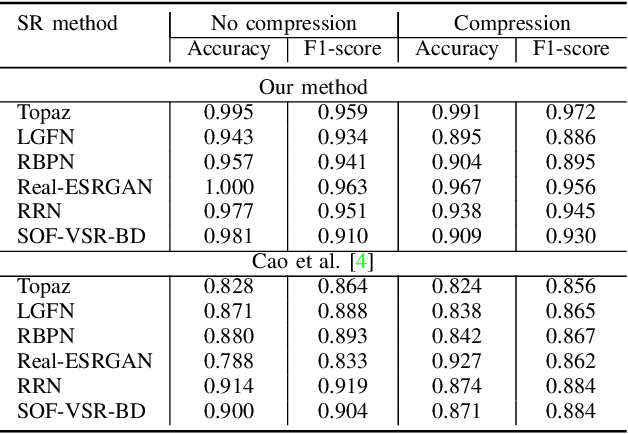
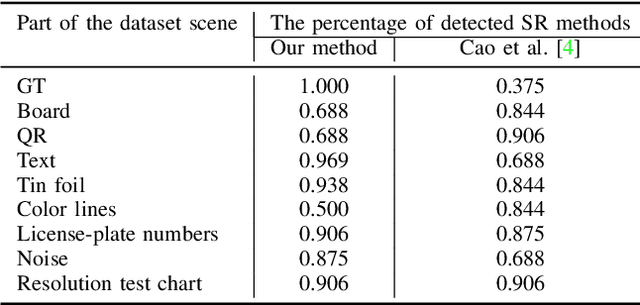
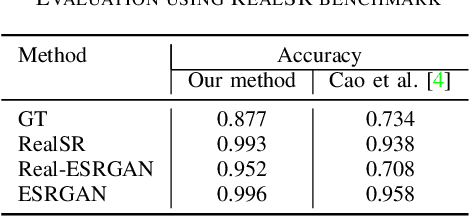
Upscaled video detection is a helpful tool in multimedia forensics, but it is a challenging task that involves various upscaling and compression algorithms. There are many resolution-enhancement methods, including interpolation and deep-learning-based super-resolution, and they leave unique traces. In this work, we propose a new upscaled-resolution-detection method based on learning of visual representations using contrastive and cross-entropy losses. To explain how the method detects videos, we systematically review the major components of our framework - in particular, we show that most data-augmentation approaches hinder the learning of the method. Through extensive experiments on various datasets, we demonstrate that our method effectively detects upscaling even in compressed videos and outperforms the state-of-the-art alternatives. The code and models are publicly available at https://github.com/msu-video-group/SRDM
Temporally Coherent Person Matting Trained on Fake-Motion Dataset
Sep 10, 2021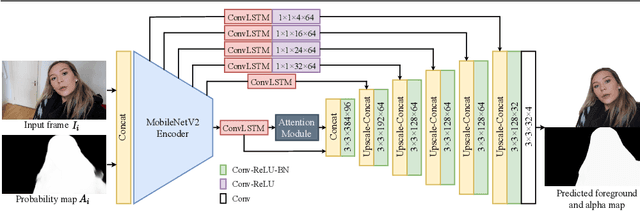
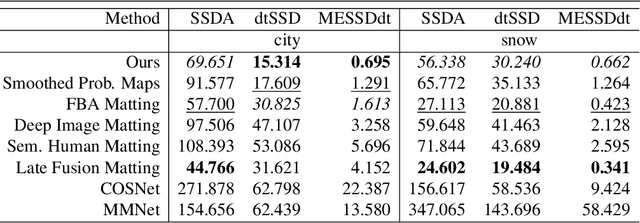
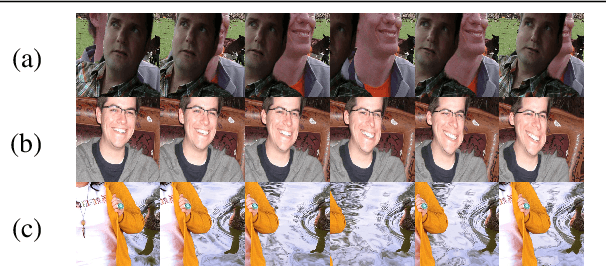
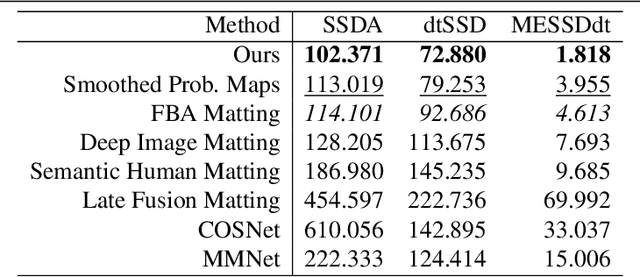
We propose a novel neural-network-based method to perform matting of videos depicting people that does not require additional user input such as trimaps. Our architecture achieves temporal stability of the resulting alpha mattes by using motion-estimation-based smoothing of image-segmentation algorithm outputs, combined with convolutional-LSTM modules on U-Net skip connections. We also propose a fake-motion algorithm that generates training clips for the video-matting network given photos with ground-truth alpha mattes and background videos. We apply random motion to photos and their mattes to simulate movement one would find in real videos and composite the result with the background clips. It lets us train a deep neural network operating on videos in an absence of a large annotated video dataset and provides ground-truth training-clip foreground optical flow for use in loss functions.
Perceptually Motivated Method for Image Inpainting Comparison
Jul 14, 2019


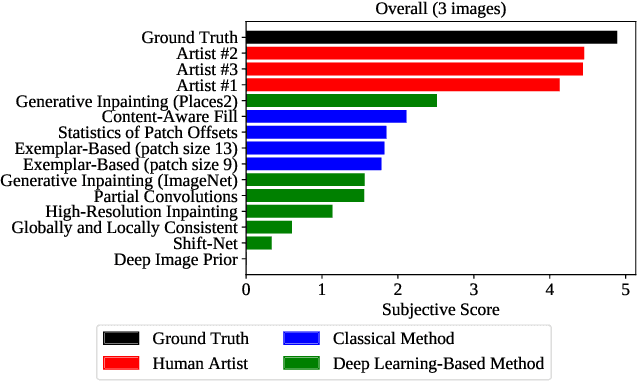
The field of automatic image inpainting has progressed rapidly in recent years, but no one has yet proposed a standard method of evaluating algorithms. This absence is due to the problem's challenging nature: image-inpainting algorithms strive for realism in the resulting images, but realism is a subjective concept intrinsic to human perception. Existing objective image-quality metrics provide a poor approximation of what humans consider more or less realistic. To improve the situation and to better organize both prior and future research in this field, we conducted a subjective comparison of nine state-of-the-art inpainting algorithms and propose objective quality metrics that exhibit high correlation with the results of our comparison.