 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEditYourself: Audio-Driven Generation and Manipulation of Talking Head Videos with Diffusion Transformers
Jan 29, 2026Current generative video models excel at producing novel content from text and image prompts, but leave a critical gap in editing existing pre-recorded videos, where minor alterations to the spoken script require preserving motion, temporal coherence, speaker identity, and accurate lip synchronization. We introduce EditYourself, a DiT-based framework for audio-driven video-to-video (V2V) editing that enables transcript-based modification of talking head videos, including the seamless addition, removal, and retiming of visually spoken content. Building on a general-purpose video diffusion model, EditYourself augments its V2V capabilities with audio conditioning and region-aware, edit-focused training extensions. This enables precise lip synchronization and temporally coherent restructuring of existing performances via spatiotemporal inpainting, including the synthesis of realistic human motion in newly added segments, while maintaining visual fidelity and identity consistency over long durations. This work represents a foundational step toward generative video models as practical tools for professional video post-production.
3D Engine-ready Photorealistic Avatars via Dynamic Textures
Mar 19, 2025As the digital and physical worlds become more intertwined, there has been a lot of interest in digital avatars that closely resemble their real-world counterparts. Current digitization methods used in 3D production pipelines require costly capture setups, making them impractical for mass usage among common consumers. Recent academic literature has found success in reconstructing humans from limited data using implicit representations (e.g., voxels used in NeRFs), which are able to produce impressive videos. However, these methods are incompatible with traditional rendering pipelines, making it difficult to use them in applications such as games. In this work, we propose an end-to-end pipeline that builds explicitly-represented photorealistic 3D avatars using standard 3D assets. Our key idea is the use of dynamically-generated textures to enhance the realism and visually mask deficiencies in the underlying mesh geometry. This allows for seamless integration with current graphics pipelines while achieving comparable visual quality to state-of-the-art 3D avatar generation methods.
Synthesizing Photorealistic Virtual Humans Through Cross-modal Disentanglement
Sep 03, 2022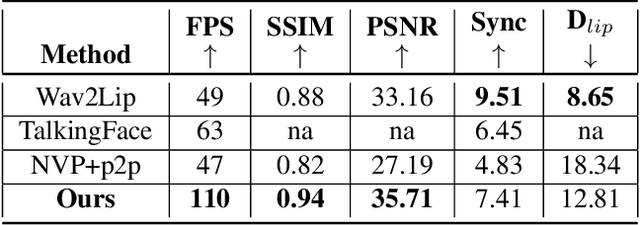
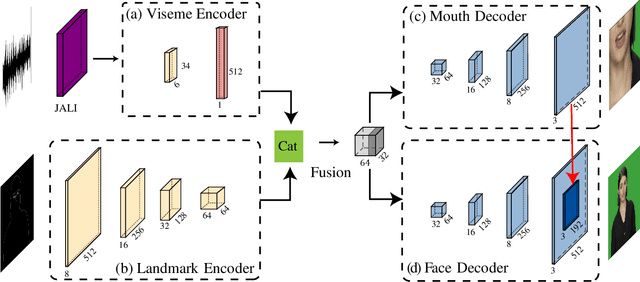
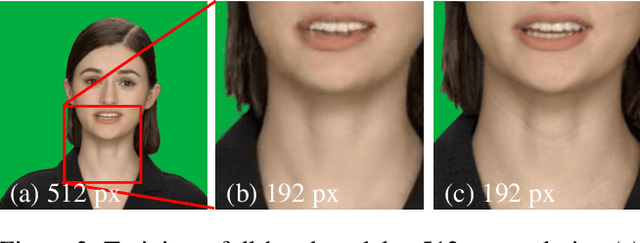
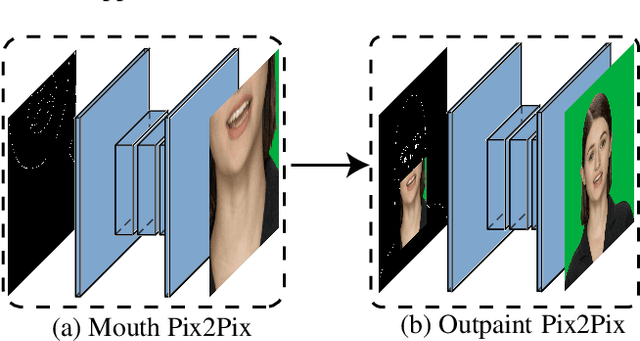
Over the last few decades, many aspects of human life have been enhanced with virtual domains, from the advent of digital assistants such as Amazon's Alexa and Apple's Siri to the latest metaverse efforts of the rebranded Meta. These trends underscore the importance of generating photorealistic visual depictions of humans. This has led to the rapid growth of so-called deepfake and talking head generation methods in recent years. Despite their impressive results and popularity, they usually lack certain qualitative aspects such as texture quality, lips synchronization, or resolution, and practical aspects such as the ability to run in real-time. To allow for virtual human avatars to be used in practical scenarios, we propose an end-to-end framework for synthesizing high-quality virtual human faces capable of speech with a special emphasis on performance. We introduce a novel network utilizing visemes as an intermediate audio representation and a novel data augmentation strategy employing a hierarchical image synthesis approach that allows disentanglement of the different modalities used to control the global head motion. Our method runs in real-time, and is able to deliver superior results compared to the current state-of-the-art.