 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Contrastive and Supervised Learning for Video Super-Resolution Detection
Paper and Code
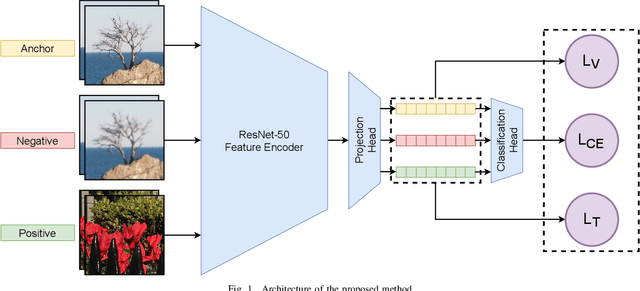
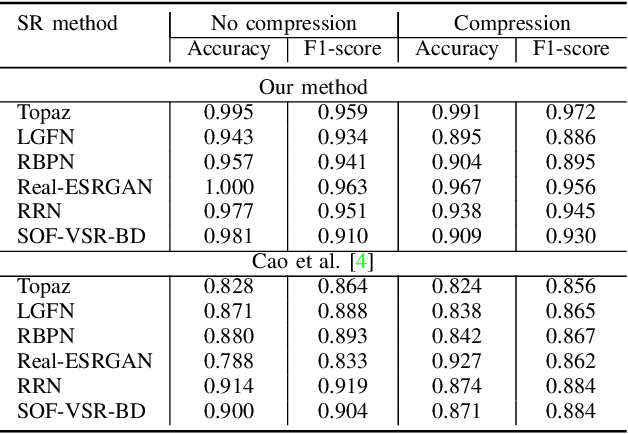
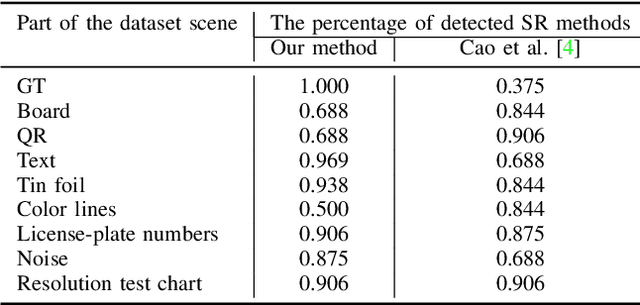
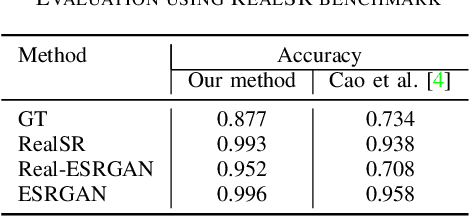
Upscaled video detection is a helpful tool in multimedia forensics, but it is a challenging task that involves various upscaling and compression algorithms. There are many resolution-enhancement methods, including interpolation and deep-learning-based super-resolution, and they leave unique traces. In this work, we propose a new upscaled-resolution-detection method based on learning of visual representations using contrastive and cross-entropy losses. To explain how the method detects videos, we systematically review the major components of our framework - in particular, we show that most data-augmentation approaches hinder the learning of the method. Through extensive experiments on various datasets, we demonstrate that our method effectively detects upscaling even in compressed videos and outperforms the state-of-the-art alternatives. The code and models are publicly available at https://github.com/msu-video-group/SRDM