 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRLPO: Residual Listwise Preference Optimization for Long-Context Review Ranking
Jan 12, 2026Review ranking is pivotal in e-commerce for prioritizing diagnostic and authentic feedback from the deluge of user-generated content. While large language models have improved semantic assessment, existing ranking paradigms face a persistent trade-off in long-context settings. Pointwise scoring is efficient but often fails to account for list-level interactions, leading to miscalibrated top-$k$ rankings. Listwise approaches can leverage global context, yet they are computationally expensive and become unstable as candidate lists grow. To address this, we propose Residual Listwise Preference Optimization (RLPO), which formulates ranking as listwise representation-level residual correction over a strong pointwise LLM scorer. RLPO first produces calibrated pointwise scores and item representations, then applies a lightweight encoder over the representations to predict listwise score residuals, avoiding full token-level listwise processing. We also introduce a large-scale benchmark for long-context review ranking with human verification. Experiments show RLPO improves NDCG@k over strong pointwise and listwise baselines and remains robust as list length increases.
GLEAM: Learning to Match and Explain in Cross-View Geo-Localization
Sep 09, 2025Cross-View Geo-Localization (CVGL) focuses on identifying correspondences between images captured from distinct perspectives of the same geographical location. However, existing CVGL approaches are typically restricted to a single view or modality, and their direct visual matching strategy lacks interpretability: they merely predict whether two images correspond, without explaining the rationale behind the match. In this paper, we present GLEAM-C, a foundational CVGL model that unifies multiple views and modalities-including UAV imagery, street maps, panoramic views, and ground photographs-by aligning them exclusively with satellite imagery. Our framework enhances training efficiency through optimized implementation while achieving accuracy comparable to prior modality-specific CVGL models through a two-phase training strategy. Moreover, to address the lack of interpretability in traditional CVGL methods, we leverage the reasoning capabilities of multimodal large language models (MLLMs) to propose a new task, GLEAM-X, which combines cross-view correspondence prediction with explainable reasoning. To support this task, we construct a bilingual benchmark using GPT-4o and Doubao-1.5-Thinking-Vision-Pro to generate training and testing data. The test set is further refined through detailed human revision, enabling systematic evaluation of explainable cross-view reasoning and advancing transparency and scalability in geo-localization. Together, GLEAM-C and GLEAM-X form a comprehensive CVGL pipeline that integrates multi-modal, multi-view alignment with interpretable correspondence analysis, unifying accurate cross-view matching with explainable reasoning and advancing Geo-Localization by enabling models to better Explain And Match. Code and datasets used in this work will be made publicly accessible at https://github.com/Lucky-Lance/GLEAM.
MRSE: An Efficient Multi-modality Retrieval System for Large Scale E-commerce
Aug 27, 2024



Providing high-quality item recall for text queries is crucial in large-scale e-commerce search systems. Current Embedding-based Retrieval Systems (ERS) embed queries and items into a shared low-dimensional space, but uni-modality ERS rely too heavily on textual features, making them unreliable in complex contexts. While multi-modality ERS incorporate various data sources, they often overlook individual preferences for different modalities, leading to suboptimal results. To address these issues, we propose MRSE, a Multi-modality Retrieval System that integrates text, item images, and user preferences through lightweight mixture-of-expert (LMoE) modules to better align features across and within modalities. MRSE also builds user profiles at a multi-modality level and introduces a novel hybrid loss function that enhances consistency and robustness using hard negative sampling. Experiments on a large-scale dataset from Shopee and online A/B testing show that MRSE achieves an 18.9% improvement in offline relevance and a 3.7% gain in online core metrics compared to Shopee's state-of-the-art uni-modality system.
Q-Ground: Image Quality Grounding with Large Multi-modality Models
Jul 24, 2024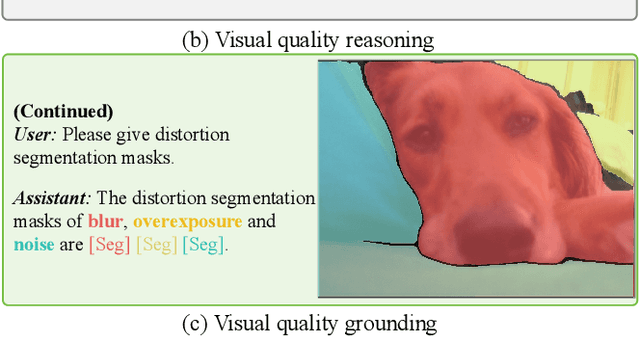


Recent advances of large multi-modality models (LMM) have greatly improved the ability of image quality assessment (IQA) method to evaluate and explain the quality of visual content. However, these advancements are mostly focused on overall quality assessment, and the detailed examination of local quality, which is crucial for comprehensive visual understanding, is still largely unexplored. In this work, we introduce Q-Ground, the first framework aimed at tackling fine-scale visual quality grounding by combining large multi-modality models with detailed visual quality analysis. Central to our contribution is the introduction of the QGround-100K dataset, a novel resource containing 100k triplets of (image, quality text, distortion segmentation) to facilitate deep investigations into visual quality. The dataset comprises two parts: one with human-labeled annotations for accurate quality assessment, and another labeled automatically by LMMs such as GPT4V, which helps improve the robustness of model training while also reducing the costs of data collection. With the QGround-100K dataset, we propose a LMM-based method equipped with multi-scale feature learning to learn models capable of performing both image quality answering and distortion segmentation based on text prompts. This dual-capability approach not only refines the model's understanding of region-aware image quality but also enables it to interactively respond to complex, text-based queries about image quality and specific distortions. Q-Ground takes a step towards sophisticated visual quality analysis in a finer scale, establishing a new benchmark for future research in the area. Codes and dataset are available at https://github.com/Q-Future/Q-Ground.
Towards Open-ended Visual Quality Comparison
Mar 04, 2024Comparative settings (e.g. pairwise choice, listwise ranking) have been adopted by a wide range of subjective studies for image quality assessment (IQA), as it inherently standardizes the evaluation criteria across different observers and offer more clear-cut responses. In this work, we extend the edge of emerging large multi-modality models (LMMs) to further advance visual quality comparison into open-ended settings, that 1) can respond to open-range questions on quality comparison; 2) can provide detailed reasonings beyond direct answers. To this end, we propose the Co-Instruct. To train this first-of-its-kind open-source open-ended visual quality comparer, we collect the Co-Instruct-562K dataset, from two sources: (a) LLM-merged single image quality description, (b) GPT-4V "teacher" responses on unlabeled data. Furthermore, to better evaluate this setting, we propose the MICBench, the first benchmark on multi-image comparison for LMMs. We demonstrate that Co-Instruct not only achieves in average 30% higher accuracy than state-of-the-art open-source LMMs, but also outperforms GPT-4V (its teacher), on both existing related benchmarks and the proposed MICBench. Our model is published at https://huggingface.co/q-future/co-instruct.
Q-Align: Teaching LMMs for Visual Scoring via Discrete Text-Defined Levels
Dec 28, 2023



The explosion of visual content available online underscores the requirement for an accurate machine assessor to robustly evaluate scores across diverse types of visual contents. While recent studies have demonstrated the exceptional potentials of large multi-modality models (LMMs) on a wide range of related fields, in this work, we explore how to teach them for visual rating aligned with human opinions. Observing that human raters only learn and judge discrete text-defined levels in subjective studies, we propose to emulate this subjective process and teach LMMs with text-defined rating levels instead of scores. The proposed Q-Align achieves state-of-the-art performance on image quality assessment (IQA), image aesthetic assessment (IAA), as well as video quality assessment (VQA) tasks under the original LMM structure. With the syllabus, we further unify the three tasks into one model, termed the OneAlign. In our experiments, we demonstrate the advantage of the discrete-level-based syllabus over direct-score-based variants for LMMs. Our code and the pre-trained weights are released at https://github.com/Q-Future/Q-Align.
Enhancing Diffusion Models with Text-Encoder Reinforcement Learning
Nov 27, 2023
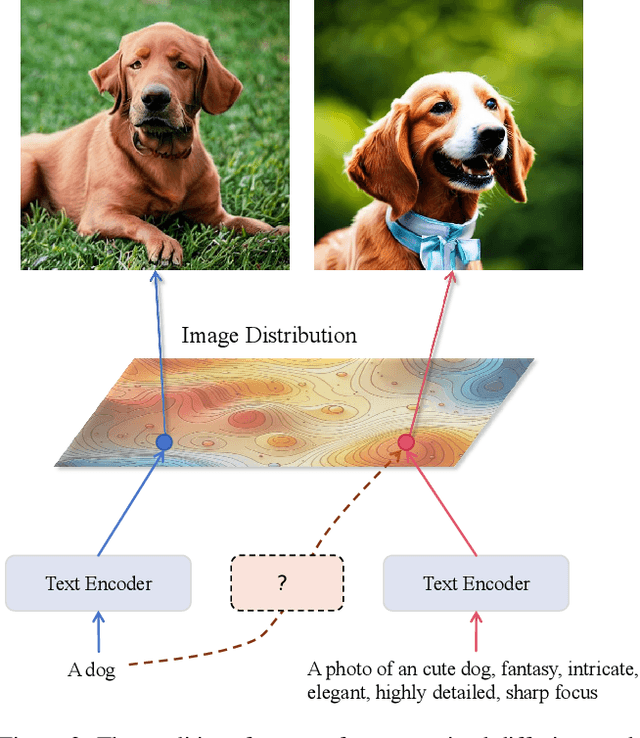
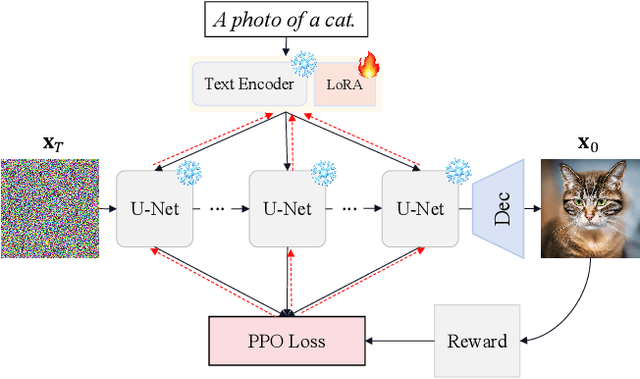

Text-to-image diffusion models are typically trained to optimize the log-likelihood objective, which presents challenges in meeting specific requirements for downstream tasks, such as image aesthetics and image-text alignment. Recent research addresses this issue by refining the diffusion U-Net using human rewards through reinforcement learning or direct backpropagation. However, many of them overlook the importance of the text encoder, which is typically pretrained and fixed during training. In this paper, we demonstrate that by finetuning the text encoder through reinforcement learning, we can enhance the text-image alignment of the results, thereby improving the visual quality. Our primary motivation comes from the observation that the current text encoder is suboptimal, often requiring careful prompt adjustment. While fine-tuning the U-Net can partially improve performance, it remains suffering from the suboptimal text encoder. Therefore, we propose to use reinforcement learning with low-rank adaptation to finetune the text encoder based on task-specific rewards, referred as \textbf{TexForce}. We first show that finetuning the text encoder can improve the performance of diffusion models. Then, we illustrate that TexForce can be simply combined with existing U-Net finetuned models to get much better results without additional training. Finally, we showcase the adaptability of our method in diverse applications, including the generation of high-quality face and hand images.
Q-Instruct: Improving Low-level Visual Abilities for Multi-modality Foundation Models
Nov 12, 2023



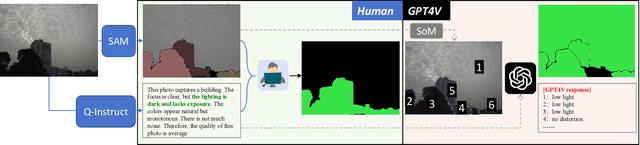
Multi-modality foundation models, as represented by GPT-4V, have brought a new paradigm for low-level visual perception and understanding tasks, that can respond to a broad range of natural human instructions in a model. While existing foundation models have shown exciting potentials on low-level visual tasks, their related abilities are still preliminary and need to be improved. In order to enhance these models, we conduct a large-scale subjective experiment collecting a vast number of real human feedbacks on low-level vision. Each feedback follows a pathway that starts with a detailed description on the low-level visual appearance (*e.g. clarity, color, brightness* of an image, and ends with an overall conclusion, with an average length of 45 words. The constructed **Q-Pathway** dataset includes 58K detailed human feedbacks on 18,973 images with diverse low-level appearance. Moreover, to enable foundation models to robustly respond to diverse types of questions, we design a GPT-participated conversion to process these feedbacks into diverse-format 200K instruction-response pairs. Experimental results indicate that the **Q-Instruct** consistently elevates low-level perception and understanding abilities across several foundational models. We anticipate that our datasets can pave the way for a future that general intelligence can perceive, understand low-level visual appearance and evaluate visual quality like a human. Our dataset, model zoo, and demo is published at: https://q-future.github.io/Q-Instruct.
Q-Bench: A Benchmark for General-Purpose Foundation Models on Low-level Vision
Sep 28, 2023The rapid evolution of Multi-modality Large Language Models (MLLMs) has catalyzed a shift in computer vision from specialized models to general-purpose foundation models. Nevertheless, there is still an inadequacy in assessing the abilities of MLLMs on low-level visual perception and understanding. To address this gap, we present Q-Bench, a holistic benchmark crafted to systematically evaluate potential abilities of MLLMs on three realms: low-level visual perception, low-level visual description, and overall visual quality assessment. a) To evaluate the low-level perception ability, we construct the LLVisionQA dataset, consisting of 2,990 diverse-sourced images, each equipped with a human-asked question focusing on its low-level attributes. We then measure the correctness of MLLMs on answering these questions. b) To examine the description ability of MLLMs on low-level information, we propose the LLDescribe dataset consisting of long expert-labelled golden low-level text descriptions on 499 images, and a GPT-involved comparison pipeline between outputs of MLLMs and the golden descriptions. c) Besides these two tasks, we further measure their visual quality assessment ability to align with human opinion scores. Specifically, we design a softmax-based strategy that enables MLLMs to predict quantifiable quality scores, and evaluate them on various existing image quality assessment (IQA) datasets. Our evaluation across the three abilities confirms that MLLMs possess preliminary low-level visual skills. However, these skills are still unstable and relatively imprecise, indicating the need for specific enhancements on MLLMs towards these abilities. We hope that our benchmark can encourage the research community to delve deeper to discover and enhance these untapped potentials of MLLMs. Project Page: https://vqassessment.github.io/Q-Bench.
Towards Explainable In-the-Wild Video Quality Assessment: a Database and a Language-Prompted Approach
May 22, 2023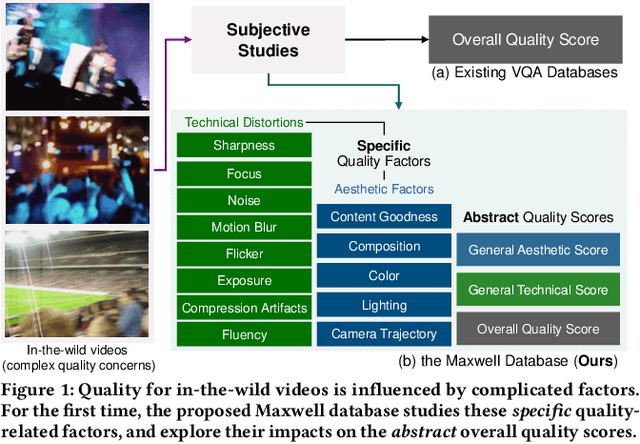
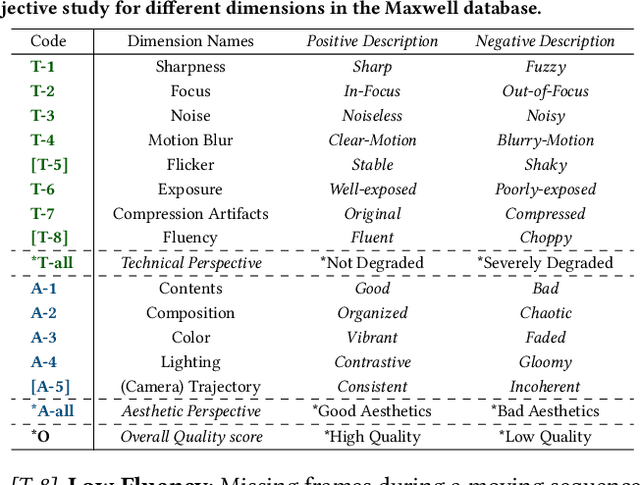
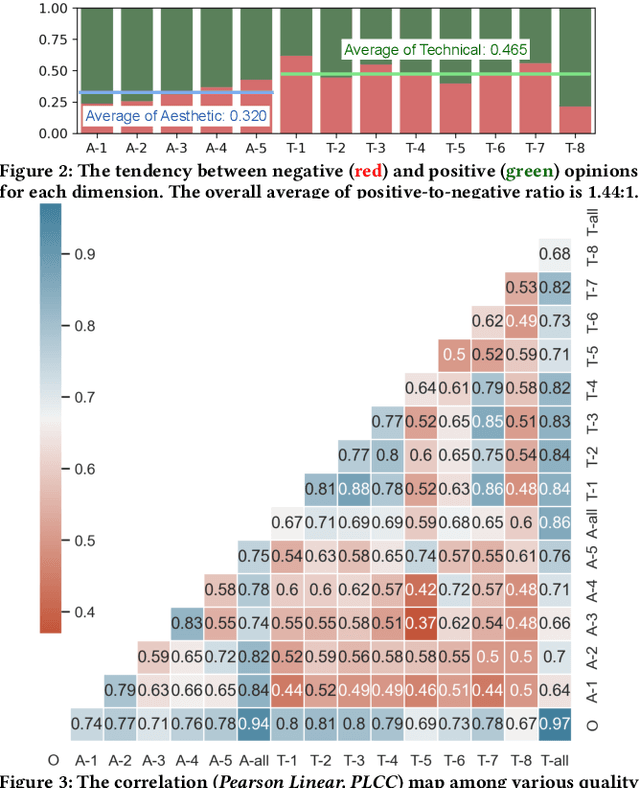
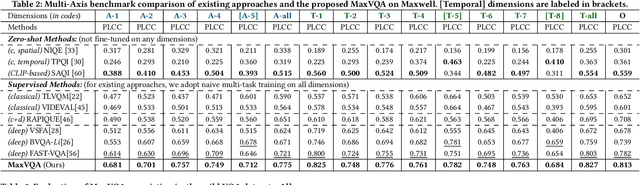
The proliferation of in-the-wild videos has greatly expanded the Video Quality Assessment (VQA) problem. Unlike early definitions that usually focus on limited distortion types, VQA on in-the-wild videos is especially challenging as it could be affected by complicated factors, including various distortions and diverse contents. Though subjective studies have collected overall quality scores for these videos, how the abstract quality scores relate with specific factors is still obscure, hindering VQA methods from more concrete quality evaluations (e.g. sharpness of a video). To solve this problem, we collect over two million opinions on 4,543 in-the-wild videos on 13 dimensions of quality-related factors, including in-capture authentic distortions (e.g. motion blur, noise, flicker), errors introduced by compression and transmission, and higher-level experiences on semantic contents and aesthetic issues (e.g. composition, camera trajectory), to establish the multi-dimensional Maxwell database. Specifically, we ask the subjects to label among a positive, a negative, and a neural choice for each dimension. These explanation-level opinions allow us to measure the relationships between specific quality factors and abstract subjective quality ratings, and to benchmark different categories of VQA algorithms on each dimension, so as to more comprehensively analyze their strengths and weaknesses. Furthermore, we propose the MaxVQA, a language-prompted VQA approach that modifies vision-language foundation model CLIP to better capture important quality issues as observed in our analyses. The MaxVQA can jointly evaluate various specific quality factors and final quality scores with state-of-the-art accuracy on all dimensions, and superb generalization ability on existing datasets. Code and data available at \url{https://github.com/VQAssessment/MaxVQA}.