 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGEX: Democratizing Dexterity with Fully-Actuated Dexterous Hand and Exoskeleton Glove
Jun 05, 2025This paper introduces GEX, an innovative low-cost dexterous manipulation system that combines the GX11 tri-finger anthropomorphic hand (11 DoF) with the EX12 tri-finger exoskeleton glove (12 DoF), forming a closed-loop teleoperation framework through kinematic retargeting for high-fidelity control. Both components employ modular 3D-printed finger designs, achieving ultra-low manufacturing costs while maintaining full actuation capabilities. Departing from conventional tendon-driven or underactuated approaches, our electromechanical system integrates independent joint motors across all 23 DoF, ensuring complete state observability and accurate kinematic modeling. This full-actuation architecture enables precise bidirectional kinematic calculations, substantially enhancing kinematic retargeting fidelity between the exoskeleton and robotic hand. The proposed system bridges the cost-performance gap in dexterous manipulation research, providing an accessible platform for acquiring high-quality demonstration data to advance embodied AI and dexterous robotic skill transfer learning.
Light-VQA+: A Video Quality Assessment Model for Exposure Correction with Vision-Language Guidance
May 06, 2024



Recently, User-Generated Content (UGC) videos have gained popularity in our daily lives. However, UGC videos often suffer from poor exposure due to the limitations of photographic equipment and techniques. Therefore, Video Exposure Correction (VEC) algorithms have been proposed, Low-Light Video Enhancement (LLVE) and Over-Exposed Video Recovery (OEVR) included. Equally important to the VEC is the Video Quality Assessment (VQA). Unfortunately, almost all existing VQA models are built generally, measuring the quality of a video from a comprehensive perspective. As a result, Light-VQA, trained on LLVE-QA, is proposed for assessing LLVE. We extend the work of Light-VQA by expanding the LLVE-QA dataset into Video Exposure Correction Quality Assessment (VEC-QA) dataset with over-exposed videos and their corresponding corrected versions. In addition, we propose Light-VQA+, a VQA model specialized in assessing VEC. Light-VQA+ differs from Light-VQA mainly from the usage of the CLIP model and the vision-language guidance during the feature extraction, followed by a new module referring to the Human Visual System (HVS) for more accurate assessment. Extensive experimental results show that our model achieves the best performance against the current State-Of-The-Art (SOTA) VQA models on the VEC-QA dataset and other public datasets.
NTIRE 2023 Quality Assessment of Video Enhancement Challenge
Jul 19, 2023



This paper reports on the NTIRE 2023 Quality Assessment of Video Enhancement Challenge, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2023. This challenge is to address a major challenge in the field of video processing, namely, video quality assessment (VQA) for enhanced videos. The challenge uses the VQA Dataset for Perceptual Video Enhancement (VDPVE), which has a total of 1211 enhanced videos, including 600 videos with color, brightness, and contrast enhancements, 310 videos with deblurring, and 301 deshaked videos. The challenge has a total of 167 registered participants. 61 participating teams submitted their prediction results during the development phase, with a total of 3168 submissions. A total of 176 submissions were submitted by 37 participating teams during the final testing phase. Finally, 19 participating teams submitted their models and fact sheets, and detailed the methods they used. Some methods have achieved better results than baseline methods, and the winning methods have demonstrated superior prediction performance.
Light-VQA: A Multi-Dimensional Quality Assessment Model for Low-Light Video Enhancement
May 16, 2023



Recently, Users Generated Content (UGC) videos becomes ubiquitous in our daily lives. However, due to the limitations of photographic equipments and techniques, UGC videos often contain various degradations, in which one of the most visually unfavorable effects is the underexposure. Therefore, corresponding video enhancement algorithms such as Low-Light Video Enhancement (LLVE) have been proposed to deal with the specific degradation. However, different from video enhancement algorithms, almost all existing Video Quality Assessment (VQA) models are built generally rather than specifically, which measure the quality of a video from a comprehensive perspective. To the best of our knowledge, there is no VQA model specially designed for videos enhanced by LLVE algorithms. To this end, we first construct a Low-Light Video Enhancement Quality Assessment (LLVE-QA) dataset in which 254 original low-light videos are collected and then enhanced by leveraging 8 LLVE algorithms to obtain 2,060 videos in total. Moreover, we propose a quality assessment model specialized in LLVE, named Light-VQA. More concretely, since the brightness and noise have the most impact on low-light enhanced VQA, we handcraft corresponding features and integrate them with deep-learning-based semantic features as the overall spatial information. As for temporal information, in addition to deep-learning-based motion features, we also investigate the handcrafted brightness consistency among video frames, and the overall temporal information is their concatenation. Subsequently, spatial and temporal information is fused to obtain the quality-aware representation of a video. Extensive experimental results show that our Light-VQA achieves the best performance against the current State-Of-The-Art (SOTA) on LLVE-QA and public dataset. Dataset and Codes can be found at https://github.com/wenzhouyidu/Light-VQA.
VDPVE: VQA Dataset for Perceptual Video Enhancement
Mar 16, 2023


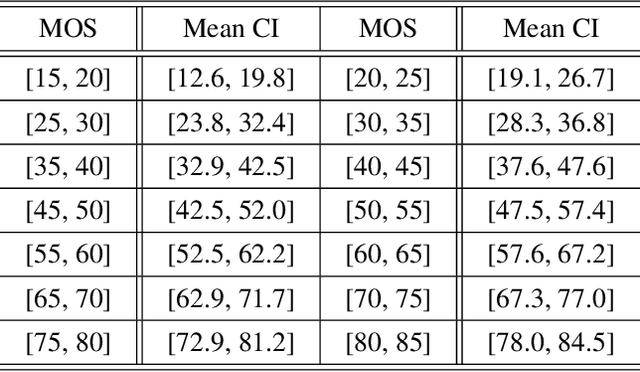
Recently, many video enhancement methods have been proposed to improve video quality from different aspects such as color, brightness, contrast, and stability. Therefore, how to evaluate the quality of the enhanced video in a way consistent with human visual perception is an important research topic. However, most video quality assessment methods mainly calculate video quality by estimating the distortion degrees of videos from an overall perspective. Few researchers have specifically proposed a video quality assessment method for video enhancement, and there is also no comprehensive video quality assessment dataset available in public. Therefore, we construct a Video quality assessment dataset for Perceptual Video Enhancement (VDPVE) in this paper. The VDPVE has 1211 videos with different enhancements, which can be divided into three sub-datasets: the first sub-dataset has 600 videos with color, brightness, and contrast enhancements; the second sub-dataset has 310 videos with deblurring; and the third sub-dataset has 301 deshaked videos. We invited 21 subjects (20 valid subjects) to rate all enhanced videos in the VDPVE. After normalizing and averaging the subjective opinion scores, the mean opinion score of each video can be obtained. Furthermore, we split the VDPVE into a training set, a validation set, and a test set, and verify the performance of several state-of-the-art video quality assessment methods on the test set of the VDPVE.
Convergence Analysis of Nonconvex Distributed Stochastic Zeroth-order Coordinate Method
Mar 24, 2021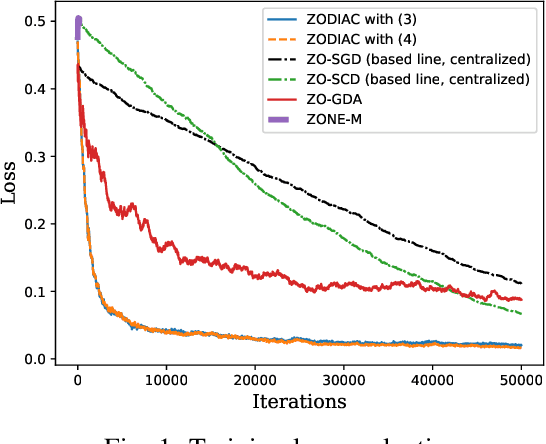


This paper investigates the stochastic distributed nonconvex optimization problem of minimizing a global cost function formed by the summation of $n$ local cost functions. We solve such a problem by involving zeroth-order (ZO) information exchange. In this paper, we propose a ZO distributed primal-dual coordinate method (ZODIAC) to solve the stochastic optimization problem. Agents approximate their own local stochastic ZO oracle along with coordinates with an adaptive smoothing parameter. We show that the proposed algorithm achieves the convergence rate of $\mathcal{O}(\sqrt{p}/\sqrt{T})$ for general nonconvex cost functions. We demonstrate the efficiency of proposed algorithms through a numerical example in comparison with the existing state-of-the-art centralized and distributed ZO algorithms.