 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedPCA: Noise-Robust Fair Federated Learning via Performance-Capacity Analysis
Paper and Code
Mar 13, 2025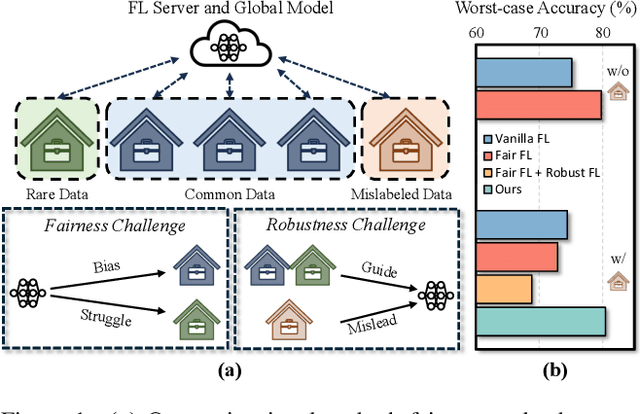

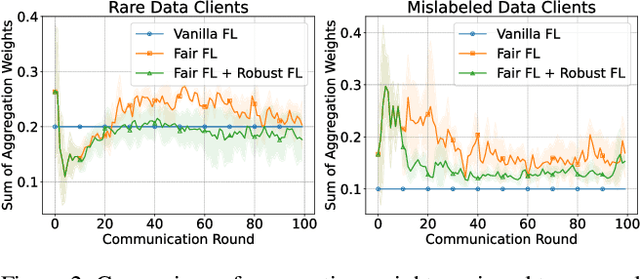
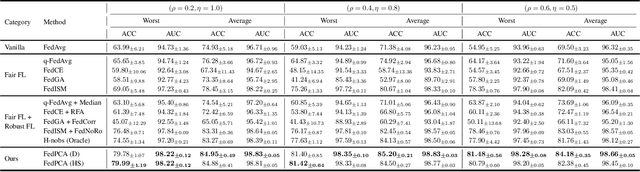
Training a model that effectively handles both common and rare data-i.e., achieving performance fairness-is crucial in federated learning (FL). While existing fair FL methods have shown effectiveness, they remain vulnerable to mislabeled data. Ensuring robustness in fair FL is therefore essential. However, fairness and robustness inherently compete, which causes robust strategies to hinder fairness. In this paper, we attribute this competition to the homogeneity in loss patterns exhibited by rare and mislabeled data clients, preventing existing loss-based fair and robust FL methods from effectively distinguishing and handling these two distinct client types. To address this, we propose performance-capacity analysis, which jointly considers model performance on each client and its capacity to handle the dataset, measured by loss and a newly introduced feature dispersion score. This allows mislabeled clients to be identified by their significantly deviated performance relative to capacity while preserving rare data clients. Building on this, we introduce FedPCA, an FL method that robustly achieves fairness. FedPCA first identifies mislabeled clients via a Gaussian Mixture Model on loss-dispersion pairs, then applies fairness and robustness strategies in global aggregation and local training by adjusting client weights and selectively using reliable data. Extensive experiments on three datasets demonstrate FedPCA's effectiveness in tackling this complex challenge. Code will be publicly available upon acceptance.