 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Domain-Specific LLM Benchmark Construction: A Comprehensiveness-Compactness Approach
Aug 13, 2025Numerous benchmarks have been built to evaluate the domain-specific abilities of large language models (LLMs), highlighting the need for effective and efficient benchmark construction. Existing domain-specific benchmarks primarily focus on the scaling law, relying on massive corpora for supervised fine-tuning or generating extensive question sets for broad coverage. However, the impact of corpus and question-answer (QA) set design on the precision and recall of domain-specific LLMs remains unexplored. In this paper, we address this gap and demonstrate that the scaling law is not always the optimal principle for benchmark construction in specific domains. Instead, we propose Comp-Comp, an iterative benchmarking framework based on a comprehensiveness-compactness principle. Here, comprehensiveness ensures semantic recall of the domain, while compactness enhances precision, guiding both corpus and QA set construction. To validate our framework, we conducted a case study in a well-renowned university, resulting in the creation of XUBench, a large-scale and comprehensive closed-domain benchmark. Although we use the academic domain as the case in this work, our Comp-Comp framework is designed to be extensible beyond academia, providing valuable insights for benchmark construction across various domains.
Mean of Means: Human Localization with Calibration-free and Unconstrained Camera Settings (extended version)
Feb 18, 2025



Accurate human localization is crucial for various applications, especially in the Metaverse era. Existing high precision solutions rely on expensive, tag-dependent hardware, while vision-based methods offer a cheaper, tag-free alternative. However, current vision solutions based on stereo vision face limitations due to rigid perspective transformation principles and error propagation in multi-stage SVD solvers. These solutions also require multiple high-resolution cameras with strict setup constraints.To address these limitations, we propose a probabilistic approach that considers all points on the human body as observations generated by a distribution centered around the body's geometric center. This enables us to improve sampling significantly, increasing the number of samples for each point of interest from hundreds to billions. By modeling the relation between the means of the distributions of world coordinates and pixel coordinates, leveraging the Central Limit Theorem, we ensure normality and facilitate the learning process. Experimental results demonstrate human localization accuracy of 96\% within a 0.3$m$ range and nearly 100\% accuracy within a 0.5$m$ range, achieved at a low cost of only 10 USD using two web cameras with a resolution of 640$\times$480 pixels.
Multi-Level Querying using A Knowledge Pyramid
Jul 31, 2024



This paper addresses the need for improved precision in existing Retrieval-Augmented Generation (RAG) methods that primarily focus on enhancing recall. We propose a multi-layer knowledge pyramid approach within the RAG framework to achieve a better balance between precision and recall. The knowledge pyramid consists of three layers: Ontologies, Knowledge Graphs (KGs), and chunk-based raw text. We employ cross-layer augmentation techniques for comprehensive knowledge coverage and dynamic updates of the Ontology schema and instances. To ensure compactness, we utilize cross-layer filtering methods for knowledge condensation in KGs. Our approach, named PolyRAG, follows a waterfall model for retrieval, starting from the top of the pyramid and progressing down until a confident answer is obtained. We introduce two benchmarks for domain-specific knowledge retrieval, one in the academic domain and the other in the financial domain. The effectiveness of the methods has been validated through comprehensive experiments by outperforming 19 SOTA methods. An encouraging observation is that the proposed method has augmented the GPT-4, providing 395\% F1 gain by improving its performance from 0.1636 to 0.8109.
Mean of Means: A 10-dollar Solution for Human Localization with Calibration-free and Unconstrained Camera Settings
Jul 30, 2024



Accurate human localization is crucial for various applications, especially in the Metaverse era. Existing high precision solutions rely on expensive, tag-dependent hardware, while vision-based methods offer a cheaper, tag-free alternative. However, current vision solutions based on stereo vision face limitations due to rigid perspective transformation principles and error propagation in multi-stage SVD solvers. These solutions also require multiple high-resolution cameras with strict setup constraints. To address these limitations, we propose a probabilistic approach that considers all points on the human body as observations generated by a distribution centered around the body's geometric center. This enables us to improve sampling significantly, increasing the number of samples for each point of interest from hundreds to billions. By modeling the relation between the means of the distributions of world coordinates and pixel coordinates, leveraging the Central Limit Theorem, we ensure normality and facilitate the learning process. Experimental results demonstrate human localization accuracy of 95% within a 0.3m range and nearly 100% accuracy within a 0.5m range, achieved at a low cost of only 10 USD using two web cameras with a resolution of 640x480 pixels.
Prior Knowledge Integration via LLM Encoding and Pseudo Event Regulation for Video Moment Retrieval
Jul 23, 2024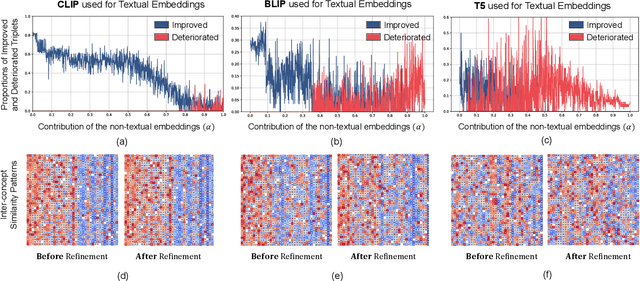
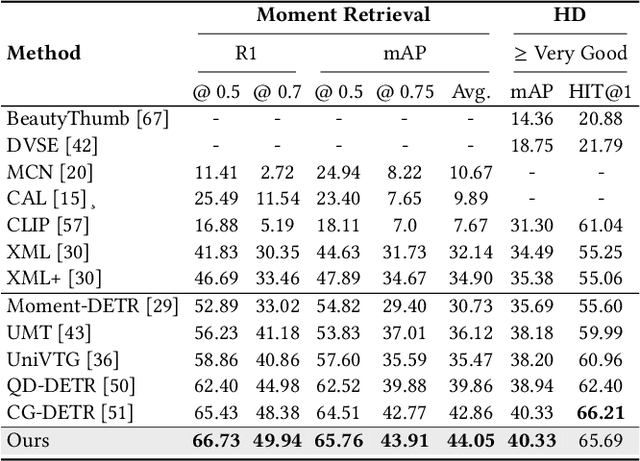
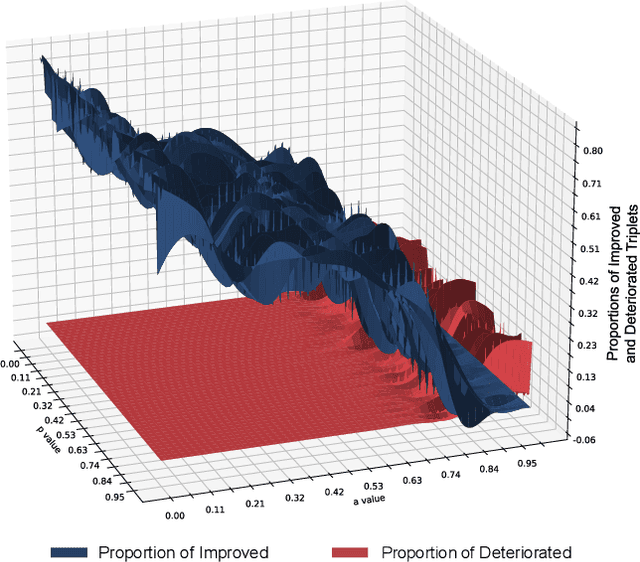
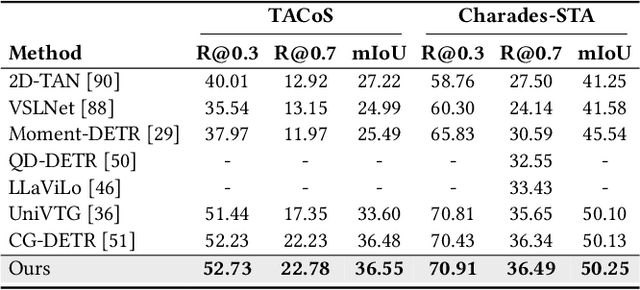
In this paper, we investigate the feasibility of leveraging large language models (LLMs) for integrating general knowledge and incorporating pseudo-events as priors for temporal content distribution in video moment retrieval (VMR) models. The motivation behind this study arises from the limitations of using LLMs as decoders for generating discrete textual descriptions, which hinders their direct application to continuous outputs like salience scores and inter-frame embeddings that capture inter-frame relations. To overcome these limitations, we propose utilizing LLM encoders instead of decoders. Through a feasibility study, we demonstrate that LLM encoders effectively refine inter-concept relations in multimodal embeddings, even without being trained on textual embeddings. We also show that the refinement capability of LLM encoders can be transferred to other embeddings, such as BLIP and T5, as long as these embeddings exhibit similar inter-concept similarity patterns to CLIP embeddings. We present a general framework for integrating LLM encoders into existing VMR architectures, specifically within the fusion module. Through experimental validation, we demonstrate the effectiveness of our proposed methods by achieving state-of-the-art performance in VMR. The source code can be accessed at https://github.com/fletcherjiang/LLMEPET.
A Survey on Personalized Content Synthesis with Diffusion Models
May 09, 2024Recent advancements in generative models have significantly impacted content creation, leading to the emergence of Personalized Content Synthesis (PCS). With a small set of user-provided examples, PCS aims to customize the subject of interest to specific user-defined prompts. Over the past two years, more than 150 methods have been proposed. However, existing surveys mainly focus on text-to-image generation, with few providing up-to-date summaries on PCS. This paper offers a comprehensive survey of PCS, with a particular focus on the diffusion models. Specifically, we introduce the generic frameworks of PCS research, which can be broadly classified into optimization-based and learning-based approaches. We further categorize and analyze these methodologies, discussing their strengths, limitations, and key techniques. Additionally, we delve into specialized tasks within the field, such as personalized object generation, face synthesis, and style personalization, highlighting their unique challenges and innovations. Despite encouraging progress, we also present an analysis of the challenges such as overfitting and the trade-off between subject fidelity and text alignment. Through this detailed overview and analysis, we propose future directions to advance the development of PCS.
Generative Active Learning for Image Synthesis Personalization
Mar 22, 2024This paper presents a pilot study that explores the application of active learning, traditionally studied in the context of discriminative models, to generative models. We specifically focus on image synthesis personalization tasks. The primary challenge in conducting active learning on generative models lies in the open-ended nature of querying, which differs from the closed form of querying in discriminative models that typically target a single concept. We introduce the concept of anchor directions to transform the querying process into a semi-open problem. We propose a direction-based uncertainty sampling strategy to enable generative active learning and tackle the exploitation-exploration dilemma. Extensive experiments are conducted to validate the effectiveness of our approach, demonstrating that an open-source model can achieve superior performance compared to closed-source models developed by large companies, such as Google's StyleDrop. The source code is available at https://github.com/zhangxulu1996/GAL4Personalization.
Indicative Image Retrieval: Turning Blackbox Learning into Grey
Jan 28, 2022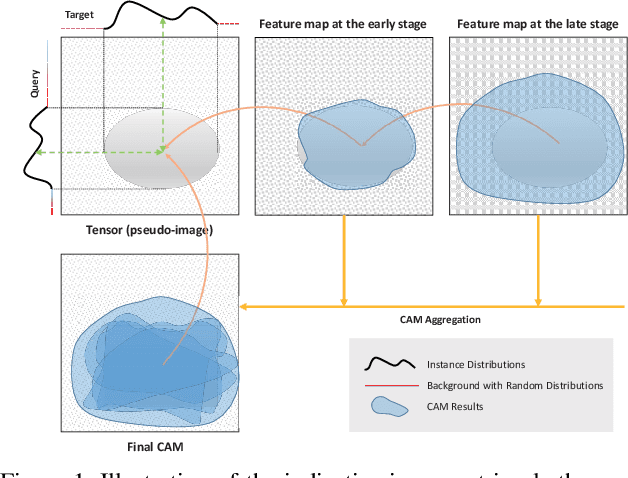



Deep learning became the game changer for image retrieval soon after it was introduced. It promotes the feature extraction (by representation learning) as the core of image retrieval, with the relevance/matching evaluation being degenerated into simple similarity metrics. In many applications, we need the matching evidence to be indicated rather than just have the ranked list (e.g., the locations of the target proteins/cells/lesions in medical images). It is like the matched words need to be highlighted in search engines. However, this is not easy to implement without explicit relevance/matching modeling. The deep representation learning models are not feasible because of their blackbox nature. In this paper, we revisit the importance of relevance/matching modeling in deep learning era with an indicative retrieval setting. The study shows that it is possible to skip the representation learning and model the matching evidence directly. By removing the dependency on the pre-trained models, it has avoided a lot of related issues (e.g., the domain gap between classification and retrieval, the detail-diffusion caused by convolution, and so on). More importantly, the study demonstrates that the matching can be explicitly modeled and backtracked later for generating the matching evidence indications. It can improve the explainability of deep inference. Our method obtains a best performance in literature on both Oxford-5k and Paris-6k, and sets a new record of 97.77% on Oxford-5k (97.81% on Paris-6k) without extracting any deep features.