 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASGO: Adaptive Structured Gradient Optimization
Paper and Code
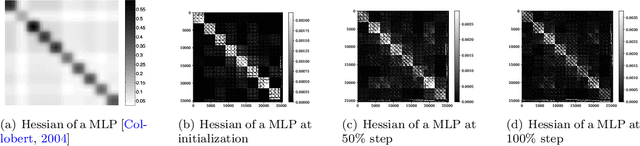

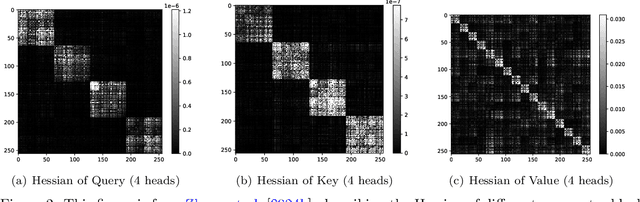
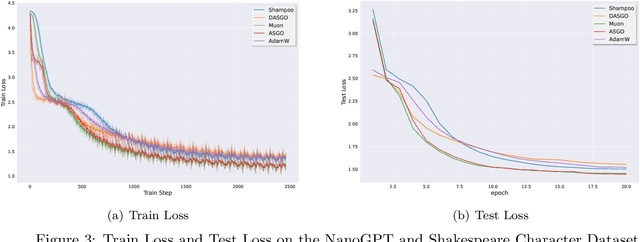
Training deep neural networks (DNNs) is a structured optimization problem, because the parameters are naturally represented by matrices and tensors rather than simple vectors. Under this structural representation, it has been widely observed that gradients are low-rank and Hessians are approximately block-wise diagonal. These structured properties are crucial for designing efficient optimization algorithms but may not be utilized by current popular optimizers like Adam. In this paper, we present a novel optimization algorithm ASGO that capitalizes on these properties by employing a preconditioner that is adaptively updated using structured gradients. By fine-grained theoretical analysis, ASGO is proven to achieve superior convergence rates compared to existing structured gradient methods. Based on the convergence theory, we further demonstrate that ASGO can benefit from the low-rank and block-wise diagonal properties. We also discuss practical modifications of ASGO and empirically verify the effectiveness of the algorithm on language model tasks.