 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGEMEL: Model Merging for Memory-Efficient, Real-Time Video Analytics at the Edge
Jan 19, 2022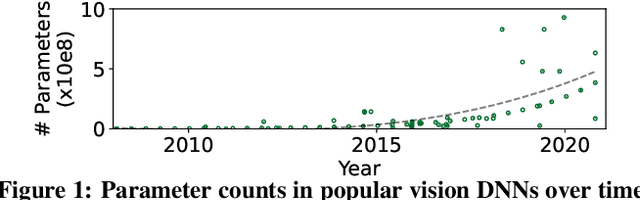
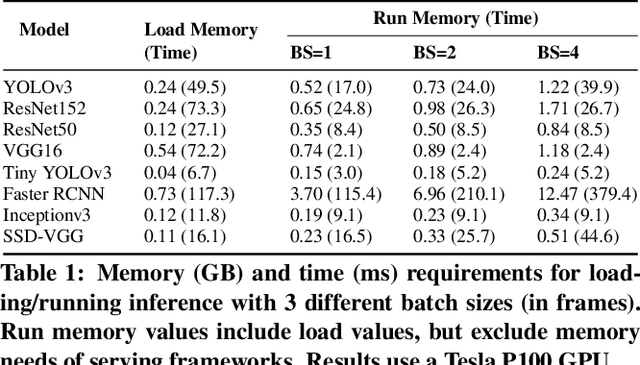
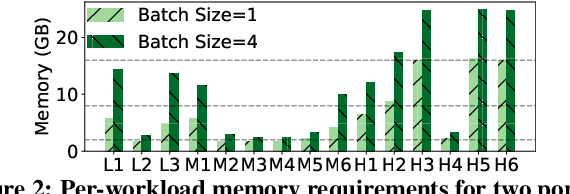

Video analytics pipelines have steadily shifted to edge deployments to reduce bandwidth overheads and privacy violations, but in doing so, face an ever-growing resource tension. Most notably, edge-box GPUs lack the memory needed to concurrently house the growing number of (increasingly complex) models for real-time inference. Unfortunately, existing solutions that rely on time/space sharing of GPU resources are insufficient as the required swapping delays result in unacceptable frame drops and accuracy violations. We present model merging, a new memory management technique that exploits architectural similarities between edge vision models by judiciously sharing their layers (including weights) to reduce workload memory costs and swapping delays. Our system, GEMEL, efficiently integrates merging into existing pipelines by (1) leveraging several guiding observations about per-model memory usage and inter-layer dependencies to quickly identify fruitful and accuracy-preserving merging configurations, and (2) altering edge inference schedules to maximize merging benefits. Experiments across diverse workloads reveal that GEMEL reduces memory usage by up to 60.7%, and improves overall accuracy by 8-39% relative to time/space sharing alone.
Boggart: Accelerating Retrospective Video Analytics via Model-Agnostic Ingest Processing
Jun 21, 2021



Delivering fast responses to retrospective queries on video datasets is difficult due to the large number of frames to consider and the high costs of running convolutional neural networks (CNNs) on each one. A natural solution is to perform a subset of the necessary computations ahead of time, as video is ingested. However, existing ingest-time systems require knowledge of the specific CNN that will be used in future queries -- a challenging requisite given the evergrowing space of CNN architectures and training datasets/methodologies. This paper presents Boggart, a retrospective video analytics system that delivers ingest-time speedups in a model-agnostic manner. Our underlying insight is that traditional computer vision (CV) algorithms are capable of performing computations that can be used to accelerate diverse queries with wide-ranging CNNs. Building on this, at ingest-time, Boggart carefully employs a variety of motion tracking algorithms to identify potential objects and their trajectories across frames. Then, at query-time, Boggart uses several novel techniques to collect the smallest sample of CNN results required to meet the target accuracy: (1) a clustering strategy to efficiently unearth the inevitable discrepancies between CV- and CNN-generated outputs, and (2) a set of accuracy-preserving propagation techniques to safely extend sampled results along each trajectory. Across many videos, CNNs, and queries Boggart consistently meets accuracy targets while using CNNs sparingly (on 3-54% of frames).