 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBamboo: Making Preemptible Instances Resilient for Affordable Training of Large DNNs
Apr 26, 2022


DNN models across many domains continue to grow in size, resulting in high resource requirements for effective training, and unpalatable (and often unaffordable) costs for organizations and research labs across scales. This paper aims to significantly reduce training costs with effective use of preemptible instances, i.e., those that can be obtained at a much cheaper price while idle, but may be preempted whenever requested by priority users. Doing so, however, requires new forms of resiliency and efficiency to cope with the possibility of frequent preemptions - a failure model that is drastically different from the occasional failures in normal cluster settings that existing checkpointing techniques target. We present Bamboo, a distributed system that tackles these challenges by introducing redundant computations into the training pipeline, i.e., whereby one node performs computations over not only its own layers but also over some layers in its neighbor. Our key insight is that training large models often requires pipeline parallelism where "pipeline bubbles" naturally exist. Bamboo carefully fills redundant computations into these bubbles, providing resilience at a low cost. Across a variety of widely used DNN models, Bamboo outperforms traditional checkpointing by 3.7x in training throughput, and reduces costs by 2.4x compared to a setting where on-demand instances are used.
GEMEL: Model Merging for Memory-Efficient, Real-Time Video Analytics at the Edge
Jan 19, 2022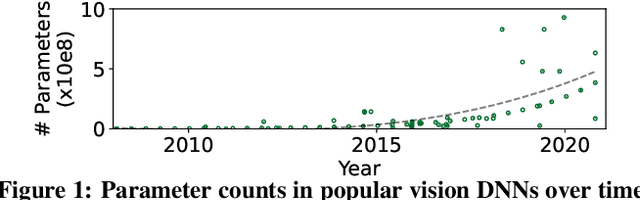
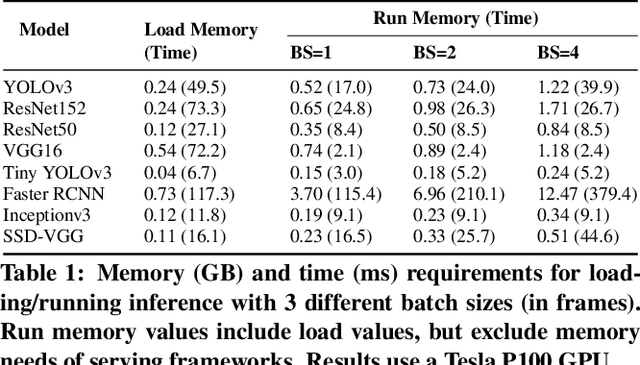
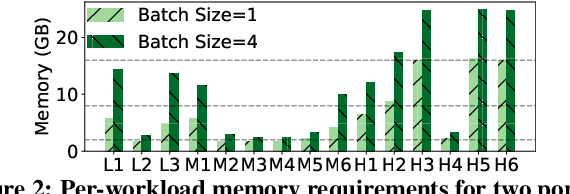

Video analytics pipelines have steadily shifted to edge deployments to reduce bandwidth overheads and privacy violations, but in doing so, face an ever-growing resource tension. Most notably, edge-box GPUs lack the memory needed to concurrently house the growing number of (increasingly complex) models for real-time inference. Unfortunately, existing solutions that rely on time/space sharing of GPU resources are insufficient as the required swapping delays result in unacceptable frame drops and accuracy violations. We present model merging, a new memory management technique that exploits architectural similarities between edge vision models by judiciously sharing their layers (including weights) to reduce workload memory costs and swapping delays. Our system, GEMEL, efficiently integrates merging into existing pipelines by (1) leveraging several guiding observations about per-model memory usage and inter-layer dependencies to quickly identify fruitful and accuracy-preserving merging configurations, and (2) altering edge inference schedules to maximize merging benefits. Experiments across diverse workloads reveal that GEMEL reduces memory usage by up to 60.7%, and improves overall accuracy by 8-39% relative to time/space sharing alone.
Dorylus: Affordable, Scalable, and Accurate GNN Training with Distributed CPU Servers and Serverless Threads
May 25, 2021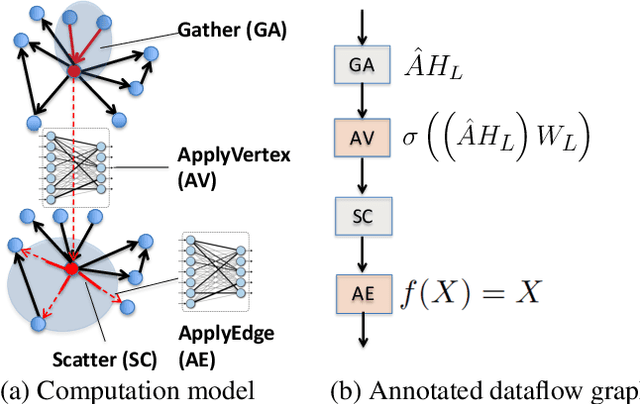

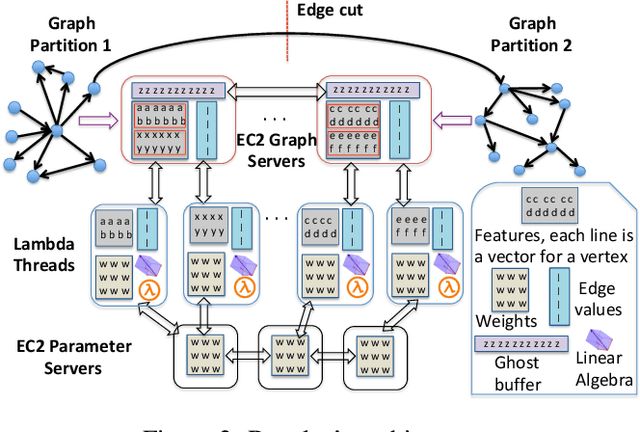

A graph neural network (GNN) enables deep learning on structured graph data. There are two major GNN training obstacles: 1) it relies on high-end servers with many GPUs which are expensive to purchase and maintain, and 2) limited memory on GPUs cannot scale to today's billion-edge graphs. This paper presents Dorylus: a distributed system for training GNNs. Uniquely, Dorylus can take advantage of serverless computing to increase scalability at a low cost. The key insight guiding our design is computation separation. Computation separation makes it possible to construct a deep, bounded-asynchronous pipeline where graph and tensor parallel tasks can fully overlap, effectively hiding the network latency incurred by Lambdas. With the help of thousands of Lambda threads, Dorylus scales GNN training to billion-edge graphs. Currently, for large graphs, CPU servers offer the best performance-per-dollar over GPU servers. Just using Lambdas on top of CPU servers offers up to 2.75x more performance-per-dollar than training only with CPU servers. Concretely, Dorylus is 1.22x faster and 4.83x cheaper than GPU servers for massive sparse graphs. Dorylus is up to 3.8x faster and 10.7x cheaper compared to existing sampling-based systems.