 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusedInf: Efficient Swapping of DNN Models for On-Demand Serverless Inference Services on the Edge
Oct 28, 2024Edge AI computing boxes are a new class of computing devices that are aimed to revolutionize the AI industry. These compact and robust hardware units bring the power of AI processing directly to the source of data--on the edge of the network. On the other hand, on-demand serverless inference services are becoming more and more popular as they minimize the infrastructural cost associated with hosting and running DNN models for small to medium-sized businesses. However, these computing devices are still constrained in terms of resource availability. As such, the service providers need to load and unload models efficiently in order to meet the growing demand. In this paper, we introduce FusedInf to efficiently swap DNN models for on-demand serverless inference services on the edge. FusedInf combines multiple models into a single Direct Acyclic Graph (DAG) to efficiently load the models into the GPU memory and make execution faster. Our evaluation of popular DNN models showed that creating a single DAG can make the execution of the models up to 14\% faster while reducing the memory requirement by up to 17\%. The prototype implementation is available at https://github.com/SifatTaj/FusedInf.
UnifiedNN: Efficient Neural Network Training on the Cloud
Aug 06, 2024Nowadays, cloud-based services are widely favored over the traditional approach of locally training a Neural Network (NN) model. Oftentimes, a cloud service processes multiple requests from users--thus training multiple NN models concurrently. However, training NN models concurrently is a challenging process, which typically requires significant amounts of available computing resources and takes a long time to complete. In this paper, we present UnifiedNN to effectively train multiple NN models concurrently on the cloud. UnifiedNN effectively "combines" multiple NN models and features several memory and time conservation mechanisms to train multiple NN models simultaneously without impacting the accuracy of the training process. Specifically, UnifiedNN merges multiple NN models and creates a large singular unified model in order to efficiently train all models at once. We have implemented a prototype of UnifiedNN in PyTorch and we have compared its performance with relevant state-of-the-art frameworks. Our experimental results demonstrate that UnifiedNN can reduce memory consumption by up to 53% and training time by up to 81% when compared with vanilla PyTorch without impacting the model training and testing accuracy. Finally, our results indicate that UnifiedNN can reduce memory consumption by up to 52% and training time by up to 41% when compared to state-of-the-art frameworks when training multiple models concurrently.
VQPy: An Object-Oriented Approach to Modern Video Analytics
Nov 03, 2023Video analytics is widely used in contemporary systems and services. At the forefront of video analytics are video queries that users develop to find objects of particular interest. Building upon the insight that video objects (e.g., human, animals, cars, etc.), the center of video analytics, are similar in spirit to objects modeled by traditional object-oriented languages, we propose to develop an object-oriented approach to video analytics. This approach, named VQPy, consists of a frontend$\unicode{x2015}$a Python variant with constructs that make it easy for users to express video objects and their interactions$\unicode{x2015}$as well as an extensible backend that can automatically construct and optimize pipelines based on video objects. We have implemented and open-sourced VQPy, which has been productized in Cisco as part of its DeepVision framework.
GEMEL: Model Merging for Memory-Efficient, Real-Time Video Analytics at the Edge
Jan 19, 2022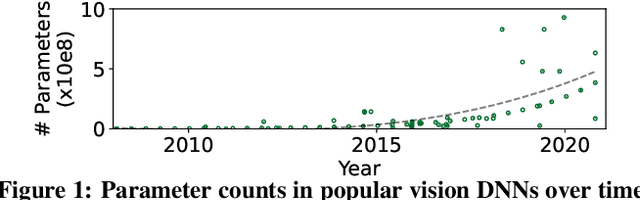
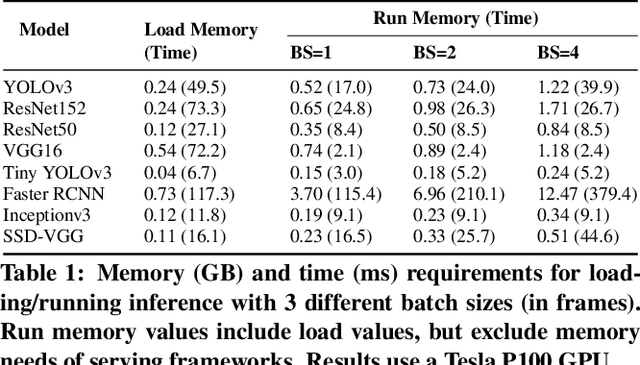
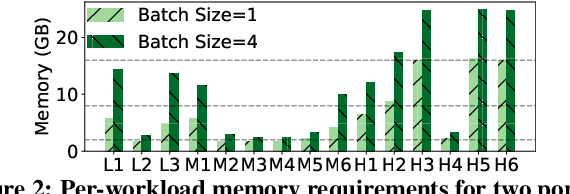

Video analytics pipelines have steadily shifted to edge deployments to reduce bandwidth overheads and privacy violations, but in doing so, face an ever-growing resource tension. Most notably, edge-box GPUs lack the memory needed to concurrently house the growing number of (increasingly complex) models for real-time inference. Unfortunately, existing solutions that rely on time/space sharing of GPU resources are insufficient as the required swapping delays result in unacceptable frame drops and accuracy violations. We present model merging, a new memory management technique that exploits architectural similarities between edge vision models by judiciously sharing their layers (including weights) to reduce workload memory costs and swapping delays. Our system, GEMEL, efficiently integrates merging into existing pipelines by (1) leveraging several guiding observations about per-model memory usage and inter-layer dependencies to quickly identify fruitful and accuracy-preserving merging configurations, and (2) altering edge inference schedules to maximize merging benefits. Experiments across diverse workloads reveal that GEMEL reduces memory usage by up to 60.7%, and improves overall accuracy by 8-39% relative to time/space sharing alone.