 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVQPy: An Object-Oriented Approach to Modern Video Analytics
Nov 03, 2023Video analytics is widely used in contemporary systems and services. At the forefront of video analytics are video queries that users develop to find objects of particular interest. Building upon the insight that video objects (e.g., human, animals, cars, etc.), the center of video analytics, are similar in spirit to objects modeled by traditional object-oriented languages, we propose to develop an object-oriented approach to video analytics. This approach, named VQPy, consists of a frontend$\unicode{x2015}$a Python variant with constructs that make it easy for users to express video objects and their interactions$\unicode{x2015}$as well as an extensible backend that can automatically construct and optimize pipelines based on video objects. We have implemented and open-sourced VQPy, which has been productized in Cisco as part of its DeepVision framework.
Deep Reinforcement Learning for Adaptive Learning Systems
Apr 17, 2020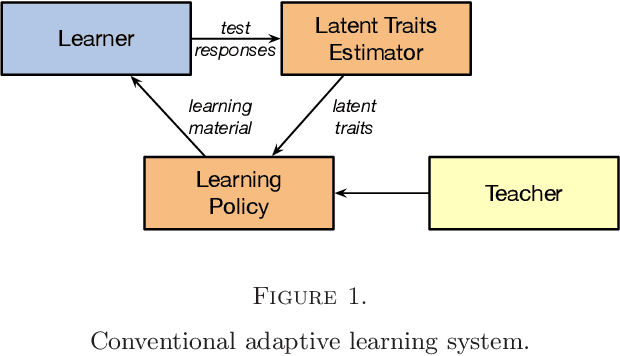
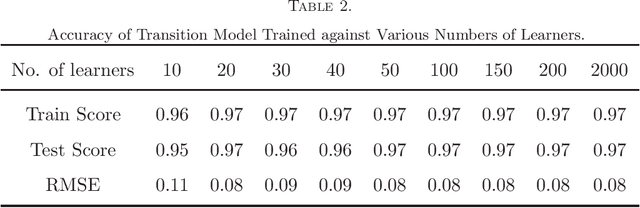
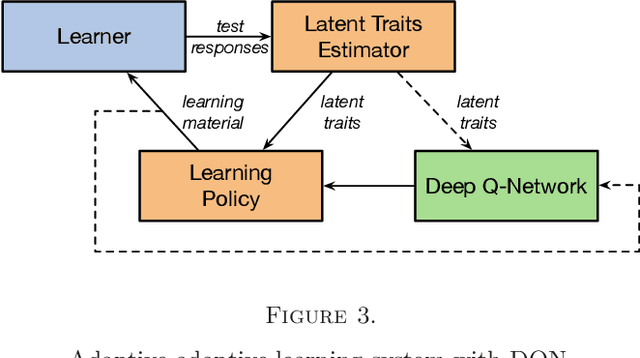
In this paper, we formulate the adaptive learning problem---the problem of how to find an individualized learning plan (called policy) that chooses the most appropriate learning materials based on learner's latent traits---faced in adaptive learning systems as a Markov decision process (MDP). We assume latent traits to be continuous with an unknown transition model. We apply a model-free deep reinforcement learning algorithm---the deep Q-learning algorithm---that can effectively find the optimal learning policy from data on learners' learning process without knowing the actual transition model of the learners' continuous latent traits. To efficiently utilize available data, we also develop a transition model estimator that emulates the learner's learning process using neural networks. The transition model estimator can be used in the deep Q-learning algorithm so that it can more efficiently discover the optimal learning policy for a learner. Numerical simulation studies verify that the proposed algorithm is very efficient in finding a good learning policy, especially with the aid of a transition model estimator, it can find the optimal learning policy after training using a small number of learners.
Arbitrage of Energy Storage in Electricity Markets with Deep Reinforcement Learning
May 04, 2019
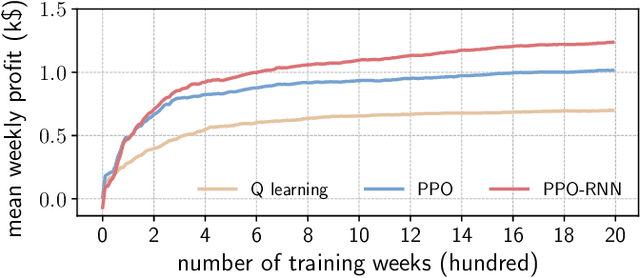
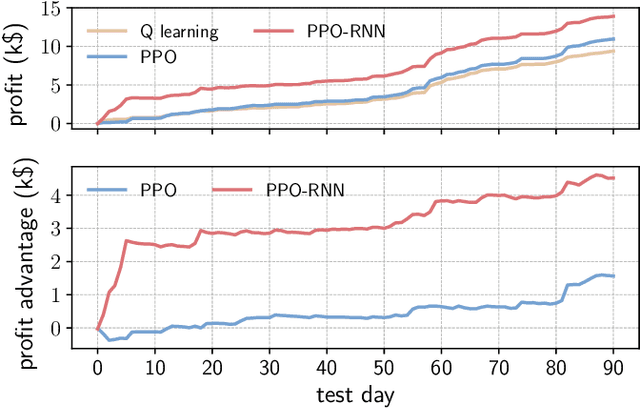
In this letter, we address the problem of controlling energy storage systems (ESSs) for arbitrage in real-time electricity markets under price uncertainty. We first formulate this problem as a Markov decision process, and then develop a deep reinforcement learning based algorithm to learn a stochastic control policy that maps a set of available information processed by a recurrent neural network to ESSs' charging/discharging actions. Finally, we verify the effectiveness of our algorithm using real-time electricity prices from PJM.
Learning Dynamical Demand Response Model in Real-Time Pricing Program
Dec 22, 2018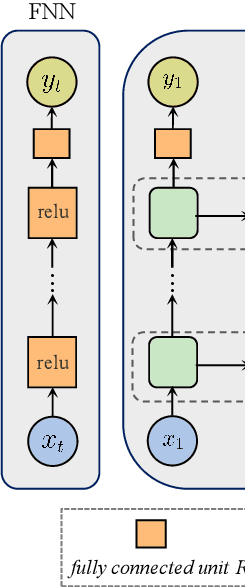
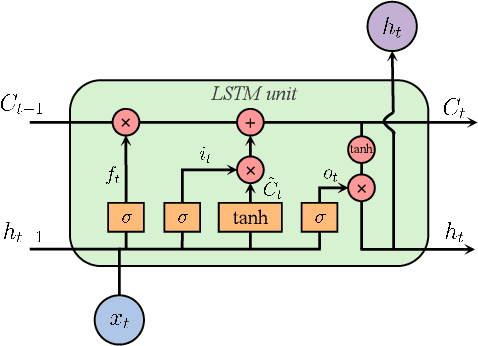
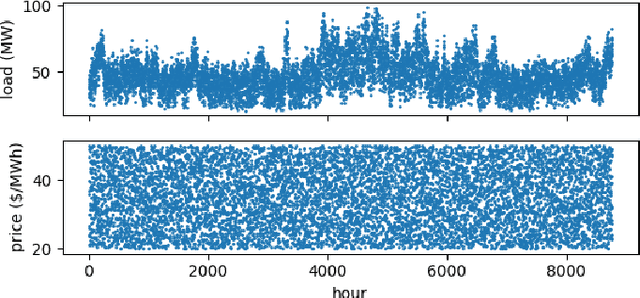
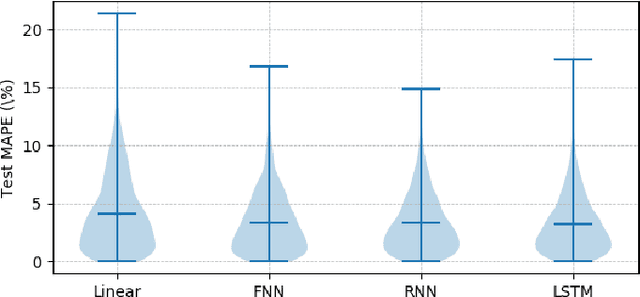
Price responsiveness is a major feature of end use customers (EUCs) that participate in demand response (DR) programs, and has been conventionally modeled with static demand functions, which take the electricity price as the input and the aggregate energy consumption as the output. This, however, neglects the inherent temporal correlation of the EUC behaviors, and may result in large errors when predicting the actual responses of EUCs in real-time pricing (RTP) programs. In this paper, we propose a dynamical DR model so as to capture the temporal behavior of the EUCs. The states in the proposed dynamical DR model can be explicitly chosen, in which case the model can be represented by a linear function or a multi-layer feedforward neural network, or implicitly chosen, in which case the model can be represented by a recurrent neural network or a long short-term memory unit network. In both cases, the dynamical DR model can be learned from historical price and energy consumption data. Numerical simulation illustrated how the states are chosen and also showed the proposed dynamical DR model significantly outperforms the static ones.
Optimal Hierarchical Learning Path Design with Reinforcement Learning
Oct 12, 2018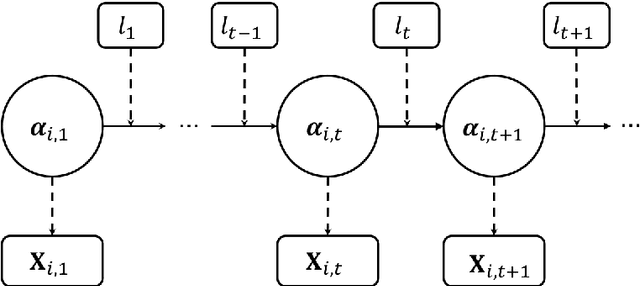
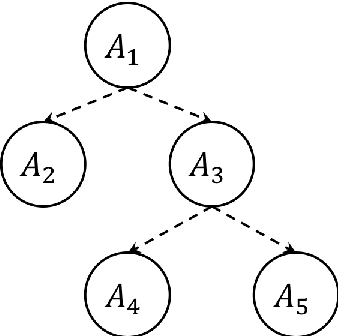

E-learning systems are capable of providing more adaptive and efficient learning experiences for students than the traditional classroom setting. A key component of such systems is the learning strategy, the algorithm that designs the learning paths for students based on information such as the students' current progresses, their skills, learning materials, and etc. In this paper, we address the problem of finding the optimal learning strategy for an E-learning system. To this end, we first develop a model for students' hierarchical skills in the E-learning system. Based on the hierarchical skill model and the classical cognitive diagnosis model, we further develop a framework to model various proficiency levels of hierarchical skills. The optimal learning strategy on top of the hierarchical structure is found by applying a model-free reinforcement learning method, which does not require information on students' learning transition process. The effectiveness of the proposed framework is demonstrated via numerical experiments.
Optimal Tap Setting of Voltage Regulation Transformers Using Batch Reinforcement Learning
Jul 29, 2018
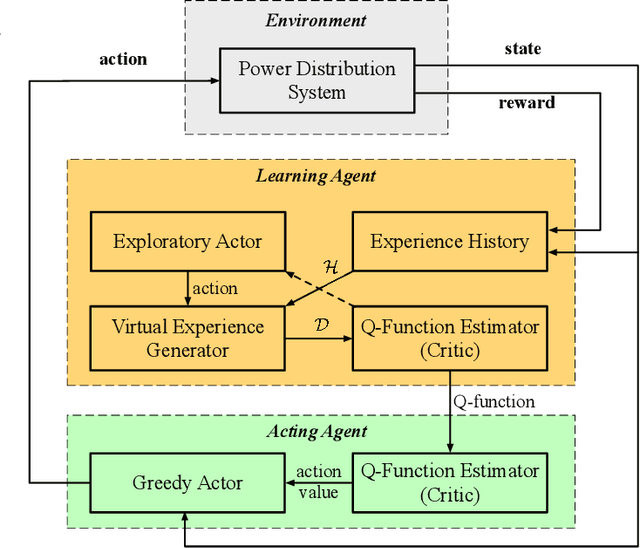

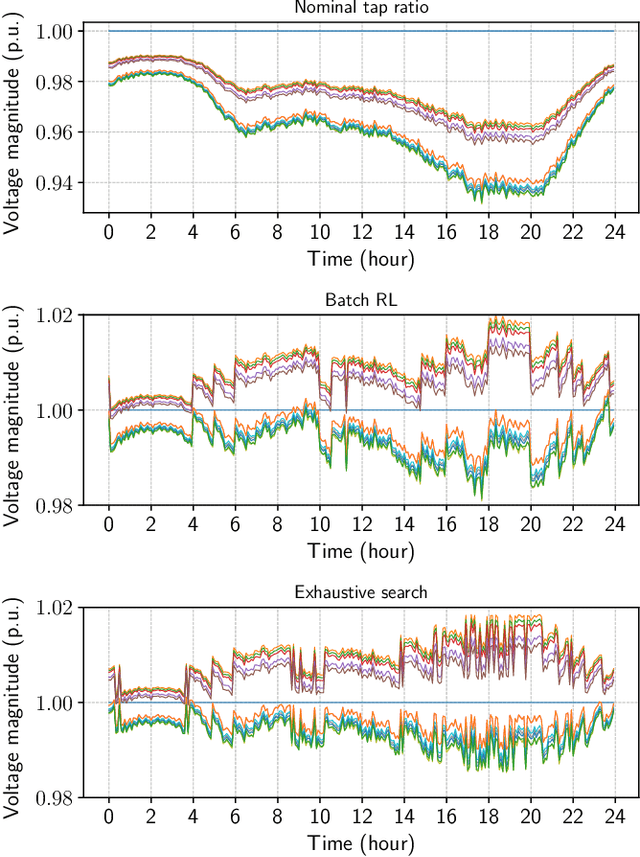
In this paper, we address the problem of setting the tap positions of voltage regulation transformers---also referred to as the load tap changers (LTCs)---in radial power distribution systems under uncertain load dynamics. The objective is to find a policy that can determine the optimal tap positions that minimize the voltage deviation across the system, based only on the voltage magnitude measurements and the topology information. To this end, we formulate this problem as a Markov decision process (MDP), and propose a batch reinforcement learning (RL) algorithm to solve it. By taking advantage of a linearized power flow model, we propose an effective algorithm to estimate the voltage magnitudes under different tap settings, which allows the RL algorithm to explore the state and action space freely offline without impacting the real power system. To circumvent the "curse of dimensionality" resulted from the large state and action space, we propose a least squares policy iteration based sequential learning algorithm to learn an action value function for each LTC, based on which the optimal tap positions can be directly determined. Numerical simulations on the IEEE 13-bus and 123-bus distribution test feeders validated the effectiveness of the proposed algorithm.