 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIPSM-Bench: A New Intermediate Phase Segmentation Benchmark in Microstructure Images of Zinc-Based Absorbable Biomaterials
Jun 09, 2026Zinc-based alloys are indispensable emerging absorbable metallic biomaterials, and their macroscopic performance is governed by microstructural characteristics. Intermediate phases-key microstructural constituents-are pivotal in regulating mechanical and functional properties. However, intermediate phase segmentation in zinc alloy microstructures faces formidable challenges: scarce annotated datasets, low contrast, difficulty detecting small targets, and heterogeneous morphologies. To this end, we construct IPSM-Bench, the largest high-quality dataset for zinc-alloy intermediate phase segmentation. Furthermore, we propose SCoP-SAM, a new Spatial Context Prior-guided SAM method that leverages the gradient structure and grayscale properties of intermediate phases to capture spatial context priors and incorporates them into the entire SAM encoding-decoding process, improving segmentation performance. Based on the proposed IPSM-Bench, we establish a new benchmark for intermediate phase segmentation to systematically evaluate state-of-the-art (SOTA) methods and advance research on zinc alloy microstructure analysis. Extensive experiments on IPSM-Bench and additional public alloy benchmarks demonstrate that our SCoP-SAM not only achieves SOTA performance for zinc-alloy intermediate phase segmentation but also generalizes remarkably well to other alloy scenarios.
WAT: Online Video Understanding Needs Watching Before Thinking
Mar 12, 2026Multimodal Large Language Models (MLLMs) have shown strong capabilities in image understanding, motivating recent efforts to extend them to video reasoning. However, existing Video LLMs struggle in online streaming scenarios, where long temporal context must be preserved under strict memory constraints. We propose WAT (Watching Before Thinking), a two-stage framework for online video reasoning. WAT separates processing into a query-independent watching stage and a query-triggered thinking stage. The watching stage builds a hierarchical memory system with a Short-Term Memory (STM) that buffers recent frames and a fixed-capacity Long-Term Memory (LTM) that maintains a diverse summary of historical content using a redundancy-aware eviction policy. In the thinking stage, a context-aware retrieval mechanism combines the query with the current STM context to retrieve relevant historical frames from the LTM for cross-temporal reasoning. To support training for online video tasks, we introduce WAT-85K, a dataset containing streaming-style annotations emphasizing real-time perception, backward tracing, and forecasting. Experiments show that WAT achieves state-of-the-art performance on online video benchmarks, including 77.7% accuracy on StreamingBench and 55.2% on OVO-Bench, outperforming existing open-source online Video LLMs while operating at real-time frame rates.
MARS2 2025 Challenge on Multimodal Reasoning: Datasets, Methods, Results, Discussion, and Outlook
Sep 17, 2025



This paper reviews the MARS2 2025 Challenge on Multimodal Reasoning. We aim to bring together different approaches in multimodal machine learning and LLMs via a large benchmark. We hope it better allows researchers to follow the state-of-the-art in this very dynamic area. Meanwhile, a growing number of testbeds have boosted the evolution of general-purpose large language models. Thus, this year's MARS2 focuses on real-world and specialized scenarios to broaden the multimodal reasoning applications of MLLMs. Our organizing team released two tailored datasets Lens and AdsQA as test sets, which support general reasoning in 12 daily scenarios and domain-specific reasoning in advertisement videos, respectively. We evaluated 40+ baselines that include both generalist MLLMs and task-specific models, and opened up three competition tracks, i.e., Visual Grounding in Real-world Scenarios (VG-RS), Visual Question Answering with Spatial Awareness (VQA-SA), and Visual Reasoning in Creative Advertisement Videos (VR-Ads). Finally, 76 teams from the renowned academic and industrial institutions have registered and 40+ valid submissions (out of 1200+) have been included in our ranking lists. Our datasets, code sets (40+ baselines and 15+ participants' methods), and rankings are publicly available on the MARS2 workshop website and our GitHub organization page https://github.com/mars2workshop/, where our updates and announcements of upcoming events will be continuously provided.
SIM-Trans: Structure Information Modeling Transformer for Fine-grained Visual Categorization
Aug 31, 2022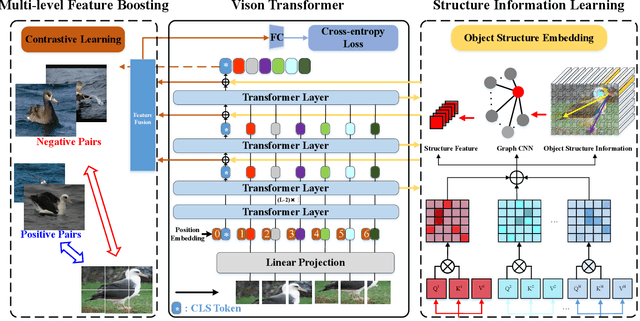

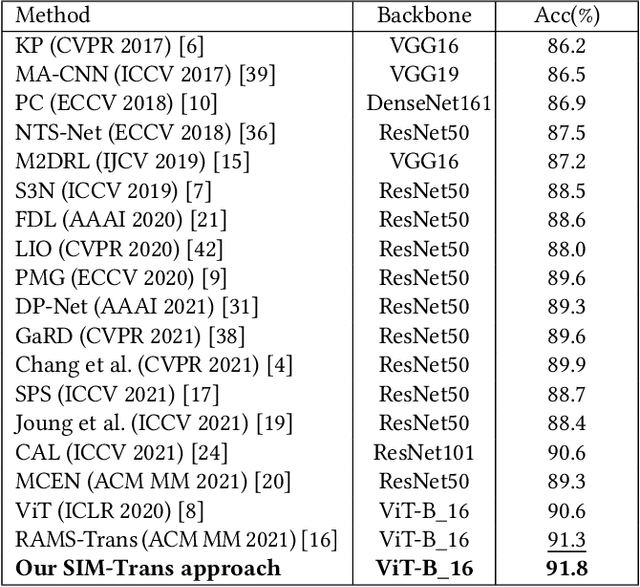
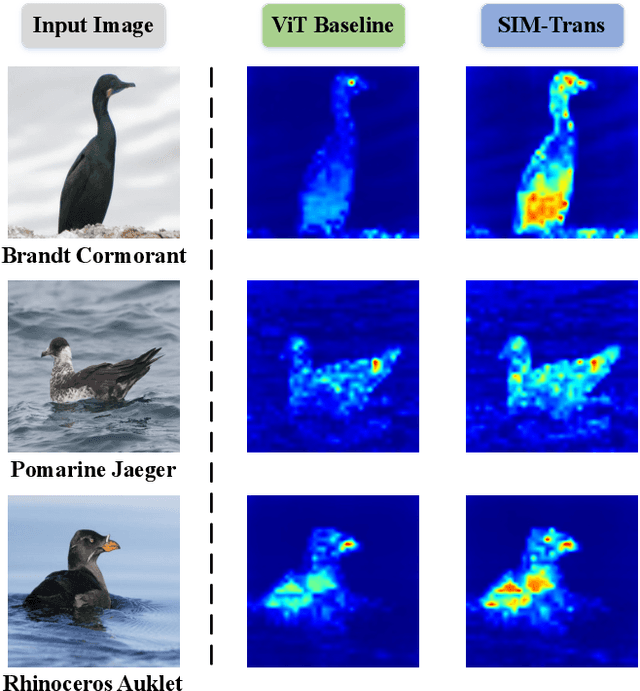
Fine-grained visual categorization (FGVC) aims at recognizing objects from similar subordinate categories, which is challenging and practical for human's accurate automatic recognition needs. Most FGVC approaches focus on the attention mechanism research for discriminative regions mining while neglecting their interdependencies and composed holistic object structure, which are essential for model's discriminative information localization and understanding ability. To address the above limitations, we propose the Structure Information Modeling Transformer (SIM-Trans) to incorporate object structure information into transformer for enhancing discriminative representation learning to contain both the appearance information and structure information. Specifically, we encode the image into a sequence of patch tokens and build a strong vision transformer framework with two well-designed modules: (i) the structure information learning (SIL) module is proposed to mine the spatial context relation of significant patches within the object extent with the help of the transformer's self-attention weights, which is further injected into the model for importing structure information; (ii) the multi-level feature boosting (MFB) module is introduced to exploit the complementary of multi-level features and contrastive learning among classes to enhance feature robustness for accurate recognition. The proposed two modules are light-weighted and can be plugged into any transformer network and trained end-to-end easily, which only depends on the attention weights that come with the vision transformer itself. Extensive experiments and analyses demonstrate that the proposed SIM-Trans achieves state-of-the-art performance on fine-grained visual categorization benchmarks. The code is available at https://github.com/PKU-ICST-MIPL/SIM-Trans_ACMMM2022.
Learning Dynamical Demand Response Model in Real-Time Pricing Program
Dec 22, 2018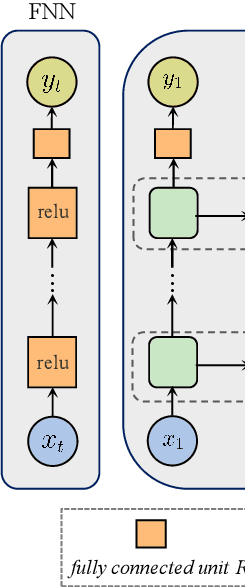
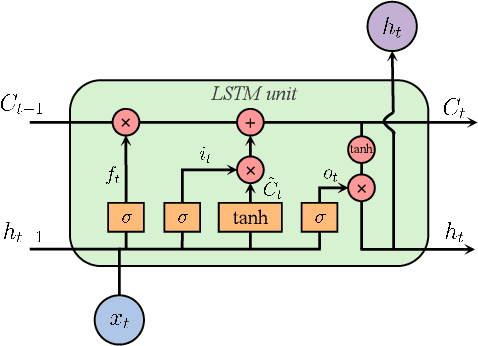
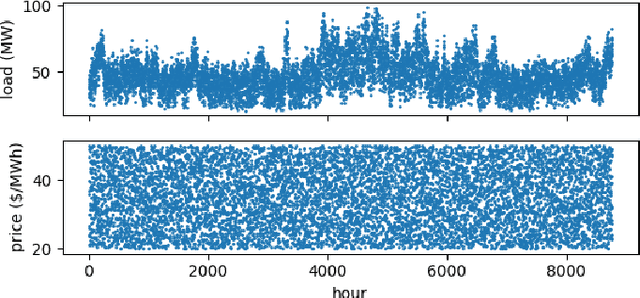
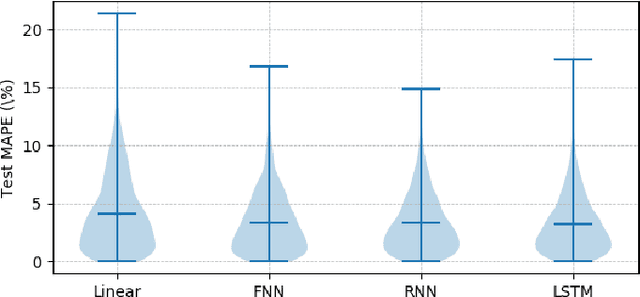
Price responsiveness is a major feature of end use customers (EUCs) that participate in demand response (DR) programs, and has been conventionally modeled with static demand functions, which take the electricity price as the input and the aggregate energy consumption as the output. This, however, neglects the inherent temporal correlation of the EUC behaviors, and may result in large errors when predicting the actual responses of EUCs in real-time pricing (RTP) programs. In this paper, we propose a dynamical DR model so as to capture the temporal behavior of the EUCs. The states in the proposed dynamical DR model can be explicitly chosen, in which case the model can be represented by a linear function or a multi-layer feedforward neural network, or implicitly chosen, in which case the model can be represented by a recurrent neural network or a long short-term memory unit network. In both cases, the dynamical DR model can be learned from historical price and energy consumption data. Numerical simulation illustrated how the states are chosen and also showed the proposed dynamical DR model significantly outperforms the static ones.
3D Textured Model Encryption via 3D Lu Chaotic Mapping
Sep 25, 2017
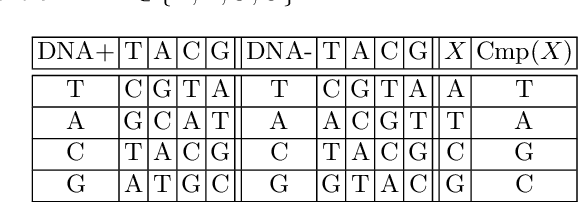
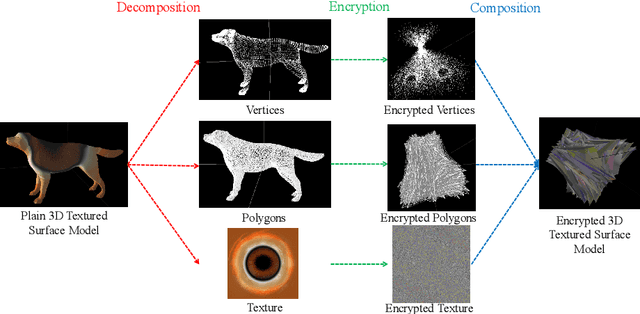
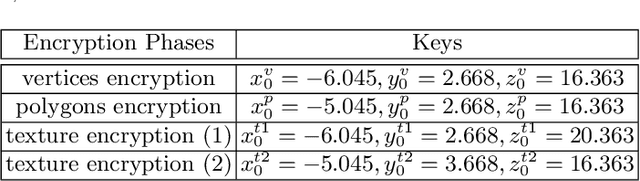
In the coming Virtual/Augmented Reality (VR/AR) era, 3D contents will be popularized just as images and videos today. The security and privacy of these 3D contents should be taken into consideration. 3D contents contain surface models and solid models. The surface models include point clouds, meshes and textured models. Previous work mainly focus on encryption of solid models, point clouds and meshes. This work focuses on the most complicated 3D textured model. We propose a 3D Lu chaotic mapping based encryption method of 3D textured model. We encrypt the vertexes, the polygons and the textures of 3D models separately using the 3D Lu chaotic mapping. Then the encrypted vertices, edges and texture maps are composited together to form the final encrypted 3D textured model. The experimental results reveal that our method can encrypt and decrypt 3D textured models correctly. In addition, our method can resistant several attacks such as brute-force attack and statistic attack.