 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning for Adaptive Learning Systems
Apr 17, 2020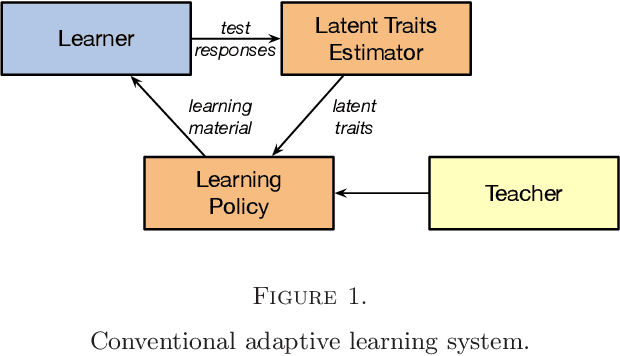
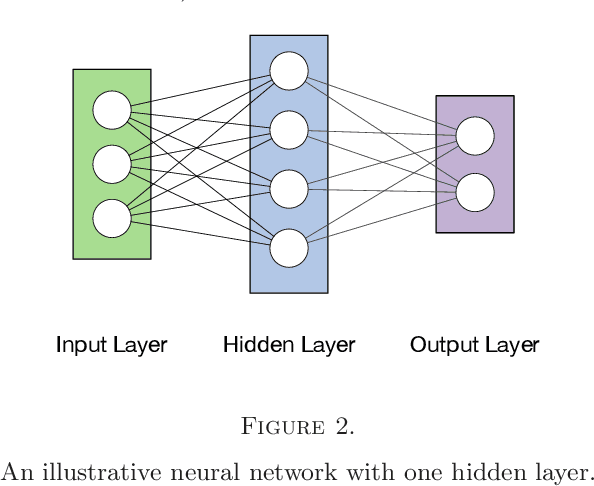
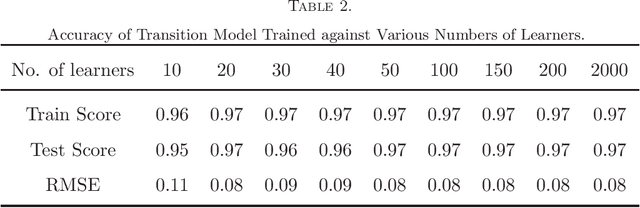
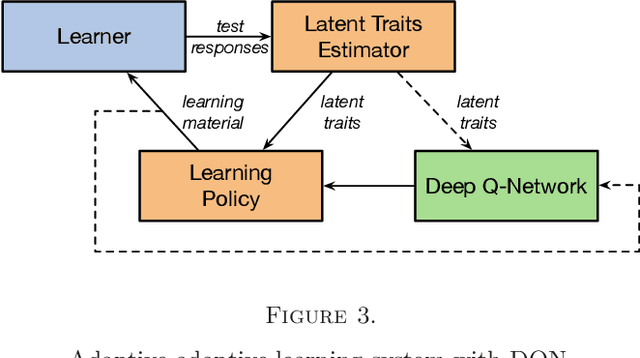
In this paper, we formulate the adaptive learning problem---the problem of how to find an individualized learning plan (called policy) that chooses the most appropriate learning materials based on learner's latent traits---faced in adaptive learning systems as a Markov decision process (MDP). We assume latent traits to be continuous with an unknown transition model. We apply a model-free deep reinforcement learning algorithm---the deep Q-learning algorithm---that can effectively find the optimal learning policy from data on learners' learning process without knowing the actual transition model of the learners' continuous latent traits. To efficiently utilize available data, we also develop a transition model estimator that emulates the learner's learning process using neural networks. The transition model estimator can be used in the deep Q-learning algorithm so that it can more efficiently discover the optimal learning policy for a learner. Numerical simulation studies verify that the proposed algorithm is very efficient in finding a good learning policy, especially with the aid of a transition model estimator, it can find the optimal learning policy after training using a small number of learners.
Optimal Hierarchical Learning Path Design with Reinforcement Learning
Oct 12, 2018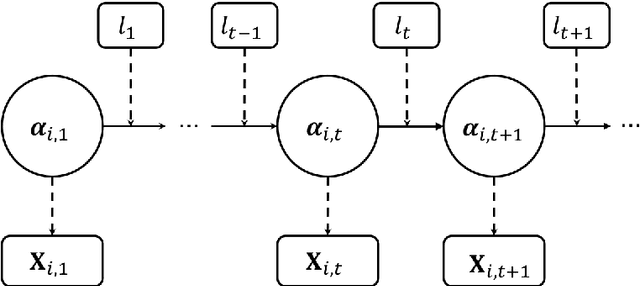
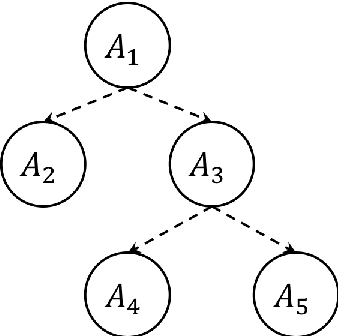

E-learning systems are capable of providing more adaptive and efficient learning experiences for students than the traditional classroom setting. A key component of such systems is the learning strategy, the algorithm that designs the learning paths for students based on information such as the students' current progresses, their skills, learning materials, and etc. In this paper, we address the problem of finding the optimal learning strategy for an E-learning system. To this end, we first develop a model for students' hierarchical skills in the E-learning system. Based on the hierarchical skill model and the classical cognitive diagnosis model, we further develop a framework to model various proficiency levels of hierarchical skills. The optimal learning strategy on top of the hierarchical structure is found by applying a model-free reinforcement learning method, which does not require information on students' learning transition process. The effectiveness of the proposed framework is demonstrated via numerical experiments.