 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusedInf: Efficient Swapping of DNN Models for On-Demand Serverless Inference Services on the Edge
Oct 28, 2024Edge AI computing boxes are a new class of computing devices that are aimed to revolutionize the AI industry. These compact and robust hardware units bring the power of AI processing directly to the source of data--on the edge of the network. On the other hand, on-demand serverless inference services are becoming more and more popular as they minimize the infrastructural cost associated with hosting and running DNN models for small to medium-sized businesses. However, these computing devices are still constrained in terms of resource availability. As such, the service providers need to load and unload models efficiently in order to meet the growing demand. In this paper, we introduce FusedInf to efficiently swap DNN models for on-demand serverless inference services on the edge. FusedInf combines multiple models into a single Direct Acyclic Graph (DAG) to efficiently load the models into the GPU memory and make execution faster. Our evaluation of popular DNN models showed that creating a single DAG can make the execution of the models up to 14\% faster while reducing the memory requirement by up to 17\%. The prototype implementation is available at https://github.com/SifatTaj/FusedInf.
UnifiedNN: Efficient Neural Network Training on the Cloud
Aug 06, 2024Nowadays, cloud-based services are widely favored over the traditional approach of locally training a Neural Network (NN) model. Oftentimes, a cloud service processes multiple requests from users--thus training multiple NN models concurrently. However, training NN models concurrently is a challenging process, which typically requires significant amounts of available computing resources and takes a long time to complete. In this paper, we present UnifiedNN to effectively train multiple NN models concurrently on the cloud. UnifiedNN effectively "combines" multiple NN models and features several memory and time conservation mechanisms to train multiple NN models simultaneously without impacting the accuracy of the training process. Specifically, UnifiedNN merges multiple NN models and creates a large singular unified model in order to efficiently train all models at once. We have implemented a prototype of UnifiedNN in PyTorch and we have compared its performance with relevant state-of-the-art frameworks. Our experimental results demonstrate that UnifiedNN can reduce memory consumption by up to 53% and training time by up to 81% when compared with vanilla PyTorch without impacting the model training and testing accuracy. Finally, our results indicate that UnifiedNN can reduce memory consumption by up to 52% and training time by up to 41% when compared to state-of-the-art frameworks when training multiple models concurrently.
Amalgam: A Framework for Obfuscated Neural Network Training on the Cloud
Jun 02, 2024



Training a proprietary Neural Network (NN) model with a proprietary dataset on the cloud comes at the risk of exposing the model architecture and the dataset to the cloud service provider. To tackle this problem, in this paper, we present an NN obfuscation framework, called Amalgam, to train NN models in a privacy-preserving manner in existing cloud-based environments. Amalgam achieves that by augmenting NN models and the datasets to be used for training with well-calibrated noise to "hide" both the original model architectures and training datasets from the cloud. After training, Amalgam extracts the original models from the augmented models and returns them to users. Our evaluation results with different computer vision and natural language processing models and datasets demonstrate that Amalgam: (i) introduces modest overheads into the training process without impacting its correctness, and (ii) does not affect the model's accuracy.
Gem5Pred: Predictive Approaches For Gem5 Simulation Time
Oct 10, 2023Gem5, an open-source, flexible, and cost-effective simulator, is widely recognized and utilized in both academic and industry fields for hardware simulation. However, the typically time-consuming nature of simulating programs on Gem5 underscores the need for a predictive model that can estimate simulation time. As of now, no such dataset or model exists. In response to this gap, this paper makes a novel contribution by introducing a unique dataset specifically created for this purpose. We also conducted analysis of the effects of different instruction types on the simulation time in Gem5. After this, we employ three distinct models leveraging CodeBERT to execute the prediction task based on the developed dataset. Our superior regression model achieves a Mean Absolute Error (MAE) of 0.546, while our top-performing classification model records an Accuracy of 0.696. Our models establish a foundation for future investigations on this topic, serving as benchmarks against which subsequent models can be compared. We hope that our contribution can simulate further research in this field. The dataset we used is available at https://github.com/XueyangLiOSU/Gem5Pred.
Rethinking Internet Communication Through LLMs: How Close Are We?
Sep 25, 2023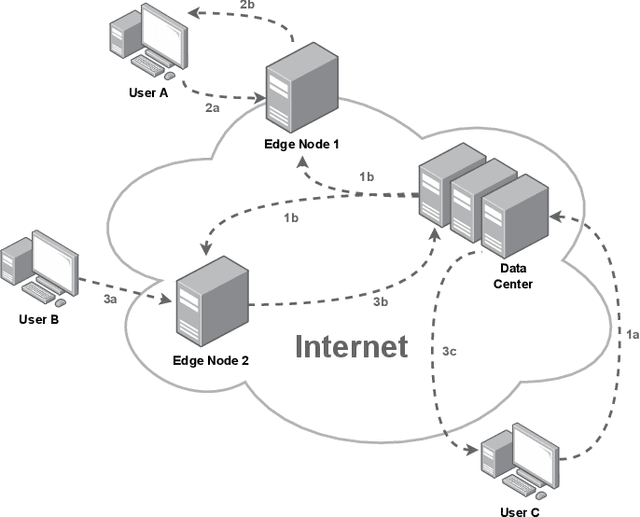
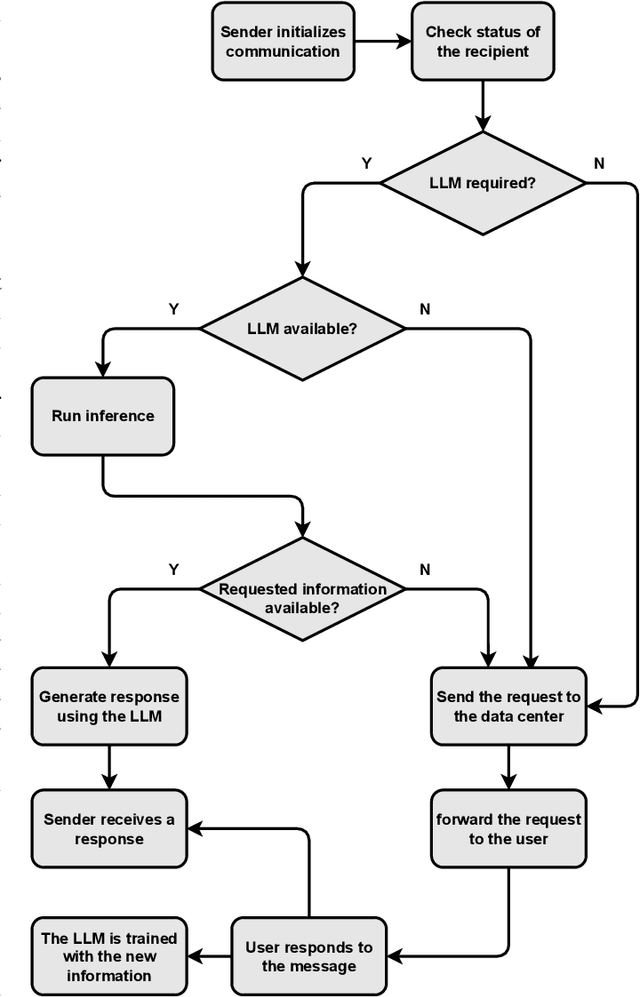
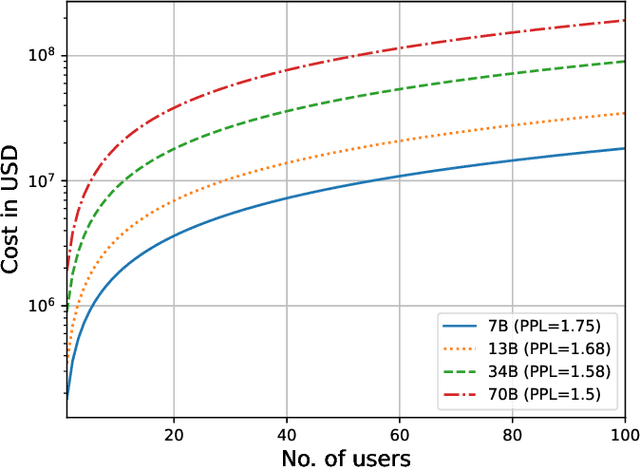

In this paper, we rethink the way that communication among users over the Internet, one of the fundamental outcomes of the Internet evolution, takes place. Instead of users communicating directly over the Internet, we explore an architecture that enables users to communicate with (query) Large Language Models (LLMs) that capture the cognition of users on the other end of the communication channel. We present an architecture to achieve such LLM-based communication and we perform a reality check to assess how close we are today to realizing such a communication architecture from a technical point of view. Finally, we discuss several research challenges and identify interesting directions for future research.