 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBamboo: Making Preemptible Instances Resilient for Affordable Training of Large DNNs
Paper and Code
Apr 26, 2022
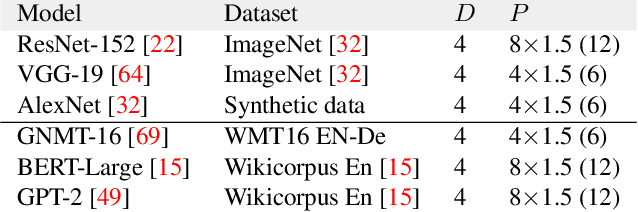


DNN models across many domains continue to grow in size, resulting in high resource requirements for effective training, and unpalatable (and often unaffordable) costs for organizations and research labs across scales. This paper aims to significantly reduce training costs with effective use of preemptible instances, i.e., those that can be obtained at a much cheaper price while idle, but may be preempted whenever requested by priority users. Doing so, however, requires new forms of resiliency and efficiency to cope with the possibility of frequent preemptions - a failure model that is drastically different from the occasional failures in normal cluster settings that existing checkpointing techniques target. We present Bamboo, a distributed system that tackles these challenges by introducing redundant computations into the training pipeline, i.e., whereby one node performs computations over not only its own layers but also over some layers in its neighbor. Our key insight is that training large models often requires pipeline parallelism where "pipeline bubbles" naturally exist. Bamboo carefully fills redundant computations into these bubbles, providing resilience at a low cost. Across a variety of widely used DNN models, Bamboo outperforms traditional checkpointing by 3.7x in training throughput, and reduces costs by 2.4x compared to a setting where on-demand instances are used.