 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Dorylus: Affordable, Scalable, and Accurate GNN Training with Distributed CPU Servers and Serverless Threads
May 25, 2021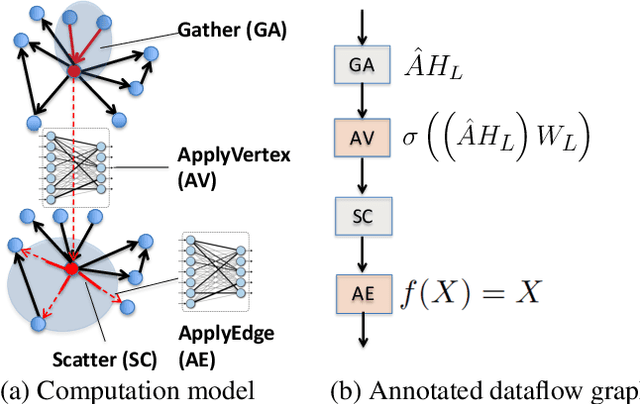

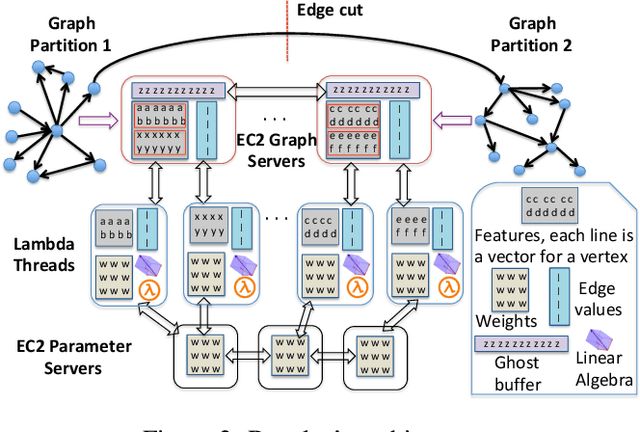

A graph neural network (GNN) enables deep learning on structured graph data. There are two major GNN training obstacles: 1) it relies on high-end servers with many GPUs which are expensive to purchase and maintain, and 2) limited memory on GPUs cannot scale to today's billion-edge graphs. This paper presents Dorylus: a distributed system for training GNNs. Uniquely, Dorylus can take advantage of serverless computing to increase scalability at a low cost. The key insight guiding our design is computation separation. Computation separation makes it possible to construct a deep, bounded-asynchronous pipeline where graph and tensor parallel tasks can fully overlap, effectively hiding the network latency incurred by Lambdas. With the help of thousands of Lambda threads, Dorylus scales GNN training to billion-edge graphs. Currently, for large graphs, CPU servers offer the best performance-per-dollar over GPU servers. Just using Lambdas on top of CPU servers offers up to 2.75x more performance-per-dollar than training only with CPU servers. Concretely, Dorylus is 1.22x faster and 4.83x cheaper than GPU servers for massive sparse graphs. Dorylus is up to 3.8x faster and 10.7x cheaper compared to existing sampling-based systems.
Priority-based Parameter Propagation for Distributed DNN Training
May 10, 2019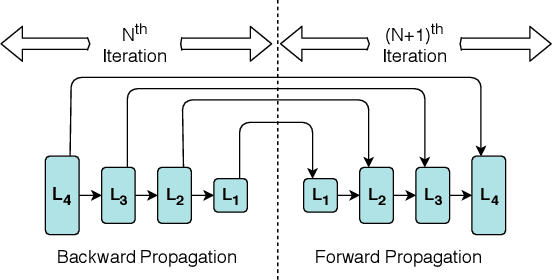
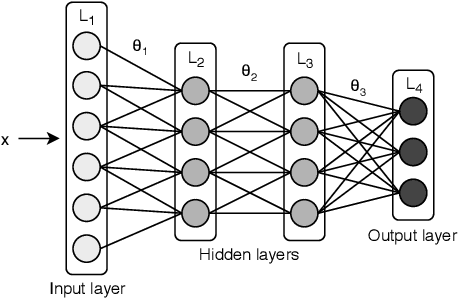
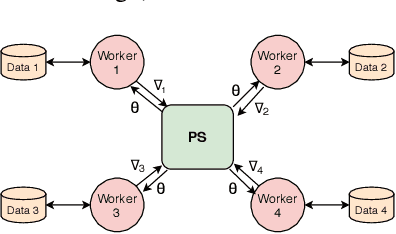
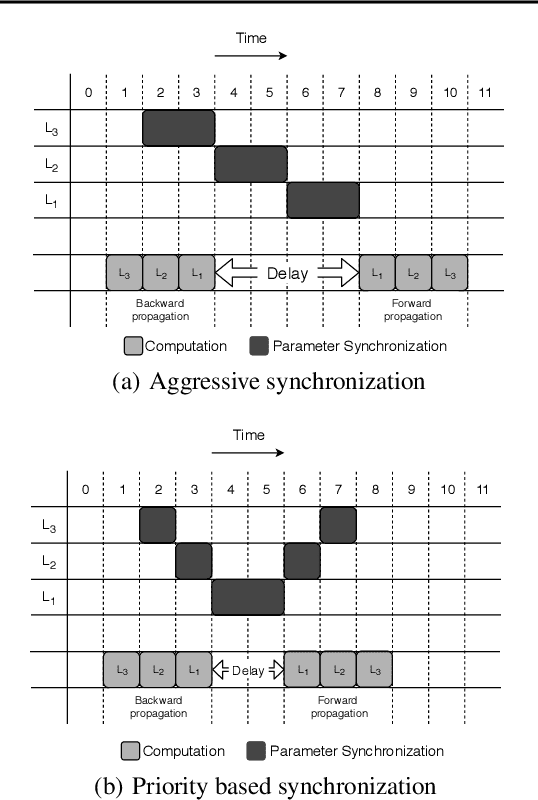
Data parallel training is widely used for scaling distributed deep neural network (DNN) training. However, the performance benefits are often limited by the communication-heavy parameter synchronization step. In this paper, we take advantage of the domain specific knowledge of DNN training and overlap parameter synchronization with computation in order to improve the training performance. We make two key observations: (1) the optimal data representation granularity for the communication may differ from that used by the underlying DNN model implementation and (2) different parameters can afford different synchronization delays. Based on these observations, we propose a new synchronization mechanism called Priority-based Parameter Propagation (P3). P3 synchronizes parameters at a finer granularity and schedules data transmission in such a way that the training process incurs minimal communication delay. We show that P3 can improve the training throughput of ResNet-50, Sockeye and VGG-19 by as much as 25%, 38% and 66% respectively on clusters with realistic network bandwidth
Poseidon: An Efficient Communication Architecture for Distributed Deep Learning on GPU Clusters
Jun 11, 2017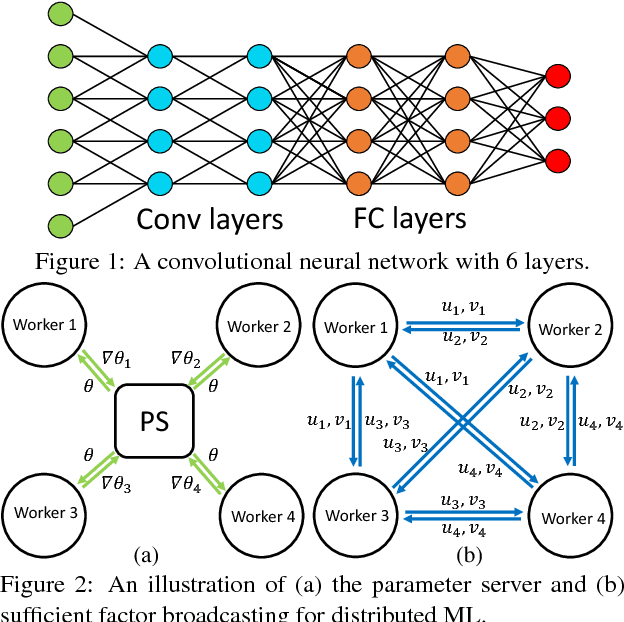
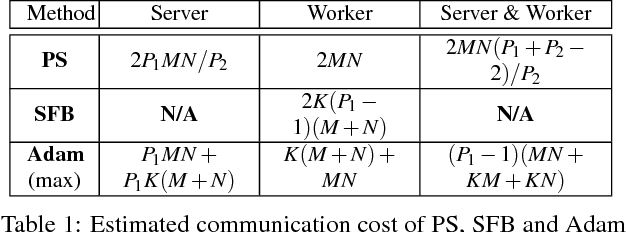
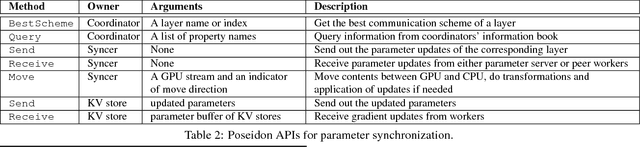
Deep learning models can take weeks to train on a single GPU-equipped machine, necessitating scaling out DL training to a GPU-cluster. However, current distributed DL implementations can scale poorly due to substantial parameter synchronization over the network, because the high throughput of GPUs allows more data batches to be processed per unit time than CPUs, leading to more frequent network synchronization. We present Poseidon, an efficient communication architecture for distributed DL on GPUs. Poseidon exploits the layered model structures in DL programs to overlap communication and computation, reducing bursty network communication. Moreover, Poseidon uses a hybrid communication scheme that optimizes the number of bytes required to synchronize each layer, according to layer properties and the number of machines. We show that Poseidon is applicable to different DL frameworks by plugging Poseidon into Caffe and TensorFlow. We show that Poseidon enables Caffe and TensorFlow to achieve 15.5x speed-up on 16 single-GPU machines, even with limited bandwidth (10GbE) and the challenging VGG19-22K network for image classification. Moreover, Poseidon-enabled TensorFlow achieves 31.5x speed-up with 32 single-GPU machines on Inception-V3, a 50% improvement over the open-source TensorFlow (20x speed-up).
Poseidon: A System Architecture for Efficient GPU-based Deep Learning on Multiple Machines
Dec 19, 2015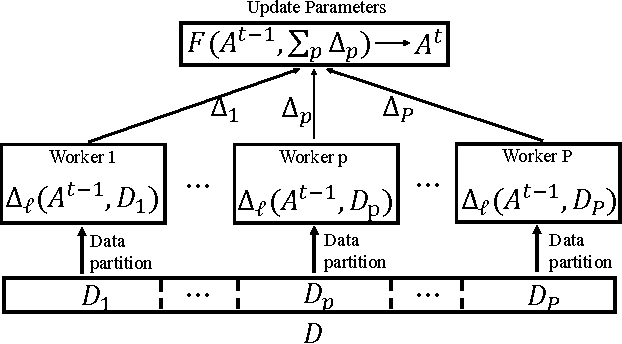
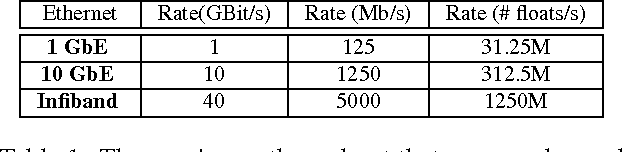

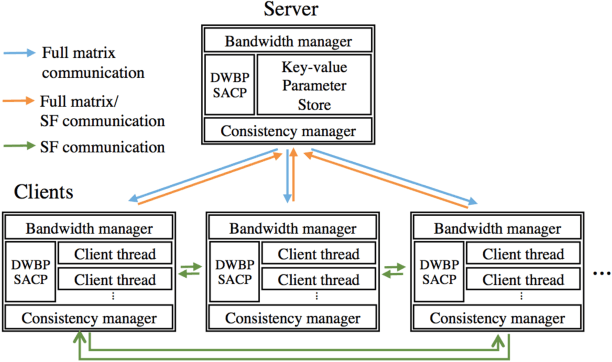
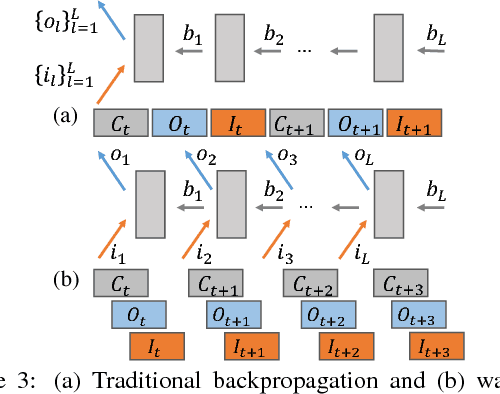
Deep learning (DL) has achieved notable successes in many machine learning tasks. A number of frameworks have been developed to expedite the process of designing and training deep neural networks (DNNs), such as Caffe, Torch and Theano. Currently they can harness multiple GPUs on a single machine, but are unable to use GPUs that are distributed across multiple machines; as even average-sized DNNs can take days to train on a single GPU with 100s of GBs to TBs of data, distributed GPUs present a prime opportunity for scaling up DL. However, the limited bandwidth available on commodity Ethernet networks presents a bottleneck to distributed GPU training, and prevents its trivial realization. To investigate how to adapt existing frameworks to efficiently support distributed GPUs, we propose Poseidon, a scalable system architecture for distributed inter-machine communication in existing DL frameworks. We integrate Poseidon with Caffe and evaluate its performance at training DNNs for object recognition. Poseidon features three key contributions that accelerate DNN training on clusters: (1) a three-level hybrid architecture that allows Poseidon to support both CPU-only and GPU-equipped clusters, (2) a distributed wait-free backpropagation (DWBP) algorithm to improve GPU utilization and to balance communication, and (3) a structure-aware communication protocol (SACP) to minimize communication overheads. We empirically show that Poseidon converges to same objectives as a single machine, and achieves state-of-art training speedup across multiple models and well-established datasets using a commodity GPU cluster of 8 nodes (e.g. 4.5x speedup on AlexNet, 4x on GoogLeNet, 4x on CIFAR-10). On the much larger ImageNet22K dataset, Poseidon with 8 nodes achieves better speedup and competitive accuracy to recent CPU-based distributed systems such as Adam and Le et al., which use 10s to 1000s of nodes.
Petuum: A New Platform for Distributed Machine Learning on Big Data
May 14, 2015
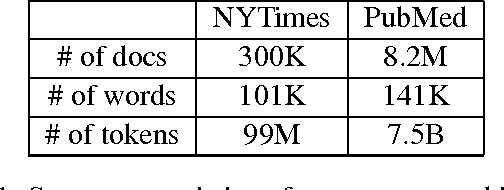

What is a systematic way to efficiently apply a wide spectrum of advanced ML programs to industrial scale problems, using Big Models (up to 100s of billions of parameters) on Big Data (up to terabytes or petabytes)? Modern parallelization strategies employ fine-grained operations and scheduling beyond the classic bulk-synchronous processing paradigm popularized by MapReduce, or even specialized graph-based execution that relies on graph representations of ML programs. The variety of approaches tends to pull systems and algorithms design in different directions, and it remains difficult to find a universal platform applicable to a wide range of ML programs at scale. We propose a general-purpose framework that systematically addresses data- and model-parallel challenges in large-scale ML, by observing that many ML programs are fundamentally optimization-centric and admit error-tolerant, iterative-convergent algorithmic solutions. This presents unique opportunities for an integrative system design, such as bounded-error network synchronization and dynamic scheduling based on ML program structure. We demonstrate the efficacy of these system designs versus well-known implementations of modern ML algorithms, allowing ML programs to run in much less time and at considerably larger model sizes, even on modestly-sized compute clusters.
LightLDA: Big Topic Models on Modest Compute Clusters
Dec 04, 2014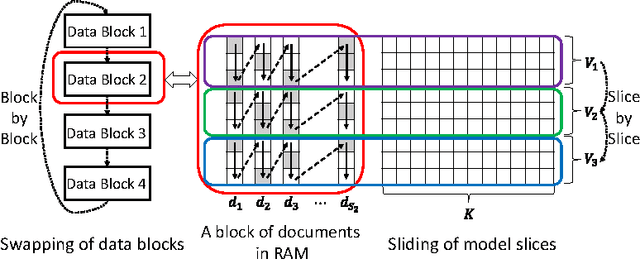

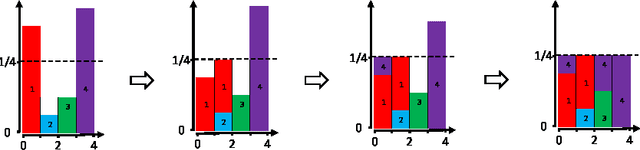
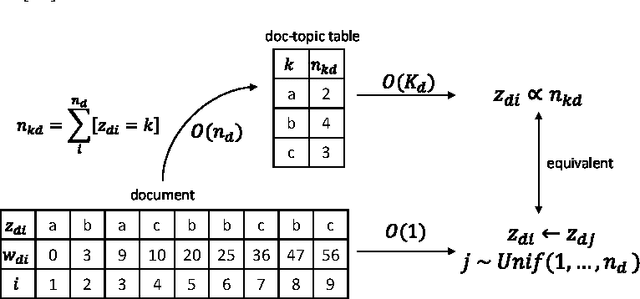
When building large-scale machine learning (ML) programs, such as big topic models or deep neural nets, one usually assumes such tasks can only be attempted with industrial-sized clusters with thousands of nodes, which are out of reach for most practitioners or academic researchers. We consider this challenge in the context of topic modeling on web-scale corpora, and show that with a modest cluster of as few as 8 machines, we can train a topic model with 1 million topics and a 1-million-word vocabulary (for a total of 1 trillion parameters), on a document collection with 200 billion tokens -- a scale not yet reported even with thousands of machines. Our major contributions include: 1) a new, highly efficient O(1) Metropolis-Hastings sampling algorithm, whose running cost is (surprisingly) agnostic of model size, and empirically converges nearly an order of magnitude faster than current state-of-the-art Gibbs samplers; 2) a structure-aware model-parallel scheme, which leverages dependencies within the topic model, yielding a sampling strategy that is frugal on machine memory and network communication; 3) a differential data-structure for model storage, which uses separate data structures for high- and low-frequency words to allow extremely large models to fit in memory, while maintaining high inference speed; and 4) a bounded asynchronous data-parallel scheme, which allows efficient distributed processing of massive data via a parameter server. Our distribution strategy is an instance of the model-and-data-parallel programming model underlying the Petuum framework for general distributed ML, and was implemented on top of the Petuum open-source system. We provide experimental evidence showing how this development puts massive models within reach on a small cluster while still enjoying proportional time cost reductions with increasing cluster size, in comparison with alternative options.
High-Performance Distributed ML at Scale through Parameter Server Consistency Models
Oct 29, 2014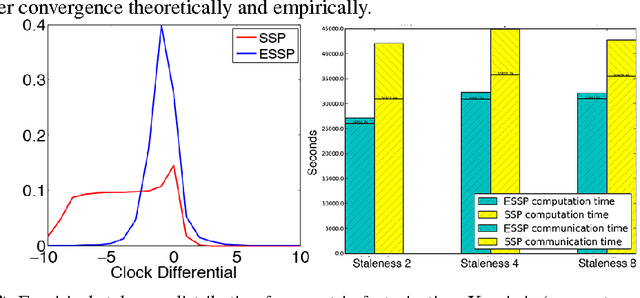
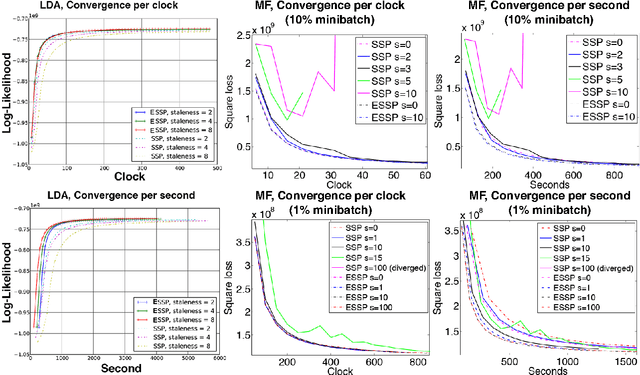
As Machine Learning (ML) applications increase in data size and model complexity, practitioners turn to distributed clusters to satisfy the increased computational and memory demands. Unfortunately, effective use of clusters for ML requires considerable expertise in writing distributed code, while highly-abstracted frameworks like Hadoop have not, in practice, approached the performance seen in specialized ML implementations. The recent Parameter Server (PS) paradigm is a middle ground between these extremes, allowing easy conversion of single-machine parallel ML applications into distributed ones, while maintaining high throughput through relaxed "consistency models" that allow inconsistent parameter reads. However, due to insufficient theoretical study, it is not clear which of these consistency models can really ensure correct ML algorithm output; at the same time, there remain many theoretically-motivated but undiscovered opportunities to maximize computational throughput. Motivated by this challenge, we study both the theoretical guarantees and empirical behavior of iterative-convergent ML algorithms in existing PS consistency models. We then use the gleaned insights to improve a consistency model using an "eager" PS communication mechanism, and implement it as a new PS system that enables ML algorithms to reach their solution more quickly.
Consistent Bounded-Asynchronous Parameter Servers for Distributed ML
Dec 31, 2013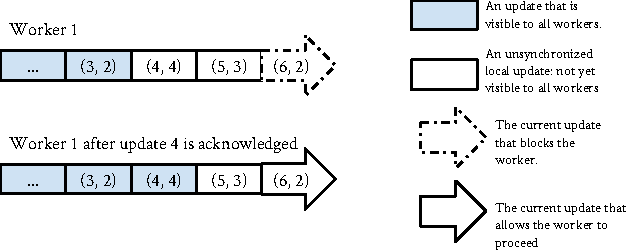

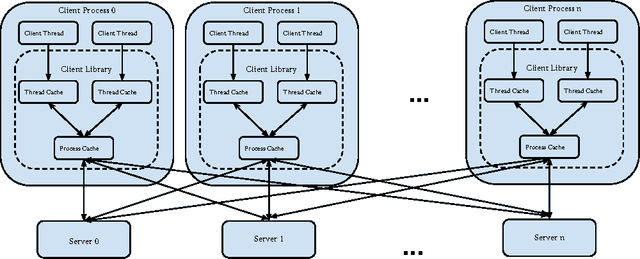
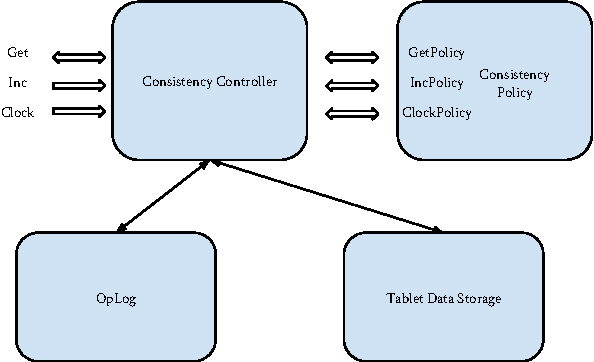
In distributed ML applications, shared parameters are usually replicated among computing nodes to minimize network overhead. Therefore, proper consistency model must be carefully chosen to ensure algorithm's correctness and provide high throughput. Existing consistency models used in general-purpose databases and modern distributed ML systems are either too loose to guarantee correctness of the ML algorithms or too strict and thus fail to fully exploit the computing power of the underlying distributed system. Many ML algorithms fall into the category of \emph{iterative convergent algorithms} which start from a randomly chosen initial point and converge to optima by repeating iteratively a set of procedures. We've found that many such algorithms are to a bounded amount of inconsistency and still converge correctly. This property allows distributed ML to relax strict consistency models to improve system performance while theoretically guarantees algorithmic correctness. In this paper, we present several relaxed consistency models for asynchronous parallel computation and theoretically prove their algorithmic correctness. The proposed consistency models are implemented in a distributed parameter server and evaluated in the context of a popular ML application: topic modeling.