 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoseidon: A System Architecture for Efficient GPU-based Deep Learning on Multiple Machines
Paper and Code
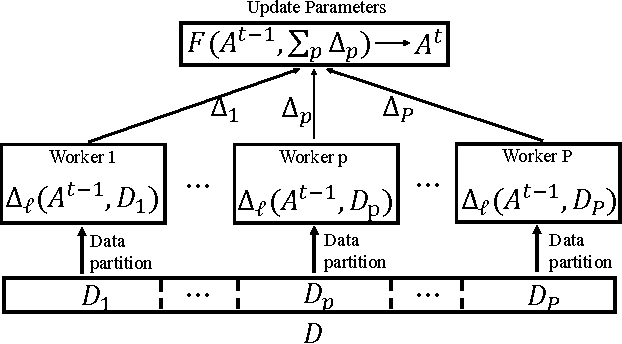
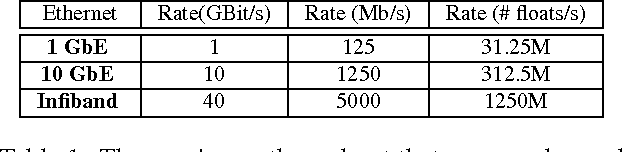

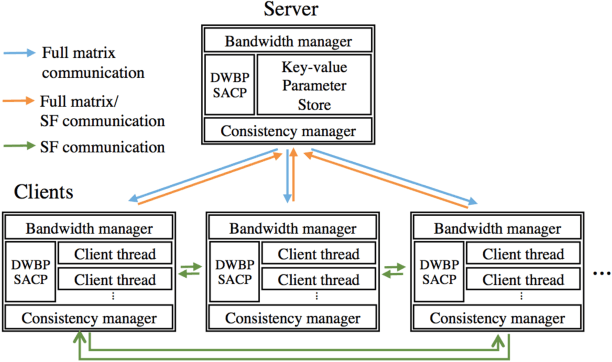
Deep learning (DL) has achieved notable successes in many machine learning tasks. A number of frameworks have been developed to expedite the process of designing and training deep neural networks (DNNs), such as Caffe, Torch and Theano. Currently they can harness multiple GPUs on a single machine, but are unable to use GPUs that are distributed across multiple machines; as even average-sized DNNs can take days to train on a single GPU with 100s of GBs to TBs of data, distributed GPUs present a prime opportunity for scaling up DL. However, the limited bandwidth available on commodity Ethernet networks presents a bottleneck to distributed GPU training, and prevents its trivial realization. To investigate how to adapt existing frameworks to efficiently support distributed GPUs, we propose Poseidon, a scalable system architecture for distributed inter-machine communication in existing DL frameworks. We integrate Poseidon with Caffe and evaluate its performance at training DNNs for object recognition. Poseidon features three key contributions that accelerate DNN training on clusters: (1) a three-level hybrid architecture that allows Poseidon to support both CPU-only and GPU-equipped clusters, (2) a distributed wait-free backpropagation (DWBP) algorithm to improve GPU utilization and to balance communication, and (3) a structure-aware communication protocol (SACP) to minimize communication overheads. We empirically show that Poseidon converges to same objectives as a single machine, and achieves state-of-art training speedup across multiple models and well-established datasets using a commodity GPU cluster of 8 nodes (e.g. 4.5x speedup on AlexNet, 4x on GoogLeNet, 4x on CIFAR-10). On the much larger ImageNet22K dataset, Poseidon with 8 nodes achieves better speedup and competitive accuracy to recent CPU-based distributed systems such as Adam and Le et al., which use 10s to 1000s of nodes.