 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-guided Self-reflection for Zero-shot Hallucination Detection in Large Language Models
Jan 17, 2025Hallucination has emerged as a significant barrier to the effective application of Large Language Models (LLMs). In this work, we introduce a novel Attention-Guided SElf-Reflection (AGSER) approach for zero-shot hallucination detection in LLMs. The AGSER method utilizes attention contributions to categorize the input query into attentive and non-attentive queries. Each query is then processed separately through the LLMs, allowing us to compute consistency scores between the generated responses and the original answer. The difference between the two consistency scores serves as a hallucination estimator. In addition to its efficacy in detecting hallucinations, AGSER notably reduces computational complexity, requiring only three passes through the LLM and utilizing two sets of tokens. We have conducted extensive experiments with four widely-used LLMs across three different hallucination benchmarks, demonstrating that our approach significantly outperforms existing methods in zero-shot hallucination detection.
LiBRe: A Practical Bayesian Approach to Adversarial Detection
Mar 27, 2021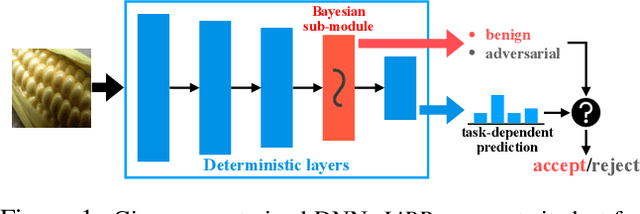


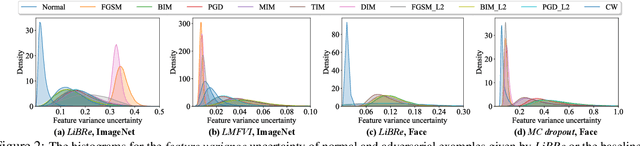
Despite their appealing flexibility, deep neural networks (DNNs) are vulnerable against adversarial examples. Various adversarial defense strategies have been proposed to resolve this problem, but they typically demonstrate restricted practicability owing to unsurmountable compromise on universality, effectiveness, or efficiency. In this work, we propose a more practical approach, Lightweight Bayesian Refinement (LiBRe), in the spirit of leveraging Bayesian neural networks (BNNs) for adversarial detection. Empowered by the task and attack agnostic modeling under Bayes principle, LiBRe can endow a variety of pre-trained task-dependent DNNs with the ability of defending heterogeneous adversarial attacks at a low cost. We develop and integrate advanced learning techniques to make LiBRe appropriate for adversarial detection. Concretely, we build the few-layer deep ensemble variational and adopt the pre-training & fine-tuning workflow to boost the effectiveness and efficiency of LiBRe. We further provide a novel insight to realise adversarial detection-oriented uncertainty quantification without inefficiently crafting adversarial examples during training. Extensive empirical studies covering a wide range of scenarios verify the practicability of LiBRe. We also conduct thorough ablation studies to evidence the superiority of our modeling and learning strategies.
GraphVite: A High-Performance CPU-GPU Hybrid System for Node Embedding
Mar 02, 2019
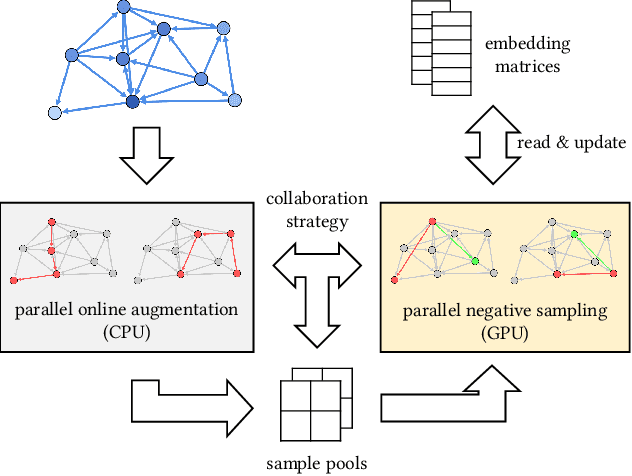
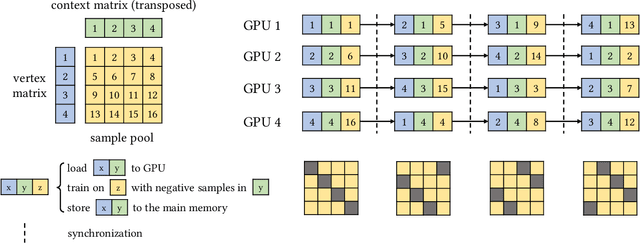

Learning continuous representations of nodes is attracting growing interest in both academia and industry recently, due to their simplicity and effectiveness in a variety of applications. Most of existing node embedding algorithms and systems are capable of processing networks with hundreds of thousands or a few millions of nodes. However, how to scale them to networks that have tens of millions or even hundreds of millions of nodes remains a challenging problem. In this paper, we propose GraphVite, a high-performance CPU-GPU hybrid system for training node embeddings, by co-optimizing the algorithm and the system. On the CPU end, augmented edge samples are parallelly generated by random walks in an online fashion on the network, and serve as the training data. On the GPU end, a novel parallel negative sampling is proposed to leverage multiple GPUs to train node embeddings simultaneously, without much data transfer and synchronization. Moreover, an efficient collaboration strategy is proposed to further reduce the synchronization cost between CPUs and GPUs. Experiments on multiple real-world networks show that GraphVite is super efficient. It takes only about one minute for a network with 1 million nodes and 5 million edges on a single machine with 4 GPUs, and takes around 20 hours for a network with 66 million nodes and 1.8 billion edges. Compared to the current fastest system, GraphVite is about 50 times faster without any sacrifice on performance.
Fast Locality Sensitive Hashing for Beam Search on GPU
Jun 02, 2018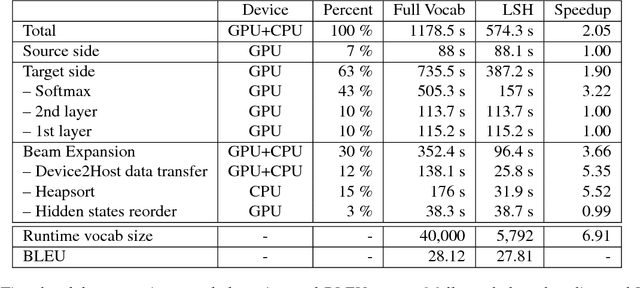
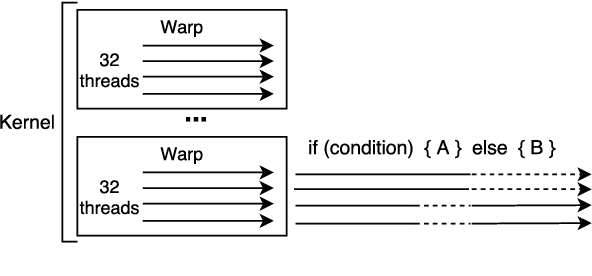
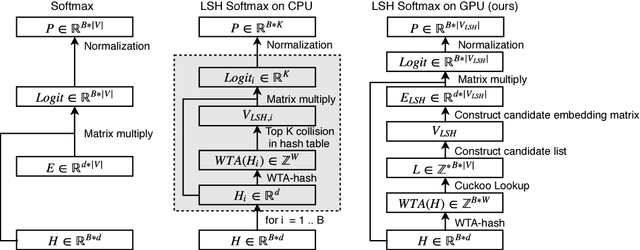
We present a GPU-based Locality Sensitive Hashing (LSH) algorithm to speed up beam search for sequence models. We utilize the winner-take-all (WTA) hash, which is based on relative ranking order of hidden dimensions and thus resilient to perturbations in numerical values. Our algorithm is designed by fully considering the underling architecture of CUDA-enabled GPUs (Algorithm/Architecture Co-design): 1) A parallel Cuckoo hash table is applied for LSH code lookup (guaranteed O(1) lookup time); 2) Candidate lists are shared across beams to maximize the parallelism; 3) Top frequent words are merged into candidate lists to improve performance. Experiments on 4 large-scale neural machine translation models demonstrate that our algorithm can achieve up to 4x speedup on softmax module, and 2x overall speedup without hurting BLEU on GPU.
Cavs: A Vertex-centric Programming Interface for Dynamic Neural Networks
Dec 11, 2017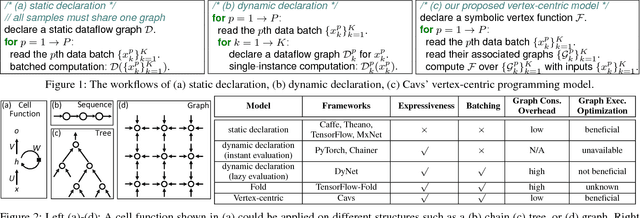
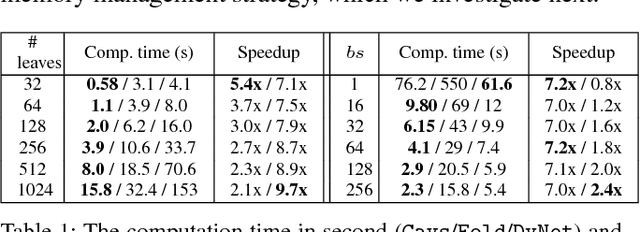
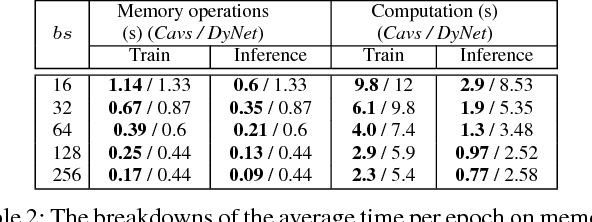
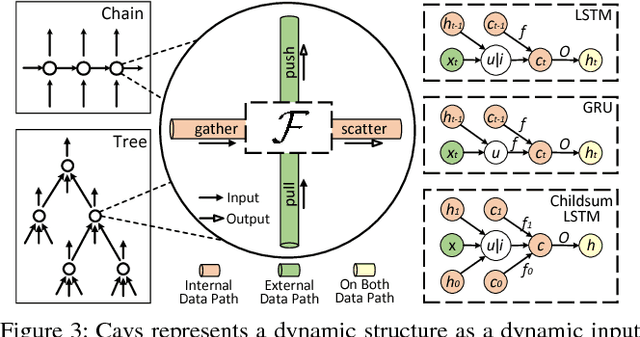
Recent deep learning (DL) models have moved beyond static network architectures to dynamic ones, handling data where the network structure changes every example, such as sequences of variable lengths, trees, and graphs. Existing dataflow-based programming models for DL---both static and dynamic declaration---either cannot readily express these dynamic models, or are inefficient due to repeated dataflow graph construction and processing, and difficulties in batched execution. We present Cavs, a vertex-centric programming interface and optimized system implementation for dynamic DL models. Cavs represents dynamic network structure as a static vertex function $\mathcal{F}$ and a dynamic instance-specific graph $\mathcal{G}$, and performs backpropagation by scheduling the execution of $\mathcal{F}$ following the dependencies in $\mathcal{G}$. Cavs bypasses expensive graph construction and preprocessing overhead, allows for the use of static graph optimization techniques on pre-defined operations in $\mathcal{F}$, and naturally exposes batched execution opportunities over different graphs. Experiments comparing Cavs to two state-of-the-art frameworks for dynamic NNs (TensorFlow Fold and DyNet) demonstrate the efficacy of this approach: Cavs achieves a near one order of magnitude speedup on training of various dynamic NN architectures, and ablations demonstrate the contribution of our proposed batching and memory management strategies.
Structured Generative Adversarial Networks
Nov 02, 2017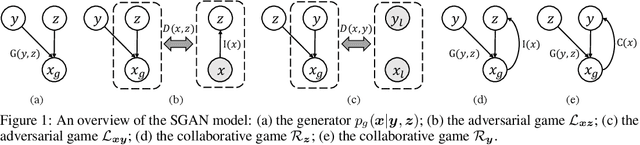
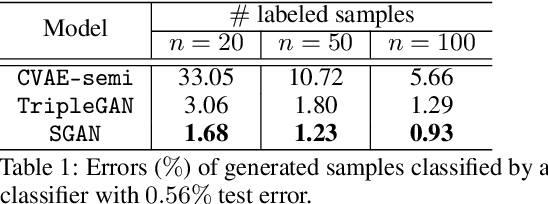
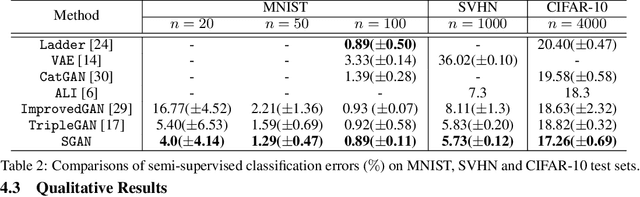

We study the problem of conditional generative modeling based on designated semantics or structures. Existing models that build conditional generators either require massive labeled instances as supervision or are unable to accurately control the semantics of generated samples. We propose structured generative adversarial networks (SGANs) for semi-supervised conditional generative modeling. SGAN assumes the data x is generated conditioned on two independent latent variables: y that encodes the designated semantics, and z that contains other factors of variation. To ensure disentangled semantics in y and z, SGAN builds two collaborative games in the hidden space to minimize the reconstruction error of y and z, respectively. Training SGAN also involves solving two adversarial games that have their equilibrium concentrating at the true joint data distributions p(x, z) and p(x, y), avoiding distributing the probability mass diffusely over data space that MLE-based methods may suffer. We assess SGAN by evaluating its trained networks, and its performance on downstream tasks. We show that SGAN delivers a highly controllable generator, and disentangled representations; it also establishes start-of-the-art results across multiple datasets when applied for semi-supervised image classification (1.27%, 5.73%, 17.26% error rates on MNIST, SVHN and CIFAR-10 using 50, 1000 and 4000 labels, respectively). Benefiting from the separate modeling of y and z, SGAN can generate images with high visual quality and strictly following the designated semantic, and can be extended to a wide spectrum of applications, such as style transfer.
Poseidon: An Efficient Communication Architecture for Distributed Deep Learning on GPU Clusters
Jun 11, 2017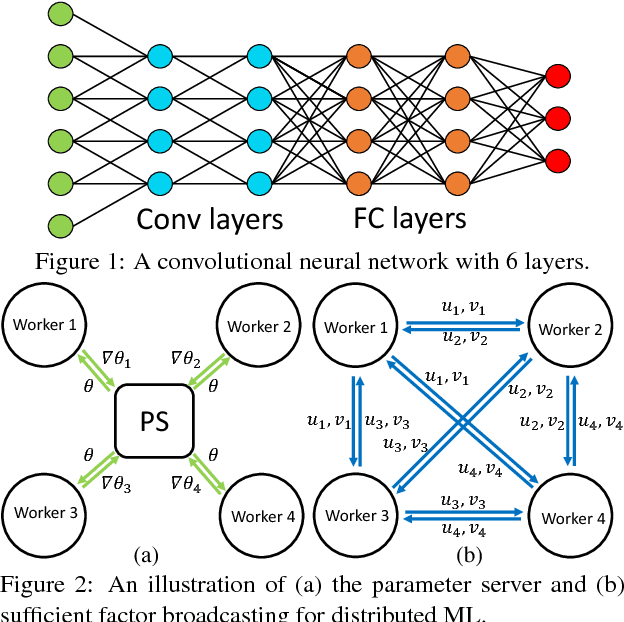
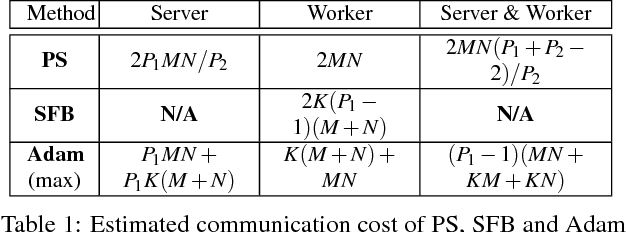
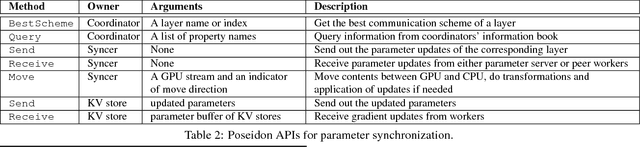
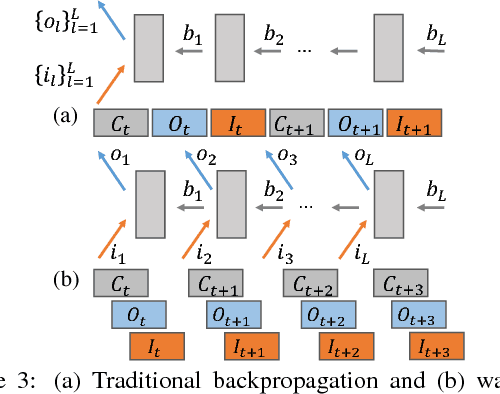
Deep learning models can take weeks to train on a single GPU-equipped machine, necessitating scaling out DL training to a GPU-cluster. However, current distributed DL implementations can scale poorly due to substantial parameter synchronization over the network, because the high throughput of GPUs allows more data batches to be processed per unit time than CPUs, leading to more frequent network synchronization. We present Poseidon, an efficient communication architecture for distributed DL on GPUs. Poseidon exploits the layered model structures in DL programs to overlap communication and computation, reducing bursty network communication. Moreover, Poseidon uses a hybrid communication scheme that optimizes the number of bytes required to synchronize each layer, according to layer properties and the number of machines. We show that Poseidon is applicable to different DL frameworks by plugging Poseidon into Caffe and TensorFlow. We show that Poseidon enables Caffe and TensorFlow to achieve 15.5x speed-up on 16 single-GPU machines, even with limited bandwidth (10GbE) and the challenging VGG19-22K network for image classification. Moreover, Poseidon-enabled TensorFlow achieves 31.5x speed-up with 32 single-GPU machines on Inception-V3, a 50% improvement over the open-source TensorFlow (20x speed-up).