 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-to-Virtual Domain Unification for End-to-End Autonomous Driving
Sep 06, 2018


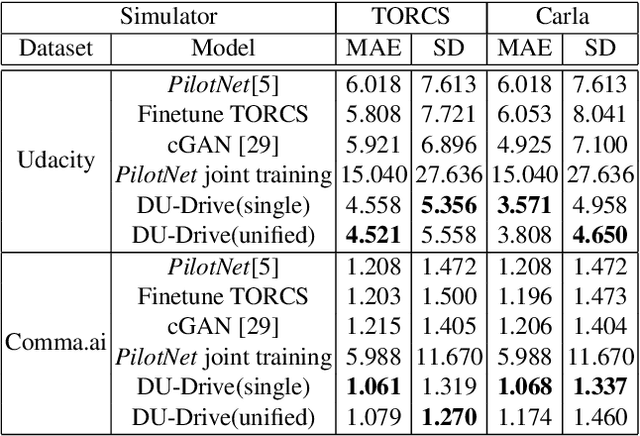
In the spectrum of vision-based autonomous driving, vanilla end-to-end models are not interpretable and suboptimal in performance, while mediated perception models require additional intermediate representations such as segmentation masks or detection bounding boxes, whose annotation can be prohibitively expensive as we move to a larger scale. More critically, all prior works fail to deal with the notorious domain shift if we were to merge data collected from different sources, which greatly hinders the model generalization ability. In this work, we address the above limitations by taking advantage of virtual data collected from driving simulators, and present DU-drive, an unsupervised real-to-virtual domain unification framework for end-to-end autonomous driving. It first transforms real driving data to its less complex counterpart in the virtual domain and then predicts vehicle control commands from the generated virtual image. Our framework has three unique advantages: 1) it maps driving data collected from a variety of source distributions into a unified domain, effectively eliminating domain shift; 2) the learned virtual representation is simpler than the input real image and closer in form to the "minimum sufficient statistic" for the prediction task, which relieves the burden of the compression phase while optimizing the information bottleneck tradeoff and leads to superior prediction performance; 3) it takes advantage of annotated virtual data which is unlimited and free to obtain. Extensive experiments on two public driving datasets and two driving simulators demonstrate the performance superiority and interpretive capability of DU-drive.
CIRL: Controllable Imitative Reinforcement Learning for Vision-based Self-driving
Jul 10, 2018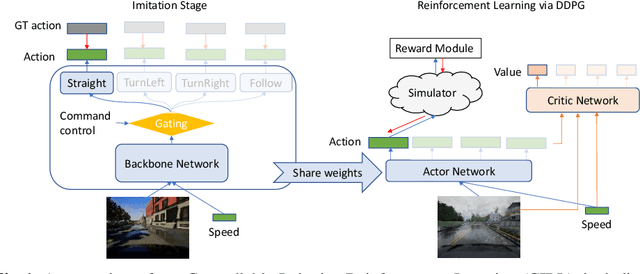
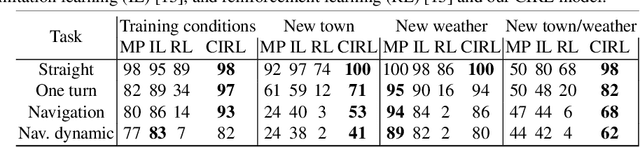
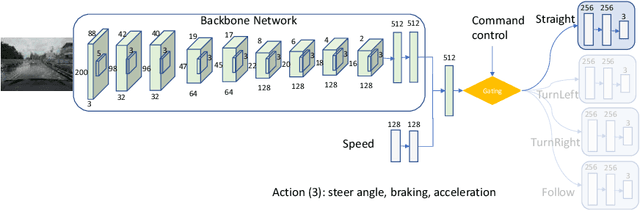
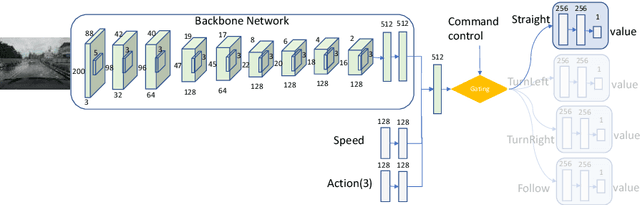
Autonomous urban driving navigation with complex multi-agent dynamics is under-explored due to the difficulty of learning an optimal driving policy. The traditional modular pipeline heavily relies on hand-designed rules and the pre-processing perception system while the supervised learning-based models are limited by the accessibility of extensive human experience. We present a general and principled Controllable Imitative Reinforcement Learning (CIRL) approach which successfully makes the driving agent achieve higher success rates based on only vision inputs in a high-fidelity car simulator. To alleviate the low exploration efficiency for large continuous action space that often prohibits the use of classical RL on challenging real tasks, our CIRL explores over a reasonably constrained action space guided by encoded experiences that imitate human demonstrations, building upon Deep Deterministic Policy Gradient (DDPG). Moreover, we propose to specialize adaptive policies and steering-angle reward designs for different control signals (i.e. follow, straight, turn right, turn left) based on the shared representations to improve the model capability in tackling with diverse cases. Extensive experiments on CARLA driving benchmark demonstrate that CIRL substantially outperforms all previous methods in terms of the percentage of successfully completed episodes on a variety of goal-directed driving tasks. We also show its superior generalization capability in unseen environments. To our knowledge, this is the first successful case of the learned driving policy through reinforcement learning in the high-fidelity simulator, which performs better-than supervised imitation learning.
Structured Generative Adversarial Networks
Nov 02, 2017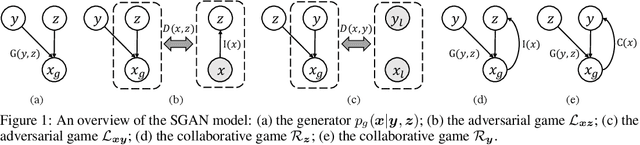
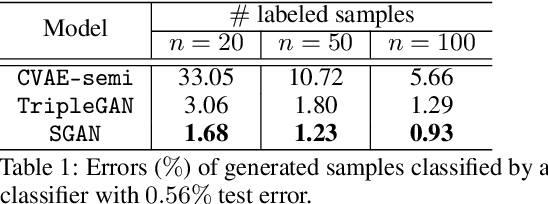
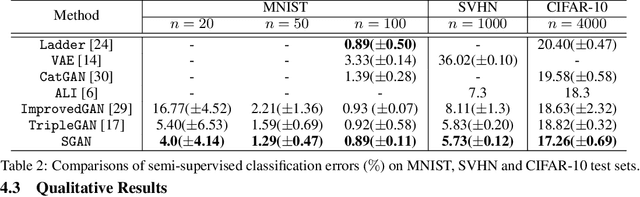

We study the problem of conditional generative modeling based on designated semantics or structures. Existing models that build conditional generators either require massive labeled instances as supervision or are unable to accurately control the semantics of generated samples. We propose structured generative adversarial networks (SGANs) for semi-supervised conditional generative modeling. SGAN assumes the data x is generated conditioned on two independent latent variables: y that encodes the designated semantics, and z that contains other factors of variation. To ensure disentangled semantics in y and z, SGAN builds two collaborative games in the hidden space to minimize the reconstruction error of y and z, respectively. Training SGAN also involves solving two adversarial games that have their equilibrium concentrating at the true joint data distributions p(x, z) and p(x, y), avoiding distributing the probability mass diffusely over data space that MLE-based methods may suffer. We assess SGAN by evaluating its trained networks, and its performance on downstream tasks. We show that SGAN delivers a highly controllable generator, and disentangled representations; it also establishes start-of-the-art results across multiple datasets when applied for semi-supervised image classification (1.27%, 5.73%, 17.26% error rates on MNIST, SVHN and CIFAR-10 using 50, 1000 and 4000 labels, respectively). Benefiting from the separate modeling of y and z, SGAN can generate images with high visual quality and strictly following the designated semantic, and can be extended to a wide spectrum of applications, such as style transfer.