 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Performance Distributed ML at Scale through Parameter Server Consistency Models
Paper and Code
Oct 29, 2014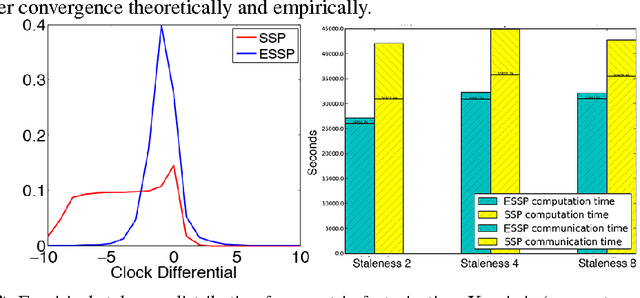
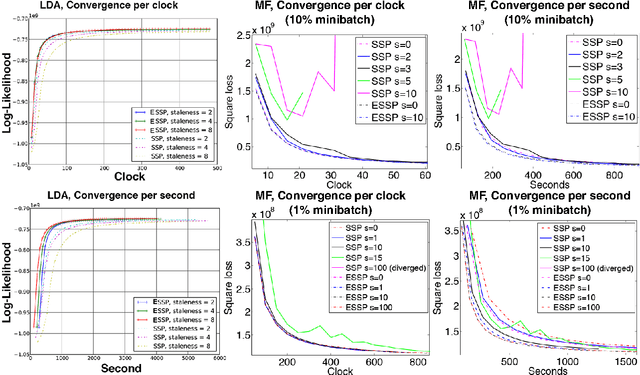
As Machine Learning (ML) applications increase in data size and model complexity, practitioners turn to distributed clusters to satisfy the increased computational and memory demands. Unfortunately, effective use of clusters for ML requires considerable expertise in writing distributed code, while highly-abstracted frameworks like Hadoop have not, in practice, approached the performance seen in specialized ML implementations. The recent Parameter Server (PS) paradigm is a middle ground between these extremes, allowing easy conversion of single-machine parallel ML applications into distributed ones, while maintaining high throughput through relaxed "consistency models" that allow inconsistent parameter reads. However, due to insufficient theoretical study, it is not clear which of these consistency models can really ensure correct ML algorithm output; at the same time, there remain many theoretically-motivated but undiscovered opportunities to maximize computational throughput. Motivated by this challenge, we study both the theoretical guarantees and empirical behavior of iterative-convergent ML algorithms in existing PS consistency models. We then use the gleaned insights to improve a consistency model using an "eager" PS communication mechanism, and implement it as a new PS system that enables ML algorithms to reach their solution more quickly.