 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Data-Plane Memory Scheduling for In-Network Aggregation
Jan 17, 2022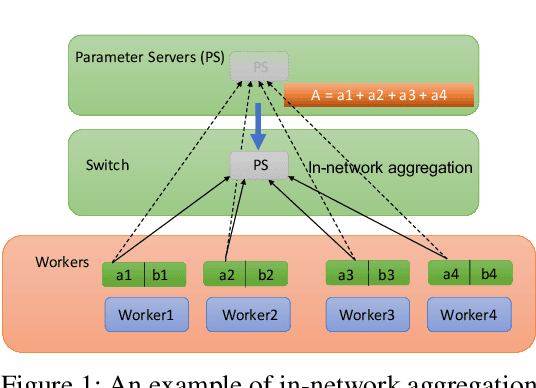

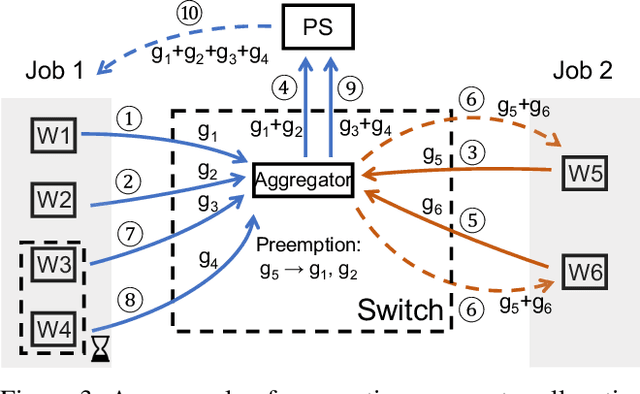
As the scale of distributed training grows, communication becomes a bottleneck. To accelerate the communication, recent works introduce In-Network Aggregation (INA), which moves the gradients summation into network middle-boxes, e.g., programmable switches to reduce the traffic volume. However, switch memory is scarce compared to the volume of gradients transmitted in distributed training. Although literature applies methods like pool-based streaming or dynamic sharing to tackle the mismatch, switch memory is still a potential performance bottleneck. Furthermore, we observe the under-utilization of switch memory due to the synchronization requirement for aggregator deallocation in recent works. To improve the switch memory utilization, we propose ESA, an $\underline{E}$fficient Switch Memory $\underline{S}$cheduler for In-Network $\underline{A}$ggregation. At its cores, ESA enforces the preemptive aggregator allocation primitive and introduces priority scheduling at the data-plane, which improves the switch memory utilization and average job completion time (JCT). Experiments show that ESA can improve the average JCT by up to $1.35\times$.