 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Free Pyramid Token Pruning for Efficient Large Vision-Language Models via Region, Token, and Instruction-Guided Importance
Sep 19, 2025Large Vision-Language Models (LVLMs) have significantly advanced multimodal understanding but still struggle with efficiently processing high-resolution images. Recent approaches partition high-resolution images into multiple sub-images, dramatically increasing the number of visual tokens and causing exponential computational overhead during inference. To address these limitations, we propose a training-free token pruning strategy, Pyramid Token Pruning (PTP), that integrates bottom-up visual saliency at both region and token levels with top-down instruction-guided importance. Inspired by human visual attention mechanisms, PTP selectively retains more tokens from visually salient regions and further leverages textual instructions to pinpoint tokens most relevant to specific multimodal tasks. Extensive experiments across 13 diverse benchmarks demonstrate that our method substantially reduces computational overhead and inference latency with minimal performance loss.
HERO: Rethinking Visual Token Early Dropping in High-Resolution Large Vision-Language Models
Sep 16, 2025
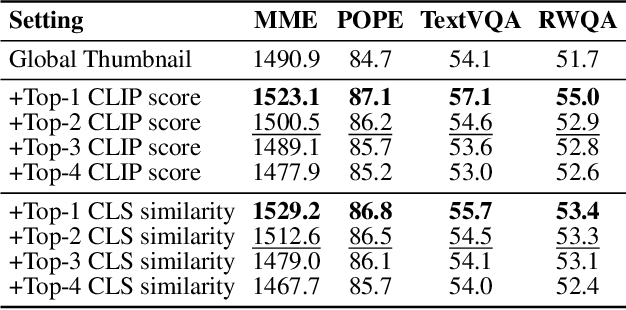
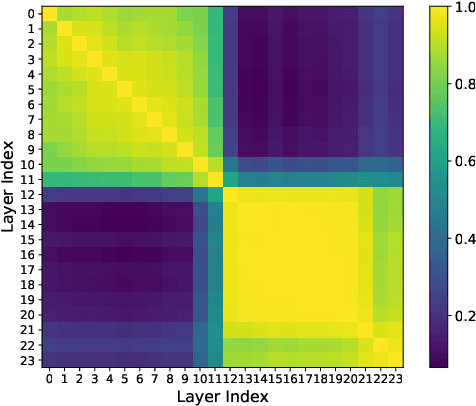
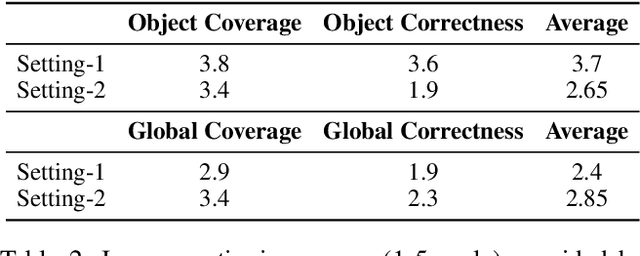
By cropping high-resolution images into local tiles and encoding them independently, High-Resolution Large Vision-Language Models (HR-LVLMs) have demonstrated remarkable fine-grained visual understanding capabilities. However, this divide-and-conquer paradigm significantly increases the number of visual tokens, resulting in substantial computational and memory overhead. To better understand and address this challenge, we empirically investigate visual token utilization in HR-LVLMs and uncover three key findings: (1) the local tiles have varying importance, jointly determined by visual saliency and task relevance; (2) the CLS token in CLIP-based vision encoders exhibits a two-stage attention pattern across layers, with each stage attending to different types of visual tokens; (3) the visual tokens emphasized at different stages encode information at varying levels of granularity, playing complementary roles within LVLMs. Building on these insights, we propose HERO, a High-resolution visual token early dropping framework that integrates content-adaptive token budget allocation with function-aware token selection. By accurately estimating tile-level importance and selectively retaining visual tokens with complementary roles, HERO achieves superior efficiency-accuracy trade-offs across diverse benchmarks and model scales, all in a training-free manner. This study provides both empirical insights and practical solutions toward efficient inference in HR-LVLMs.
Global Semantic-Guided Sub-image Feature Weight Allocation in High-Resolution Large Vision-Language Models
Jan 24, 2025As the demand for high-resolution image processing in Large Vision-Language Models (LVLMs) grows, sub-image partitioning has become a popular approach for mitigating visual information loss associated with fixed-resolution processing. However, existing partitioning methods uniformly process sub-images, resulting in suboptimal image understanding. In this work, we reveal that the sub-images with higher semantic relevance to the entire image encapsulate richer visual information for preserving the model's visual understanding ability. Therefore, we propose the Global Semantic-guided Weight Allocator (GSWA) module, which dynamically allocates weights to sub-images based on their relative information density, emulating human visual attention mechanisms. This approach enables the model to focus on more informative regions, overcoming the limitations of uniform treatment. We integrate GSWA into the InternVL2-2B framework to create SleighVL, a lightweight yet high-performing model. Extensive experiments demonstrate that SleighVL outperforms models with comparable parameters and remains competitive with larger models. Our work provides a promising direction for more efficient and contextually aware high-resolution image processing in LVLMs, advancing multimodal system development.
A Spatial-Temporal Dual-Mode Mixed Flow Network for Panoramic Video Salient Object Detection
Oct 13, 2023



Salient object detection (SOD) in panoramic video is still in the initial exploration stage. The indirect application of 2D video SOD method to the detection of salient objects in panoramic video has many unmet challenges, such as low detection accuracy, high model complexity, and poor generalization performance. To overcome these hurdles, we design an Inter-Layer Attention (ILA) module, an Inter-Layer weight (ILW) module, and a Bi-Modal Attention (BMA) module. Based on these modules, we propose a Spatial-Temporal Dual-Mode Mixed Flow Network (STDMMF-Net) that exploits the spatial flow of panoramic video and the corresponding optical flow for SOD. First, the ILA module calculates the attention between adjacent level features of consecutive frames of panoramic video to improve the accuracy of extracting salient object features from the spatial flow. Then, the ILW module quantifies the salient object information contained in the features of each level to improve the fusion efficiency of the features of each level in the mixed flow. Finally, the BMA module improves the detection accuracy of STDMMF-Net. A large number of subjective and objective experimental results testify that the proposed method demonstrates better detection accuracy than the state-of-the-art (SOTA) methods. Moreover, the comprehensive performance of the proposed method is better in terms of memory required for model inference, testing time, complexity, and generalization performance.