 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Research of Group Re-identification from Multiple Cameras
Jul 19, 2024



Object re-identification is of increasing importance in visual surveillance. Most existing works focus on re-identify individual from multiple cameras while the application of group re-identification (Re-ID) is rarely discussed. We redefine Group Re-identification as a process which includes pedestrian detection, feature extraction, graph model construction, and graph matching. Group re-identification is very challenging since it is not only interfered by view-point and human pose variations in the traditional re-identification tasks, but also suffered from the challenges in group layout change and group member variation. To address the above challenges, this paper introduces a novel approach which leverages the multi-granularity information inside groups to facilitate group re-identification. We first introduce a multi-granularity Re-ID process, which derives features for multi-granularity objects (people/people-subgroups) in a group and iteratively evaluates their importances during group Re-ID, so as to handle group-wise misalignments due to viewpoint change and group dynamics. We further introduce a multi-order matching scheme. It adaptively selects representative people/people-subgroups in each group and integrates the multi-granularity information from these people/people-subgroups to obtain group-wise matching, hence achieving a more reliable matching score between groups. Experimental results on various datasets demonstrate the effectiveness of our approach.
Proof of Quality: A Costless Paradigm for Trustless Generative AI Model Inference on Blockchains
May 28, 2024
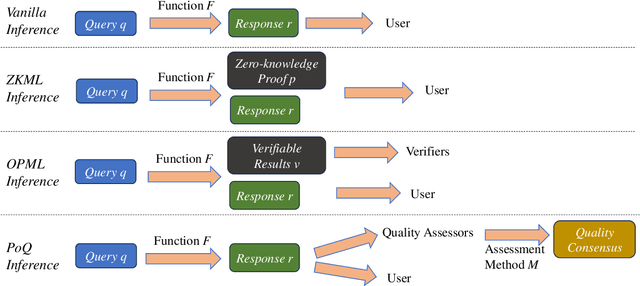


Generative AI models, such as GPT-4 and Stable Diffusion, have demonstrated powerful and disruptive capabilities in natural language and image tasks. However, deploying these models in decentralized environments remains challenging. Unlike traditional centralized deployment, systematically guaranteeing the integrity of AI model services in fully decentralized environments, particularly on trustless blockchains, is both crucial and difficult. In this paper, we present a new inference paradigm called \emph{proof of quality} (PoQ) to enable the deployment of arbitrarily large generative models on blockchain architecture. Unlike traditional approaches based on validating inference procedures, such as ZKML or OPML, our PoQ paradigm focuses on the outcome quality of model inference. Using lightweight BERT-based cross-encoders as our underlying quality evaluation model, we design and implement PQML, the first practical protocol for real-world NLP generative model inference on blockchains, tailored for popular open-source models such as Llama 3 and Mixtral. Our analysis demonstrates that our protocol is robust against adversarial but rational participants in ecosystems, where lazy or dishonest behavior results in fewer benefits compared to well-behaving participants. The computational overhead of validating the quality evaluation is minimal, allowing quality validators to complete the quality check within a second, even using only a CPU. Preliminary simulation results show that PoQ consensus is generated in milliseconds, 1,000 times faster than any existing scheme.
DuoSpaceNet: Leveraging Both Bird's-Eye-View and Perspective View Representations for 3D Object Detection
May 17, 2024



Recent advances in multi-view camera-only 3D object detection either rely on an accurate reconstruction of bird's-eye-view (BEV) 3D features or on traditional 2D perspective view (PV) image features. While both have their own pros and cons, few have found a way to stitch them together in order to benefit from "the best of both worlds". To this end, we explore a duo space (i.e., BEV and PV) 3D perception framework, in conjunction with some useful duo space fusion strategies that allow effective aggregation of the two feature representations. To the best of our knowledge, our proposed method, DuoSpaceNet, is the first to leverage two distinct feature spaces and achieves the state-of-the-art 3D object detection and BEV map segmentation results on nuScenes dataset.
MGTR: Multi-Granular Transformer for Motion Prediction with LiDAR
Dec 05, 2023Motion prediction has been an essential component of autonomous driving systems since it handles highly uncertain and complex scenarios involving moving agents of different types. In this paper, we propose a Multi-Granular TRansformer (MGTR) framework, an encoder-decoder network that exploits context features in different granularities for different kinds of traffic agents. To further enhance MGTR's capabilities, we leverage LiDAR point cloud data by incorporating LiDAR semantic features from an off-the-shelf LiDAR feature extractor. We evaluate MGTR on Waymo Open Dataset motion prediction benchmark and show that the proposed method achieved state-of-the-art performance, ranking 1st on its leaderboard (https://waymo.com/open/challenges/2023/motion-prediction/).
SAPI: Surroundings-Aware Vehicle Trajectory Prediction at Intersections
Jun 02, 2023In this work we propose a deep learning model, i.e., SAPI, to predict vehicle trajectories at intersections. SAPI uses an abstract way to represent and encode surrounding environment by utilizing information from real-time map, right-of-way, and surrounding traffic. The proposed model consists of two convolutional network (CNN) and recurrent neural network (RNN)-based encoders and one decoder. A refiner is proposed to conduct a look-back operation inside the model, in order to make full use of raw history trajectory information. We evaluate SAPI on a proprietary dataset collected in real-world intersections through autonomous vehicles. It is demonstrated that SAPI shows promising performance when predicting vehicle trajectories at intersection, and outperforms benchmark methods. The average displacement error(ADE) and final displacement error(FDE) for 6-second prediction are 1.84m and 4.32m respectively. We also show that the proposed model can accurately predict vehicle trajectories in different scenarios.
Group Re-Identification with Multi-grained Matching and Integration
May 26, 2019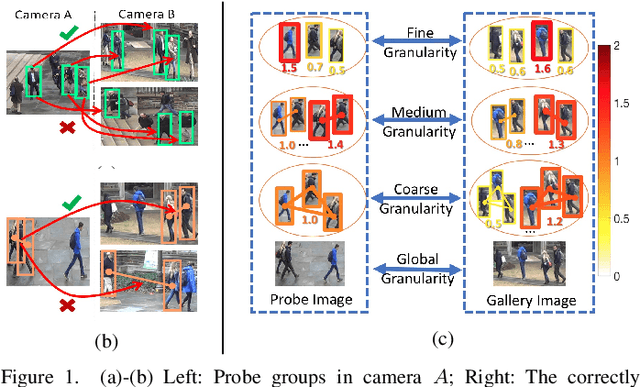
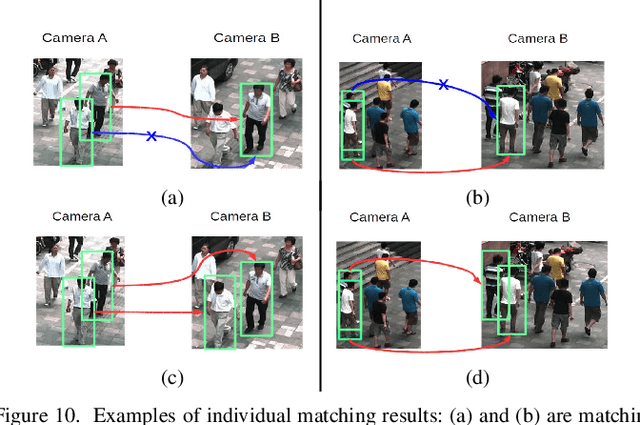


The task of re-identifying groups of people underdifferent camera views is an important yet less-studied problem.Group re-identification (Re-ID) is a very challenging task sinceit is not only adversely affected by common issues in traditionalsingle object Re-ID problems such as viewpoint and human posevariations, but it also suffers from changes in group layout andgroup membership. In this paper, we propose a novel conceptof group granularity by characterizing a group image by multi-grained objects: individual persons and sub-groups of two andthree people within a group. To achieve robust group Re-ID,we first introduce multi-grained representations which can beextracted via the development of two separate schemes, i.e. onewith hand-crafted descriptors and another with deep neuralnetworks. The proposed representation seeks to characterize bothappearance and spatial relations of multi-grained objects, and isfurther equipped with importance weights which capture varia-tions in intra-group dynamics. Optimal group-wise matching isfacilitated by a multi-order matching process which in turn,dynamically updates the importance weights in iterative fashion.We evaluated on three multi-camera group datasets containingcomplex scenarios and large dynamics, with experimental resultsdemonstrating the effectiveness of our approach. The published dataset can be found in \url{http://min.sjtu.edu.cn/lwydemo/GroupReID.html}