 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Alignment-enhanced Adaptive Grounding Network for Generalized Referring Expression Comprehension
Jan 02, 2025In this work, we address the challenging task of Generalized Referring Expression Comprehension (GREC). Compared to the classic Referring Expression Comprehension (REC) that focuses on single-target expressions, GREC extends the scope to a more practical setting by further encompassing no-target and multi-target expressions. Existing REC methods face challenges in handling the complex cases encountered in GREC, primarily due to their fixed output and limitations in multi-modal representations. To address these issues, we propose a Hierarchical Alignment-enhanced Adaptive Grounding Network (HieA2G) for GREC, which can flexibly deal with various types of referring expressions. First, a Hierarchical Multi-modal Semantic Alignment (HMSA) module is proposed to incorporate three levels of alignments, including word-object, phrase-object, and text-image alignment. It enables hierarchical cross-modal interactions across multiple levels to achieve comprehensive and robust multi-modal understanding, greatly enhancing grounding ability for complex cases. Then, to address the varying number of target objects in GREC, we introduce an Adaptive Grounding Counter (AGC) to dynamically determine the number of output targets. Additionally, an auxiliary contrastive loss is employed in AGC to enhance object-counting ability by pulling in multi-modal features with the same counting and pushing away those with different counting. Extensive experimental results show that HieA2G achieves new state-of-the-art performance on the challenging GREC task and also the other 4 tasks, including REC, Phrase Grounding, Referring Expression Segmentation (RES), and Generalized Referring Expression Segmentation (GRES), demonstrating the remarkable superiority and generalizability of the proposed HieA2G.
GoT-CQA: Graph-of-Thought Guided Compositional Reasoning for Chart Question Answering
Sep 04, 2024
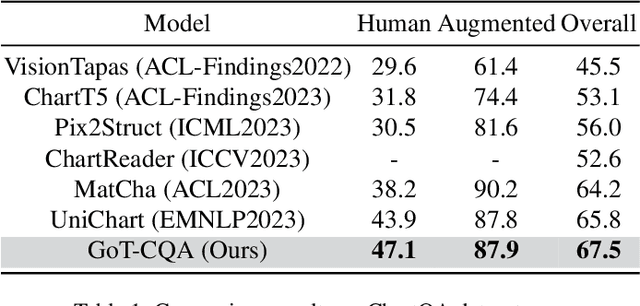
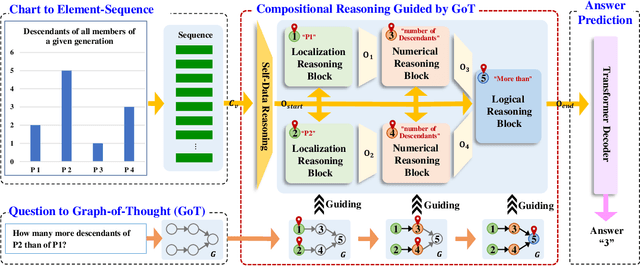
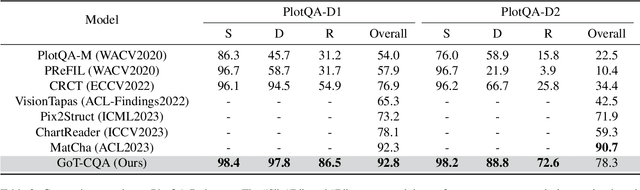
Chart Question Answering (CQA) aims at answering questions based on the visual chart content, which plays an important role in chart sumarization, business data analysis, and data report generation. CQA is a challenging multi-modal task because of the strong context dependence and complex reasoning requirement. The former refers to answering this question strictly based on the analysis of the visual content or internal data of the given chart, while the latter emphasizes the various logical and numerical reasoning involved in answer prediction process. In this paper, we pay more attention on the complex reasoning in CQA task, and propose a novel Graph-of-Thought (GoT) guided compositional reasoning model called GoT-CQA to overcome this problem. At first, we transform the chart-oriented question into a directed acyclic GoT composed of multiple operator nodes, including localization, numerical and logical operator. It intuitively reflects the human brain's solution process to this question. After that, we design an efficient auto-compositional reasoning framework guided by the GoT, to excute the multi-step reasoning operations in various types of questions. Comprehensive experiments on ChartQA and PlotQA-D datasets show that GoT-CQA achieves outstanding performance, especially in complex human-written and reasoning questions, comparing with the latest popular baselines.