 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$\textbf{AGT$^{AO}$}$: Robust and Stabilized LLM Unlearning via Adversarial Gating Training with Adaptive Orthogonality
Feb 02, 2026While Large Language Models (LLMs) have achieved remarkable capabilities, they unintentionally memorize sensitive data, posing critical privacy and security risks. Machine unlearning is pivotal for mitigating these risks, yet existing paradigms face a fundamental dilemma: aggressive unlearning often induces catastrophic forgetting that degrades model utility, whereas conservative strategies risk superficial forgetting, leaving models vulnerable to adversarial recovery. To address this trade-off, we propose $\textbf{AGT$^{AO}$}$ (Adversarial Gating Training with Adaptive Orthogonality), a unified framework designed to reconcile robust erasure with utility preservation. Specifically, our approach introduces $\textbf{Adaptive Orthogonality (AO)}$ to dynamically mitigate geometric gradient conflicts between forgetting and retention objectives, thereby minimizing unintended knowledge degradation. Concurrently, $\textbf{Adversarial Gating Training (AGT)}$ formulates unlearning as a latent-space min-max game, employing a curriculum-based gating mechanism to simulate and counter internal recovery attempts. Extensive experiments demonstrate that $\textbf{AGT$^{AO}$}$ achieves a superior trade-off between unlearning efficacy (KUR $\approx$ 0.01) and model utility (MMLU 58.30). Code is available at https://github.com/TiezMind/AGT-unlearning.
ErrEval: Error-Aware Evaluation for Question Generation through Explicit Diagnostics
Jan 15, 2026Automatic Question Generation (QG) often produces outputs with critical defects, such as factual hallucinations and answer mismatches. However, existing evaluation methods, including LLM-based evaluators, mainly adopt a black-box and holistic paradigm without explicit error modeling, leading to the neglect of such defects and overestimation of question quality. To address this issue, we propose ErrEval, a flexible and Error-aware Evaluation framework that enhances QG evaluation through explicit error diagnostics. Specifically, ErrEval reformulates evaluation as a two-stage process of error diagnosis followed by informed scoring. At the first stage, a lightweight plug-and-play Error Identifier detects and categorizes common errors across structural, linguistic, and content-related aspects. These diagnostic signals are then incorporated as explicit evidence to guide LLM evaluators toward more fine-grained and grounded judgments. Extensive experiments on three benchmarks demonstrate the effectiveness of ErrEval, showing that incorporating explicit diagnostics improves alignment with human judgments. Further analyses confirm that ErrEval effectively mitigates the overestimation of low-quality questions.
MAXS: Meta-Adaptive Exploration with LLM Agents
Jan 14, 2026Large Language Model (LLM) Agents exhibit inherent reasoning abilities through the collaboration of multiple tools. However, during agent inference, existing methods often suffer from (i) locally myopic generation, due to the absence of lookahead, and (ii) trajectory instability, where minor early errors can escalate into divergent reasoning paths. These issues make it difficult to balance global effectiveness and computational efficiency. To address these two issues, we propose meta-adaptive exploration with LLM agents https://github.com/exoskeletonzj/MAXS, a meta-adaptive reasoning framework based on LLM Agents that flexibly integrates tool execution and reasoning planning. MAXS employs a lookahead strategy to extend reasoning paths a few steps ahead, estimating the advantage value of tool usage, and combines step consistency variance and inter-step trend slopes to jointly select stable, consistent, and high-value reasoning steps. Additionally, we introduce a trajectory convergence mechanism that controls computational cost by halting further rollouts once path consistency is achieved, enabling a balance between resource efficiency and global effectiveness in multi-tool reasoning. We conduct extensive empirical studies across three base models (MiMo-VL-7B, Qwen2.5-VL-7B, Qwen2.5-VL-32B) and five datasets, demonstrating that MAXS consistently outperforms existing methods in both performance and inference efficiency. Further analysis confirms the effectiveness of our lookahead strategy and tool usage.
SketchVL: Policy Optimization via Fine-Grained Credit Assignment for Chart Understanding and More
Jan 09, 2026Charts are high-density visual carriers of complex data and medium for information extraction and analysis. Due to the need for precise and complex visual reasoning, automated chart understanding poses a significant challenge to existing Multimodal Large Language Models (MLLMs). Many MLLMs trained with reinforcement learning (RL) face the challenge of credit assignment. Their advantage estimation, typically performed at the trajectory level, cannot distinguish between correct and incorrect reasoning steps within a single generated response. To address this limitation, we introduce SketchVL, a novel MLLM that optimized with FinePO, a new RL algorithm designed for fine-grained credit assignment within each trajectory. SketchVL's methodology involves drawing its intermediate reasoning steps as markers on the image and feeding the annotated image back to itself, creating a robust, multi-step reasoning process. During training, the FinePO algorithm leverages a Fine-grained Process Reward Model (FinePRM) to score each drawing action within a trajectory, thereby precisely assigning credit for each step. This mechanism allows FinePO to more strongly reward correct tokens when a trajectory is globally successful, and more heavily penalize incorrect tokens when the trajectory is globally suboptimal, thus achieving fine-grained reinforcement signals. Experiments show that SketchVL learns to align its step-level behavior with the FinePRM, achieving an average performance gain of 7.23\% over its base model across chart datasets, natural image datasets, and mathematics, providing a promising new direction for training powerful reasoning models.
CoFFT: Chain of Foresight-Focus Thought for Visual Language Models
Sep 26, 2025Despite significant advances in Vision Language Models (VLMs), they remain constrained by the complexity and redundancy of visual input. When images contain large amounts of irrelevant information, VLMs are susceptible to interference, thus generating excessive task-irrelevant reasoning processes or even hallucinations. This limitation stems from their inability to discover and process the required regions during reasoning precisely. To address this limitation, we present the Chain of Foresight-Focus Thought (CoFFT), a novel training-free approach that enhances VLMs' visual reasoning by emulating human visual cognition. Each Foresight-Focus Thought consists of three stages: (1) Diverse Sample Generation: generates diverse reasoning samples to explore potential reasoning paths, where each sample contains several reasoning steps; (2) Dual Foresight Decoding: rigorously evaluates these samples based on both visual focus and reasoning progression, adding the first step of optimal sample to the reasoning process; (3) Visual Focus Adjustment: precisely adjust visual focus toward regions most beneficial for future reasoning, before returning to stage (1) to generate subsequent reasoning samples until reaching the final answer. These stages function iteratively, creating an interdependent cycle where reasoning guides visual focus and visual focus informs subsequent reasoning. Empirical results across multiple benchmarks using Qwen2.5-VL, InternVL-2.5, and Llava-Next demonstrate consistent performance improvements of 3.1-5.8\% with controllable increasing computational overhead.
GeoLaux: A Benchmark for Evaluating MLLMs' Geometry Performance on Long-Step Problems Requiring Auxiliary Lines
Aug 08, 2025Geometry problem solving (GPS) requires models to master diagram comprehension, logical reasoning, knowledge application, numerical computation, and auxiliary line construction. This presents a significant challenge for Multimodal Large Language Models (MLLMs). However, existing benchmarks for evaluating MLLM geometry skills overlook auxiliary line construction and lack fine-grained process evaluation, making them insufficient for assessing MLLMs' long-step reasoning abilities. To bridge these gaps, we present the GeoLaux benchmark, comprising 2,186 geometry problems, incorporating both calculation and proving questions. Notably, the problems require an average of 6.51 reasoning steps, with a maximum of 24 steps, and 41.8% of them need auxiliary line construction. Building on the dataset, we design a novel five-dimensional evaluation strategy assessing answer correctness, process correctness, process quality, auxiliary line impact, and error causes. Extensive experiments on 13 leading MLLMs (including thinking models and non-thinking models) yield three pivotal findings: First, models exhibit substantial performance degradation in extended reasoning steps (nine models demonstrate over 50% performance drop). Second, compared to calculation problems, MLLMs tend to take shortcuts when solving proving problems. Third, models lack auxiliary line awareness, and enhancing this capability proves particularly beneficial for overall geometry reasoning improvement. These findings establish GeoLaux as both a benchmark for evaluating MLLMs' long-step geometric reasoning with auxiliary lines and a guide for capability advancement. Our dataset and code are included in supplementary materials and will be released.
ChartSketcher: Reasoning with Multimodal Feedback and Reflection for Chart Understanding
May 25, 2025Charts are high-density visualization carriers for complex data, serving as a crucial medium for information extraction and analysis. Automated chart understanding poses significant challenges to existing multimodal large language models (MLLMs) due to the need for precise and complex visual reasoning. Current step-by-step reasoning models primarily focus on text-based logical reasoning for chart understanding. However, they struggle to refine or correct their reasoning when errors stem from flawed visual understanding, as they lack the ability to leverage multimodal interaction for deeper comprehension. Inspired by human cognitive behavior, we propose ChartSketcher, a multimodal feedback-driven step-by-step reasoning method designed to address these limitations. ChartSketcher is a chart understanding model that employs Sketch-CoT, enabling MLLMs to annotate intermediate reasoning steps directly onto charts using a programmatic sketching library, iteratively feeding these visual annotations back into the reasoning process. This mechanism enables the model to visually ground its reasoning and refine its understanding over multiple steps. We employ a two-stage training strategy: a cold start phase to learn sketch-based reasoning patterns, followed by off-policy reinforcement learning to enhance reflection and generalization. Experiments demonstrate that ChartSketcher achieves promising performance on chart understanding benchmarks and general vision tasks, providing an interactive and interpretable approach to chart comprehension.
PhysReason: A Comprehensive Benchmark towards Physics-Based Reasoning
Feb 17, 2025
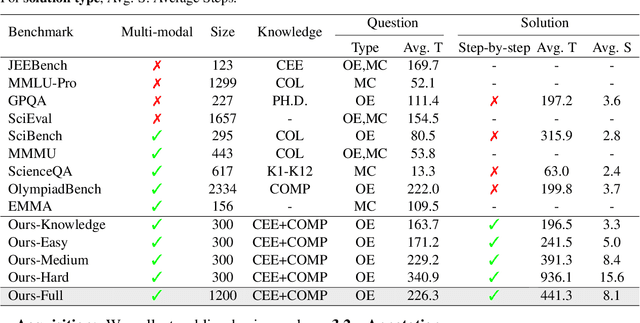


Large language models demonstrate remarkable capabilities across various domains, especially mathematics and logic reasoning. However, current evaluations overlook physics-based reasoning - a complex task requiring physics theorems and constraints. We present PhysReason, a 1,200-problem benchmark comprising knowledge-based (25%) and reasoning-based (75%) problems, where the latter are divided into three difficulty levels (easy, medium, hard). Notably, problems require an average of 8.1 solution steps, with hard requiring 15.6, reflecting the complexity of physics-based reasoning. We propose the Physics Solution Auto Scoring Framework, incorporating efficient answer-level and comprehensive step-level evaluations. Top-performing models like Deepseek-R1, Gemini-2.0-Flash-Thinking, and o3-mini-high achieve less than 60% on answer-level evaluation, with performance dropping from knowledge questions (75.11%) to hard problems (31.95%). Through step-level evaluation, we identified four key bottlenecks: Physics Theorem Application, Physics Process Understanding, Calculation, and Physics Condition Analysis. These findings position PhysReason as a novel and comprehensive benchmark for evaluating physics-based reasoning capabilities in large language models. Our code and data will be published at https:/dxzxy12138.github.io/PhysReason.
DiagramQG: A Dataset for Generating Concept-Focused Questions from Diagrams
Nov 26, 2024



Visual Question Generation (VQG) has gained significant attention due to its potential in educational applications. However, VQG researches mainly focus on natural images, neglecting diagrams in educational materials used to assess students' conceptual understanding. To address this gap, we introduce DiagramQG, a dataset containing 8,372 diagrams and 19,475 questions across various subjects. DiagramQG introduces concept and target text constraints, guiding the model to generate concept-focused questions for educational purposes. Meanwhile, we present the Hierarchical Knowledge Integration framework for Diagram Question Generation (HKI-DQG) as a strong baseline. This framework obtains multi-scale patches of diagrams and acquires knowledge using a visual language model with frozen parameters. It then integrates knowledge, text constraints and patches to generate concept-focused questions. We evaluate the performance of existing VQG models, open-source and closed-source vision-language models, and HKI-DQG on the DiagramQG dataset. Our HKI-DQG outperform existing methods, demonstrating that it serves as a strong baseline. Furthermore, to assess its generalizability, we apply HKI-DQG to two other VQG datasets of natural images, namely VQG-COCO and K-VQG, achieving state-of-the-art performance.The dataset and code are available at https://dxzxy12138.github.io/diagramqg-home.
Few-shot Open Relation Extraction with Gaussian Prototype and Adaptive Margin
Oct 27, 2024



Few-shot relation extraction with none-of-the-above (FsRE with NOTA) aims at predicting labels in few-shot scenarios with unknown classes. FsRE with NOTA is more challenging than the conventional few-shot relation extraction task, since the boundaries of unknown classes are complex and difficult to learn. Meta-learning based methods, especially prototype-based methods, are the mainstream solutions to this task. They obtain the classification boundary by learning the sample distribution of each class. However, their performance is limited because few-shot overfitting and NOTA boundary confusion lead to misclassification between known and unknown classes. To this end, we propose a novel framework based on Gaussian prototype and adaptive margin named GPAM for FsRE with NOTA, which includes three modules, semi-factual representation, GMM-prototype metric learning and decision boundary learning. The first two modules obtain better representations to solve the few-shot problem through debiased information enhancement and Gaussian space distance measurement. The third module learns more accurate classification boundaries and prototypes through adaptive margin and negative sampling. In the training procedure of GPAM, we use contrastive learning loss to comprehensively consider the effects of range and margin on the classification of known and unknown classes to ensure the model's stability and robustness. Sufficient experiments and ablations on the FewRel dataset show that GPAM surpasses previous prototype methods and achieves state-of-the-art performance.