 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-shot Open Relation Extraction with Gaussian Prototype and Adaptive Margin
Oct 27, 2024



Few-shot relation extraction with none-of-the-above (FsRE with NOTA) aims at predicting labels in few-shot scenarios with unknown classes. FsRE with NOTA is more challenging than the conventional few-shot relation extraction task, since the boundaries of unknown classes are complex and difficult to learn. Meta-learning based methods, especially prototype-based methods, are the mainstream solutions to this task. They obtain the classification boundary by learning the sample distribution of each class. However, their performance is limited because few-shot overfitting and NOTA boundary confusion lead to misclassification between known and unknown classes. To this end, we propose a novel framework based on Gaussian prototype and adaptive margin named GPAM for FsRE with NOTA, which includes three modules, semi-factual representation, GMM-prototype metric learning and decision boundary learning. The first two modules obtain better representations to solve the few-shot problem through debiased information enhancement and Gaussian space distance measurement. The third module learns more accurate classification boundaries and prototypes through adaptive margin and negative sampling. In the training procedure of GPAM, we use contrastive learning loss to comprehensively consider the effects of range and margin on the classification of known and unknown classes to ensure the model's stability and robustness. Sufficient experiments and ablations on the FewRel dataset show that GPAM surpasses previous prototype methods and achieves state-of-the-art performance.
Learning from Semi-Factuals: A Debiased and Semantic-Aware Framework for Generalized Relation Discovery
Jan 12, 2024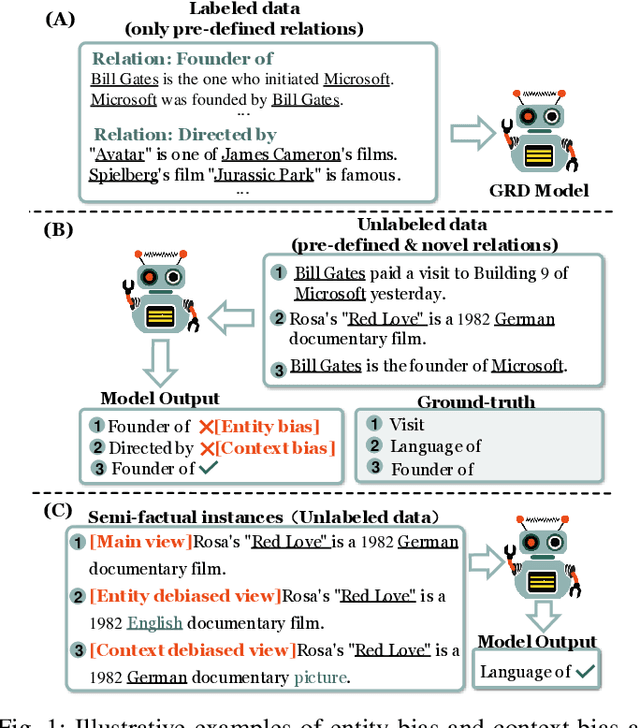



We introduce a novel task, called Generalized Relation Discovery (GRD), for open-world relation extraction. GRD aims to identify unlabeled instances in existing pre-defined relations or discover novel relations by assigning instances to clusters as well as providing specific meanings for these clusters. The key challenges of GRD are how to mitigate the serious model biases caused by labeled pre-defined relations to learn effective relational representations and how to determine the specific semantics of novel relations during classifying or clustering unlabeled instances. We then propose a novel framework, SFGRD, for this task to solve the above issues by learning from semi-factuals in two stages. The first stage is semi-factual generation implemented by a tri-view debiased relation representation module, in which we take each original sentence as the main view and design two debiased views to generate semi-factual examples for this sentence. The second stage is semi-factual thinking executed by a dual-space tri-view collaborative relation learning module, where we design a cluster-semantic space and a class-index space to learn relational semantics and relation label indices, respectively. In addition, we devise alignment and selection strategies to integrate two spaces and establish a self-supervised learning loop for unlabeled data by doing semi-factual thinking across three views. Extensive experimental results show that SFGRD surpasses state-of-the-art models in terms of accuracy by 2.36\% $\sim$5.78\% and cosine similarity by 32.19\%$\sim$ 84.45\% for relation label index and relation semantic quality, respectively. To the best of our knowledge, we are the first to exploit the efficacy of semi-factuals in relation extraction.