 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyID: Ultra-Fidelity Universal Identity-Preserving Video Generation from Any Visual References
Mar 26, 2026Identity-preserving video generation offers powerful tools for creative expression, allowing users to customize videos featuring their beloved characters. However, prevailing methods are typically designed and optimized for a single identity reference. This underlying assumption restricts creative flexibility by inadequately accommodating diverse real-world input formats. Relying on a single source also constitutes an ill-posed scenario, causing an inherently ambiguous setting that makes it difficult for the model to faithfully reproduce an identity across novel contexts. To address these issues, we present AnyID, an ultra-fidelity identity-preservation video generation framework that features two core contributions. First, we introduce a scalable omni-referenced architecture that effectively unifies heterogeneous identity inputs (e.g., faces, portraits, and videos) into a cohesive representation. Second, we propose a primary-referenced generation paradigm, which designates one reference as a canonical anchor and uses a novel differential prompt to enable precise, attribute-level controllability. We conduct training on a large-scale, meticulously curated dataset to ensure robustness and high fidelity, and then perform a final fine-tuning stage using reinforcement learning. This process leverages a preference dataset constructed from human evaluations, where annotators performed pairwise comparisons of videos based on two key criteria: identity fidelity and prompt controllability. Extensive evaluations validate that AnyID achieves ultra-high identity fidelity as well as superior attribute-level controllability across different task settings.
MVGSR: Multi-View Consistent 3D Gaussian Super-Resolution via Epipolar Guidance
Dec 17, 2025Scenes reconstructed by 3D Gaussian Splatting (3DGS) trained on low-resolution (LR) images are unsuitable for high-resolution (HR) rendering. Consequently, a 3DGS super-resolution (SR) method is needed to bridge LR inputs and HR rendering. Early 3DGS SR methods rely on single-image SR networks, which lack cross-view consistency and fail to fuse complementary information across views. More recent video-based SR approaches attempt to address this limitation but require strictly sequential frames, limiting their applicability to unstructured multi-view datasets. In this work, we introduce Multi-View Consistent 3D Gaussian Splatting Super-Resolution (MVGSR), a framework that focuses on integrating multi-view information for 3DGS rendering with high-frequency details and enhanced consistency. We first propose an Auxiliary View Selection Method based on camera poses, making our method adaptable for arbitrarily organized multi-view datasets without the need of temporal continuity or data reordering. Furthermore, we introduce, for the first time, an epipolar-constrained multi-view attention mechanism into 3DGS SR, which serves as the core of our proposed multi-view SR network. This design enables the model to selectively aggregate consistent information from auxiliary views, enhancing the geometric consistency and detail fidelity of 3DGS representations. Extensive experiments demonstrate that our method achieves state-of-the-art performance on both object-centric and scene-level 3DGS SR benchmarks.
HGS: Hybrid Gaussian Splatting with Static-Dynamic Decomposition for Compact Dynamic View Synthesis
Dec 16, 2025Dynamic novel view synthesis (NVS) is essential for creating immersive experiences. Existing approaches have advanced dynamic NVS by introducing 3D Gaussian Splatting (3DGS) with implicit deformation fields or indiscriminately assigned time-varying parameters, surpassing NeRF-based methods. However, due to excessive model complexity and parameter redundancy, they incur large model sizes and slow rendering speeds, making them inefficient for real-time applications, particularly on resource-constrained devices. To obtain a more efficient model with fewer redundant parameters, in this paper, we propose Hybrid Gaussian Splatting (HGS), a compact and efficient framework explicitly designed to disentangle static and dynamic regions of a scene within a unified representation. The core innovation of HGS lies in our Static-Dynamic Decomposition (SDD) strategy, which leverages Radial Basis Function (RBF) modeling for Gaussian primitives. Specifically, for dynamic regions, we employ time-dependent RBFs to effectively capture temporal variations and handle abrupt scene changes, while for static regions, we reduce redundancy by sharing temporally invariant parameters. Additionally, we introduce a two-stage training strategy tailored for explicit models to enhance temporal coherence at static-dynamic boundaries. Experimental results demonstrate that our method reduces model size by up to 98% and achieves real-time rendering at up to 125 FPS at 4K resolution on a single RTX 3090 GPU. It further sustains 160 FPS at 1352 * 1014 on an RTX 3050 and has been integrated into the VR system. Moreover, HGS achieves comparable rendering quality to state-of-the-art methods while providing significantly improved visual fidelity for high-frequency details and abrupt scene changes.
SpotActor: Training-Free Layout-Controlled Consistent Image Generation
Sep 07, 2024



Text-to-image diffusion models significantly enhance the efficiency of artistic creation with high-fidelity image generation. However, in typical application scenarios like comic book production, they can neither place each subject into its expected spot nor maintain the consistent appearance of each subject across images. For these issues, we pioneer a novel task, Layout-to-Consistent-Image (L2CI) generation, which produces consistent and compositional images in accordance with the given layout conditions and text prompts. To accomplish this challenging task, we present a new formalization of dual energy guidance with optimization in a dual semantic-latent space and thus propose a training-free pipeline, SpotActor, which features a layout-conditioned backward update stage and a consistent forward sampling stage. In the backward stage, we innovate a nuanced layout energy function to mimic the attention activations with a sigmoid-like objective. While in the forward stage, we design Regional Interconnection Self-Attention (RISA) and Semantic Fusion Cross-Attention (SFCA) mechanisms that allow mutual interactions across images. To evaluate the performance, we present ActorBench, a specified benchmark with hundreds of reasonable prompt-box pairs stemming from object detection datasets. Comprehensive experiments are conducted to demonstrate the effectiveness of our method. The results prove that SpotActor fulfills the expectations of this task and showcases the potential for practical applications with superior layout alignment, subject consistency, prompt conformity and background diversity.
OneActor: Consistent Character Generation via Cluster-Conditioned Guidance
Apr 16, 2024



Text-to-image diffusion models benefit artists with high-quality image generation. Yet its stochastic nature prevent artists from creating consistent images of the same character. Existing methods try to tackle this challenge and generate consistent content in various ways. However, they either depend on external data or require expensive tuning of the diffusion model. For this issue, we argue that a lightweight but intricate guidance is enough to function. Aiming at this, we lead the way to formalize the objective of consistent generation, derive a clustering-based score function and propose a novel paradigm, OneActor. We design a cluster-conditioned model which incorporates posterior samples to guide the denoising trajectories towards the target cluster. To overcome the overfitting challenge shared by one-shot tuning pipelines, we devise auxiliary components to simultaneously augment the tuning and regulate the inference. This technique is later verified to significantly enhance the content diversity of generated images. Comprehensive experiments show that our method outperforms a variety of baselines with satisfactory character consistency, superior prompt conformity as well as high image quality. And our method is at least 4 times faster than tuning-based baselines. Furthermore, to our best knowledge, we first prove that the semantic space has the same interpolation property as the latent space dose. This property can serve as another promising tool for fine generation control.
Tile Classification Based Viewport Prediction with Multi-modal Fusion Transformer
Sep 28, 2023Viewport prediction is a crucial aspect of tile-based 360 video streaming system. However, existing trajectory based methods lack of robustness, also oversimplify the process of information construction and fusion between different modality inputs, leading to the error accumulation problem. In this paper, we propose a tile classification based viewport prediction method with Multi-modal Fusion Transformer, namely MFTR. Specifically, MFTR utilizes transformer-based networks to extract the long-range dependencies within each modality, then mine intra- and inter-modality relations to capture the combined impact of user historical inputs and video contents on future viewport selection. In addition, MFTR categorizes future tiles into two categories: user interested or not, and selects future viewport as the region that contains most user interested tiles. Comparing with predicting head trajectories, choosing future viewport based on tile's binary classification results exhibits better robustness and interpretability. To evaluate our proposed MFTR, we conduct extensive experiments on two widely used PVS-HM and Xu-Gaze dataset. MFTR shows superior performance over state-of-the-art methods in terms of average prediction accuracy and overlap ratio, also presents competitive computation efficiency.
Disentangled Generation with Information Bottleneck for Few-Shot Learning
Nov 29, 2022



Few-shot learning (FSL), which aims to classify unseen classes with few samples, is challenging due to data scarcity. Although various generative methods have been explored for FSL, the entangled generation process of these methods exacerbates the distribution shift in FSL, thus greatly limiting the quality of generated samples. To these challenges, we propose a novel Information Bottleneck (IB) based Disentangled Generation Framework for FSL, termed as DisGenIB, that can simultaneously guarantee the discrimination and diversity of generated samples. Specifically, we formulate a novel framework with information bottleneck that applies for both disentangled representation learning and sample generation. Different from existing IB-based methods that can hardly exploit priors, we demonstrate our DisGenIB can effectively utilize priors to further facilitate disentanglement. We further prove in theory that some previous generative and disentanglement methods are special cases of our DisGenIB, which demonstrates the generality of the proposed DisGenIB. Extensive experiments on challenging FSL benchmarks confirm the effectiveness and superiority of DisGenIB, together with the validity of our theoretical analyses. Our codes will be open-source upon acceptance.
Power Efficient Video Super-Resolution on Mobile NPUs with Deep Learning, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022



Video super-resolution is one of the most popular tasks on mobile devices, being widely used for an automatic improvement of low-bitrate and low-resolution video streams. While numerous solutions have been proposed for this problem, they are usually quite computationally demanding, demonstrating low FPS rates and power efficiency on mobile devices. In this Mobile AI challenge, we address this problem and propose the participants to design an end-to-end real-time video super-resolution solution for mobile NPUs optimized for low energy consumption. The participants were provided with the REDS training dataset containing video sequences for a 4X video upscaling task. The runtime and power efficiency of all models was evaluated on the powerful MediaTek Dimensity 9000 platform with a dedicated AI processing unit capable of accelerating floating-point and quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 500 FPS rate and 0.2 [Watt / 30 FPS] power consumption. A detailed description of all models developed in the challenge is provided in this paper.
CGUA: Context-Guided and Unpaired-Assisted Weakly Supervised Person Search
Mar 27, 2022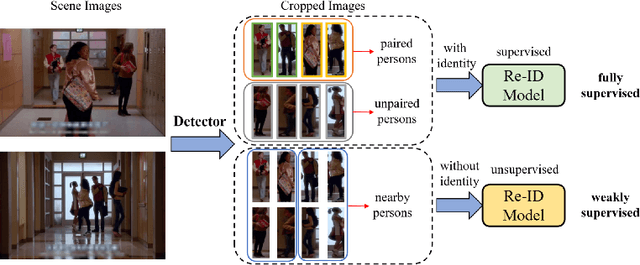
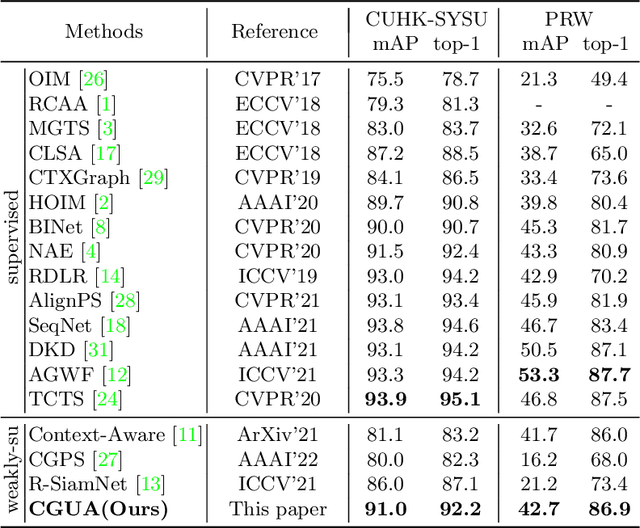
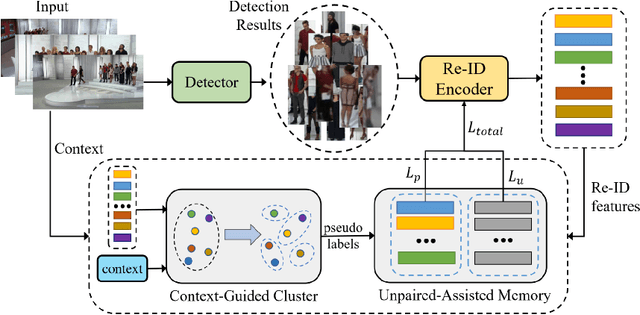
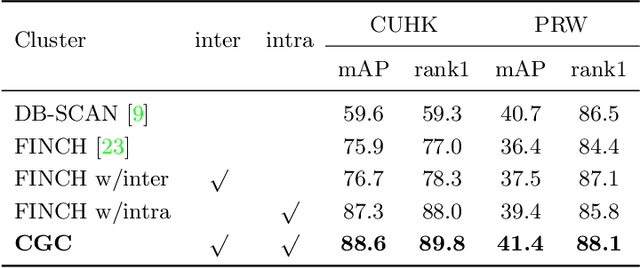
Recently, weakly supervised person search is proposed to discard human-annotated identities and train the model with only bounding box annotations. A natural way to solve this problem is to separate it into detection and unsupervised re-identification (Re-ID) steps. However, in this way, two important clues in unconstrained scene images are ignored. On the one hand, existing unsupervised Re-ID models only leverage cropped images from scene images but ignore its rich context information. On the other hand, there are numerous unpaired persons in real-world scene images. Directly dealing with them as independent identities leads to the long-tail effect, while completely discarding them can result in serious information loss. In light of these challenges, we introduce a Context-Guided and Unpaired-Assisted (CGUA) weakly supervised person search framework. Specifically, we propose a novel Context-Guided Cluster (CGC) algorithm to leverage context information in the clustering process and an Unpaired-Assisted Memory (UAM) unit to distinguish unpaired and paired persons by pushing them away. Extensive experiments demonstrate that the proposed approach can surpass the state-of-the-art weakly supervised methods by a large margin (more than 5% mAP on CUHK-SYSU). Moreover, our method achieves comparable or better performance to the state-of-the-art supervised methods by leveraging more diverse unlabeled data. Codes and models will be released soon.
Semantics-Guided Contrastive Network for Zero-Shot Object detection
Sep 04, 2021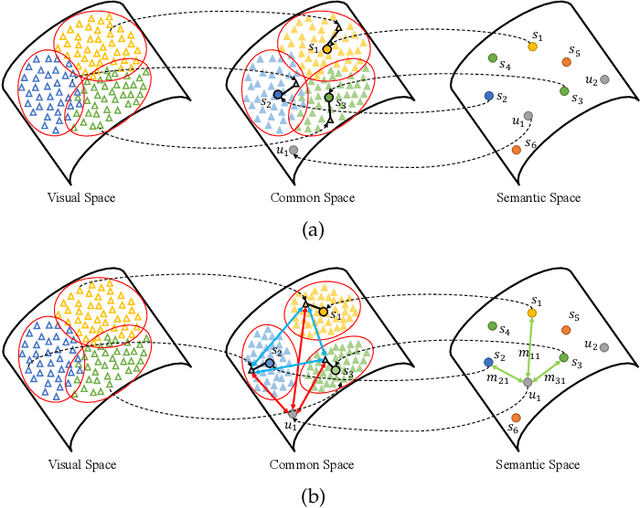
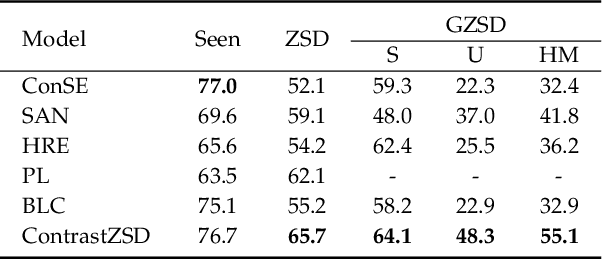


Zero-shot object detection (ZSD), the task that extends conventional detection models to detecting objects from unseen categories, has emerged as a new challenge in computer vision. Most existing approaches tackle the ZSD task with a strict mapping-transfer strategy, which may lead to suboptimal ZSD results: 1) the learning process of those models ignores the available unseen class information, and thus can be easily biased towards the seen categories; 2) the original visual feature space is not well-structured and lack of discriminative information. To address these issues, we develop a novel Semantics-Guided Contrastive Network for ZSD, named ContrastZSD, a detection framework that first brings contrastive learning mechanism into the realm of zero-shot detection. Particularly, ContrastZSD incorporates two semantics-guided contrastive learning subnets that contrast between region-category and region-region pairs respectively. The pairwise contrastive tasks take advantage of additional supervision signals derived from both ground truth label and pre-defined class similarity distribution. Under the guidance of those explicit semantic supervision, the model can learn more knowledge about unseen categories to avoid the bias problem to seen concepts, while optimizing the data structure of visual features to be more discriminative for better visual-semantic alignment. Extensive experiments are conducted on two popular benchmarks for ZSD, i.e., PASCAL VOC and MS COCO. Results show that our method outperforms the previous state-of-the-art on both ZSD and generalized ZSD tasks.