 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing the Robustness of QMIX against State-adversarial Attacks
Jul 03, 2023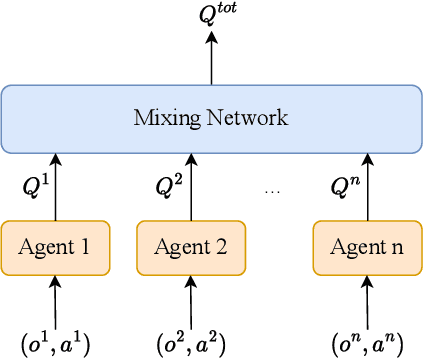
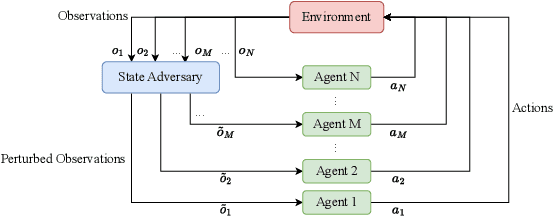
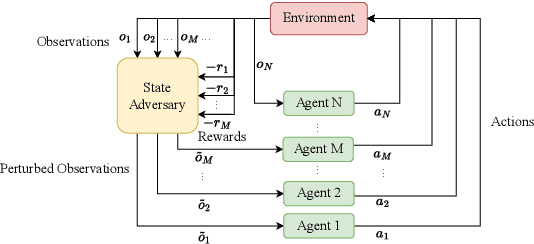
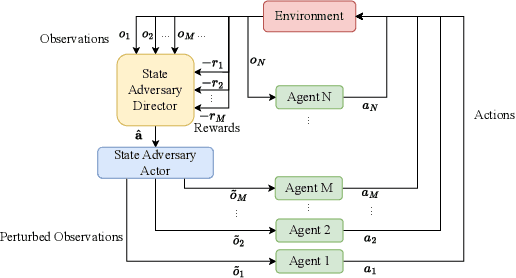
Deep reinforcement learning (DRL) performance is generally impacted by state-adversarial attacks, a perturbation applied to an agent's observation. Most recent research has concentrated on robust single-agent reinforcement learning (SARL) algorithms against state-adversarial attacks. Still, there has yet to be much work on robust multi-agent reinforcement learning. Using QMIX, one of the popular cooperative multi-agent reinforcement algorithms, as an example, we discuss four techniques to improve the robustness of SARL algorithms and extend them to multi-agent scenarios. To increase the robustness of multi-agent reinforcement learning (MARL) algorithms, we train models using a variety of attacks in this research. We then test the models taught using the other attacks by subjecting them to the corresponding attacks throughout the training phase. In this way, we organize and summarize techniques for enhancing robustness when used with MARL.
Robustness Testing for Multi-Agent Reinforcement Learning: State Perturbations on Critical Agents
Jun 09, 2023Multi-Agent Reinforcement Learning (MARL) has been widely applied in many fields such as smart traffic and unmanned aerial vehicles. However, most MARL algorithms are vulnerable to adversarial perturbations on agent states. Robustness testing for a trained model is an essential step for confirming the trustworthiness of the model against unexpected perturbations. This work proposes a novel Robustness Testing framework for MARL that attacks states of Critical Agents (RTCA). The RTCA has two innovations: 1) a Differential Evolution (DE) based method to select critical agents as victims and to advise the worst-case joint actions on them; and 2) a team cooperation policy evaluation method employed as the objective function for the optimization of DE. Then, adversarial state perturbations of the critical agents are generated based on the worst-case joint actions. This is the first robustness testing framework with varying victim agents. RTCA demonstrates outstanding performance in terms of the number of victim agents and destroying cooperation policies.
Multi-Agent Reinforcement Learning: Methods, Applications, Visionary Prospects, and Challenges
May 17, 2023
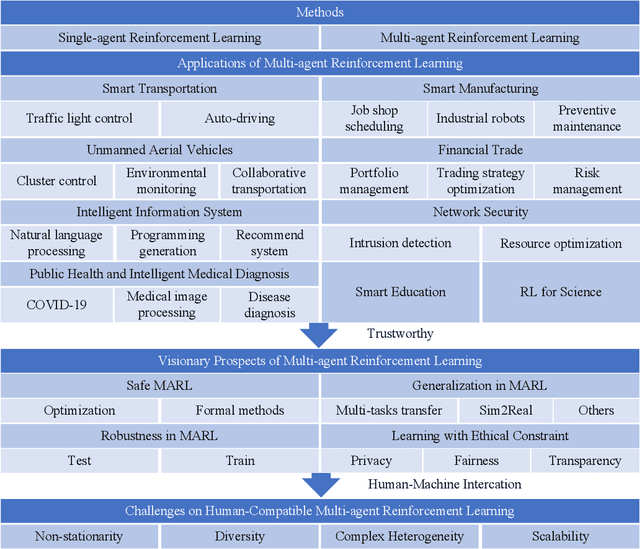


Multi-agent reinforcement learning (MARL) is a widely used Artificial Intelligence (AI) technique. However, current studies and applications need to address its scalability, non-stationarity, and trustworthiness. This paper aims to review methods and applications and point out research trends and visionary prospects for the next decade. First, this paper summarizes the basic methods and application scenarios of MARL. Second, this paper outlines the corresponding research methods and their limitations on safety, robustness, generalization, and ethical constraints that need to be addressed in the practical applications of MARL. In particular, we believe that trustworthy MARL will become a hot research topic in the next decade. In addition, we suggest that considering human interaction is essential for the practical application of MARL in various societies. Therefore, this paper also analyzes the challenges while MARL is applied to human-machine interaction.
Partially Observable Mean Field Multi-Agent Reinforcement Learning Based on Graph-Attention
Apr 25, 2023



Traditional multi-agent reinforcement learning algorithms are difficultly applied in a large-scale multi-agent environment. The introduction of mean field theory has enhanced the scalability of multi-agent reinforcement learning in recent years. This paper considers partially observable multi-agent reinforcement learning (MARL), where each agent can only observe other agents within a fixed range. This partial observability affects the agent's ability to assess the quality of the actions of surrounding agents. This paper focuses on developing a method to capture more effective information from local observations in order to select more effective actions. Previous work in this field employs probability distributions or weighted mean field to update the average actions of neighborhood agents, but it does not fully consider the feature information of surrounding neighbors and leads to a local optimum. In this paper, we propose a novel multi-agent reinforcement learning algorithm, Partially Observable Mean Field Multi-Agent Reinforcement Learning based on Graph--Attention (GAMFQ) to remedy this flaw. GAMFQ uses a graph attention module and a mean field module to describe how an agent is influenced by the actions of other agents at each time step. This graph attention module consists of a graph attention encoder and a differentiable attention mechanism, and this mechanism outputs a dynamic graph to represent the effectiveness of neighborhood agents against central agents. The mean--field module approximates the effect of a neighborhood agent on a central agent as the average effect of effective neighborhood agents. We evaluate GAMFQ on three challenging tasks in the MAgents framework. Experiments show that GAMFQ outperforms baselines including the state-of-the-art partially observable mean-field reinforcement learning algorithms.
RoMFAC: A Robust Mean-Field Actor-Critic Reinforcement Learning against Adversarial Perturbations on States
May 15, 2022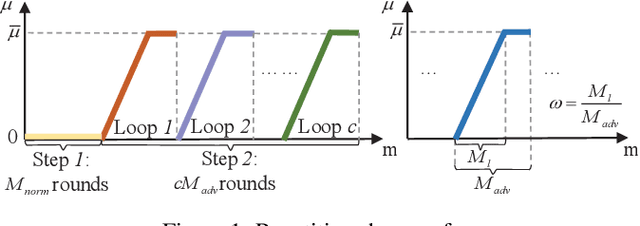
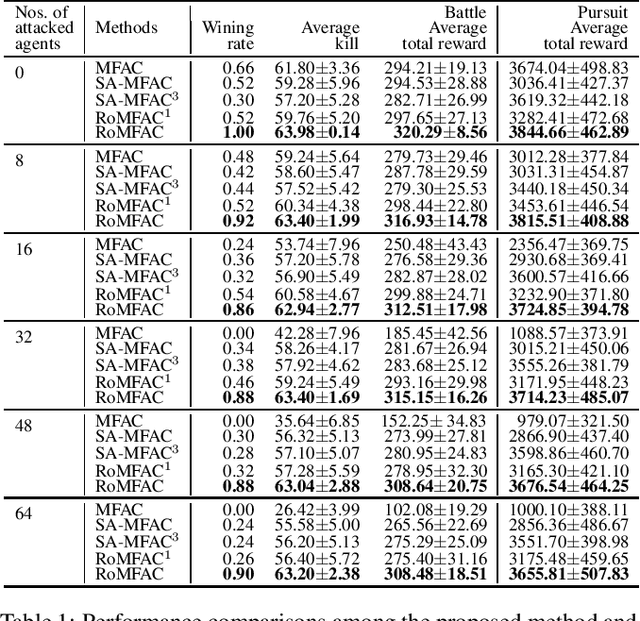
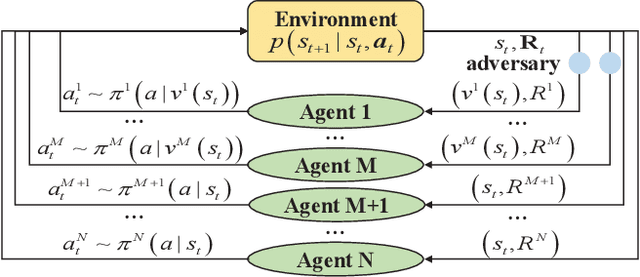
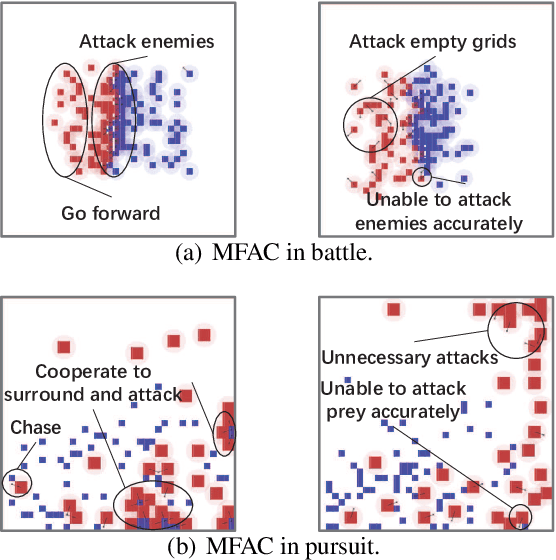
Deep reinforcement learning methods for multi-agent systems make optimal decisions dependent on states observed by agents, but a little uncertainty on the observations can possibly mislead agents into taking wrong actions. The mean-field actor-critic reinforcement learning (MFAC) is very famous in the multi-agent field since it can effectively handle the scalability problem. However, this paper finds that it is also sensitive to state perturbations which can significantly degrade the team rewards. This paper proposes a robust learning framework for MFAC called RoMFAC that has two innovations: 1) a new objective function of training actors, composed of a \emph{policy gradient function} that is related to the expected cumulative discount reward on sampled clean states and an \emph{action loss function} that represents the difference between actions taken on clean and adversarial states; and 2) a repetitive regularization of the action loss that ensures the trained actors obtain a good performance. Furthermore, we prove that the proposed action loss function is convergent. Experiments show that RoMFAC is robust against adversarial perturbations while maintaining its good performance in environments without perturbations.