 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Weaknesses in Function Call Models via Reinforcement Learning: An Adversarial Data Augmentation Approach
Jan 27, 2026Function call capabilities have become crucial for Large Language Models (LLMs), enabling them to interact more effectively with external tools and APIs. Existing methods for improving the function call capabilities of LLMs rely on data obtained either through manual annotation or automated generation by models, and use this data to finetune the LLMs. However, these methods often lack targeted design and are constrained by fixed patterns and data distributions, which limits their effectiveness in enhancing the generalization and robustness of function call LLMs. To address this limitation, we propose a novel adversarial data augmentation method that employs reinforcement learning to systematically identify and target the weaknesses of function call LLMs. Our training framework introduces a query model trained with reinforcement learning (RL) to generate adversarial queries that are specifically designed to challenge function call (FC) models. This approach adopts a zero sum game formulation, where the query model and the FC model engage in iterative alternating training. Overall, our method advances the development of more robust FC models and provides a systematic way to identify and correct weaknesses in the ability of LLMs to interact with external tools.
Enhancing the Robustness of QMIX against State-adversarial Attacks
Jul 03, 2023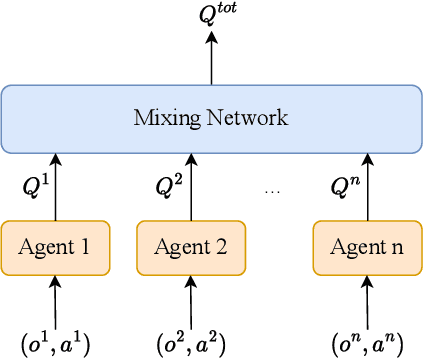
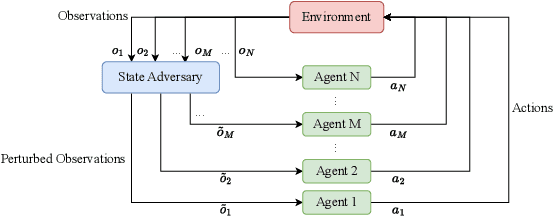
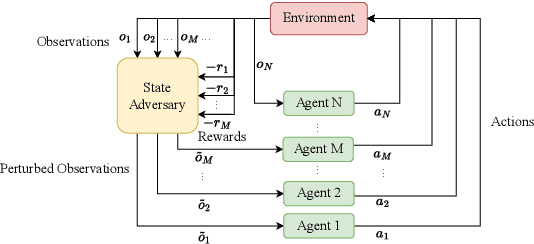
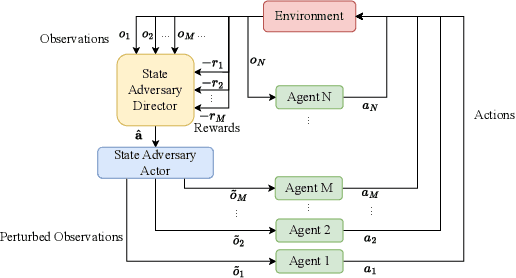
Deep reinforcement learning (DRL) performance is generally impacted by state-adversarial attacks, a perturbation applied to an agent's observation. Most recent research has concentrated on robust single-agent reinforcement learning (SARL) algorithms against state-adversarial attacks. Still, there has yet to be much work on robust multi-agent reinforcement learning. Using QMIX, one of the popular cooperative multi-agent reinforcement algorithms, as an example, we discuss four techniques to improve the robustness of SARL algorithms and extend them to multi-agent scenarios. To increase the robustness of multi-agent reinforcement learning (MARL) algorithms, we train models using a variety of attacks in this research. We then test the models taught using the other attacks by subjecting them to the corresponding attacks throughout the training phase. In this way, we organize and summarize techniques for enhancing robustness when used with MARL.