 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Weaknesses in Function Call Models via Reinforcement Learning: An Adversarial Data Augmentation Approach
Jan 27, 2026Function call capabilities have become crucial for Large Language Models (LLMs), enabling them to interact more effectively with external tools and APIs. Existing methods for improving the function call capabilities of LLMs rely on data obtained either through manual annotation or automated generation by models, and use this data to finetune the LLMs. However, these methods often lack targeted design and are constrained by fixed patterns and data distributions, which limits their effectiveness in enhancing the generalization and robustness of function call LLMs. To address this limitation, we propose a novel adversarial data augmentation method that employs reinforcement learning to systematically identify and target the weaknesses of function call LLMs. Our training framework introduces a query model trained with reinforcement learning (RL) to generate adversarial queries that are specifically designed to challenge function call (FC) models. This approach adopts a zero sum game formulation, where the query model and the FC model engage in iterative alternating training. Overall, our method advances the development of more robust FC models and provides a systematic way to identify and correct weaknesses in the ability of LLMs to interact with external tools.
InstructUIE: Multi-task Instruction Tuning for Unified Information Extraction
Apr 17, 2023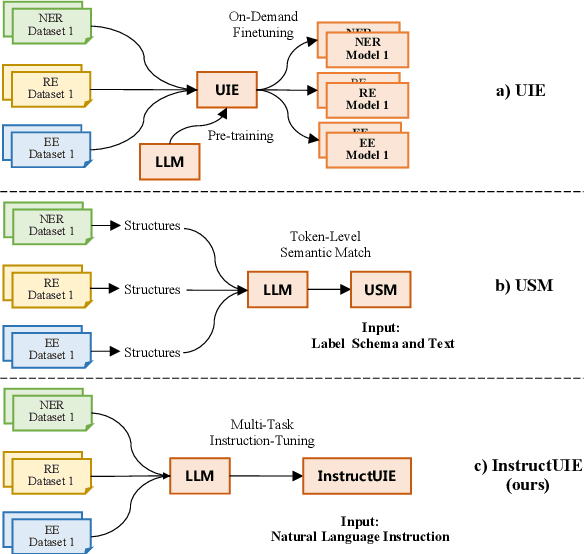
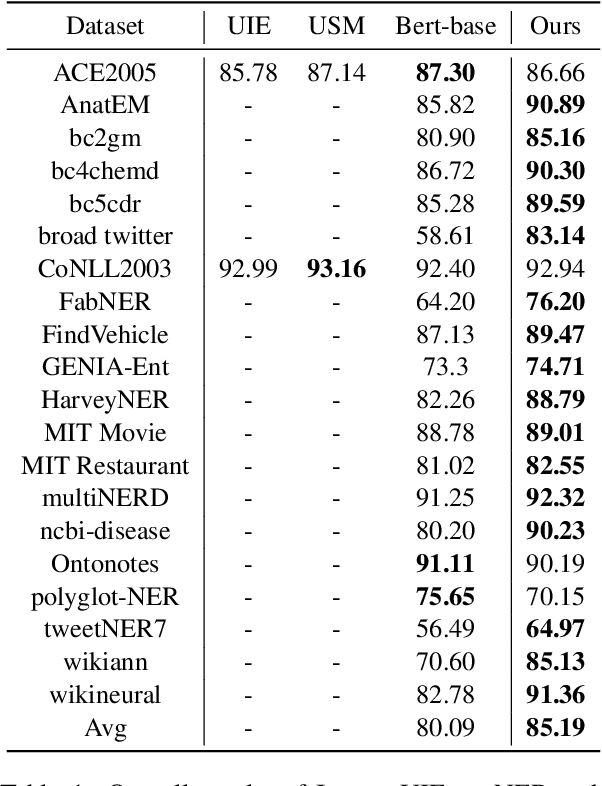
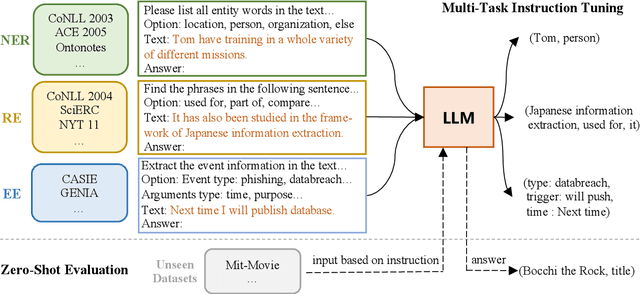
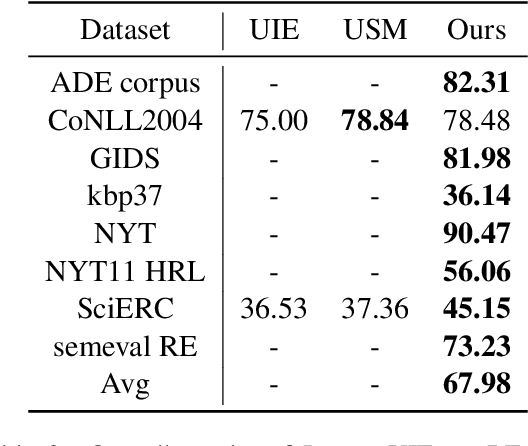
Large language models have unlocked strong multi-task capabilities from reading instructive prompts. However, recent studies have shown that existing large models still have difficulty with information extraction tasks. For example, gpt-3.5-turbo achieved an F1 score of 18.22 on the Ontonotes dataset, which is significantly lower than the state-of-the-art performance. In this paper, we propose InstructUIE, a unified information extraction framework based on instruction tuning, which can uniformly model various information extraction tasks and capture the inter-task dependency. To validate the proposed method, we introduce IE INSTRUCTIONS, a benchmark of 32 diverse information extraction datasets in a unified text-to-text format with expert-written instructions. Experimental results demonstrate that our method achieves comparable performance to Bert in supervised settings and significantly outperforms the state-of-the-art and gpt3.5 in zero-shot settings.
The Volcspeech system for the ICASSP 2022 multi-channel multi-party meeting transcription challenge
Feb 10, 2022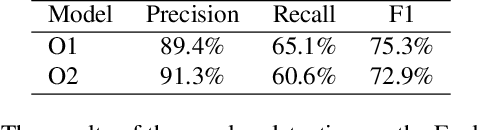
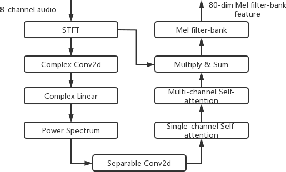
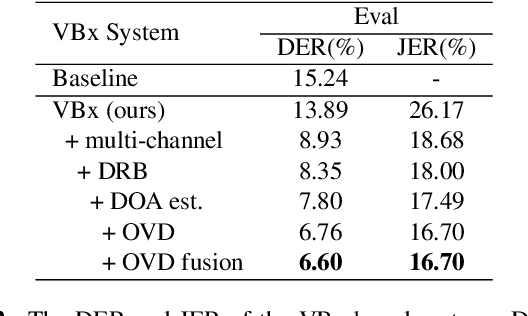
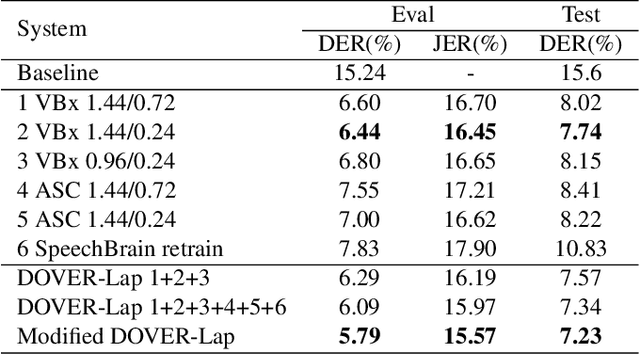
This paper describes our submission to ICASSP 2022 Multi-channel Multi-party Meeting Transcription (M2MeT) Challenge. For Track 1, we propose several approaches to empower the clustering-based speaker diarization system to handle overlapped speech. Front-end dereverberation and the direction-of-arrival (DOA) estimation are used to improve the accuracy of speaker diarization. Multi-channel combination and overlap detection are applied to reduce the missed speaker error. A modified DOVER-Lap is also proposed to fuse the results of different systems. We achieve the final DER of 5.79% on the Eval set and 7.23% on the Test set. For Track 2, we develop our system using the Conformer model in a joint CTC-attention architecture. Serialized output training is adopted to multi-speaker overlapped speech recognition. We propose a neural front-end module to model multi-channel audio and train the model end-to-end. Various data augmentation methods are utilized to mitigate over-fitting in the multi-channel multi-speaker E2E system. Transformer language model fusion is developed to achieve better performance. The final CER is 19.2% on the Eval set and 20.8% on the Test set.