 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Volcspeech system for the ICASSP 2022 multi-channel multi-party meeting transcription challenge
Feb 10, 2022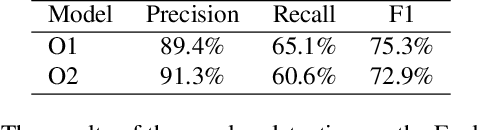
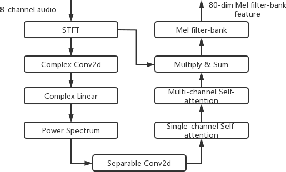
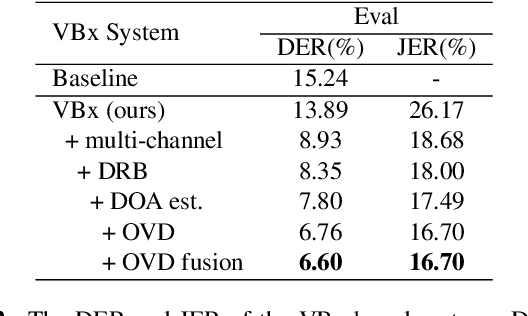
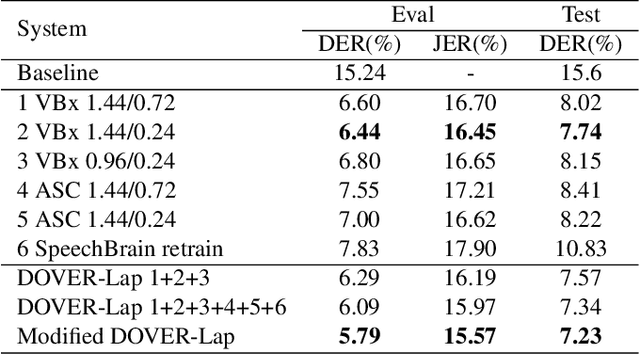
This paper describes our submission to ICASSP 2022 Multi-channel Multi-party Meeting Transcription (M2MeT) Challenge. For Track 1, we propose several approaches to empower the clustering-based speaker diarization system to handle overlapped speech. Front-end dereverberation and the direction-of-arrival (DOA) estimation are used to improve the accuracy of speaker diarization. Multi-channel combination and overlap detection are applied to reduce the missed speaker error. A modified DOVER-Lap is also proposed to fuse the results of different systems. We achieve the final DER of 5.79% on the Eval set and 7.23% on the Test set. For Track 2, we develop our system using the Conformer model in a joint CTC-attention architecture. Serialized output training is adopted to multi-speaker overlapped speech recognition. We propose a neural front-end module to model multi-channel audio and train the model end-to-end. Various data augmentation methods are utilized to mitigate over-fitting in the multi-channel multi-speaker E2E system. Transformer language model fusion is developed to achieve better performance. The final CER is 19.2% on the Eval set and 20.8% on the Test set.