 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Synthesis Method of Safe Rust Code Based on Pushdown Colored Petri Nets
Apr 02, 2026Safe Rust guarantees memory safety through strict compile-time constraints: ownership can be transferred, borrowing can temporarily guarantee either shared read-only or exclusive write access, and ownership and borrowing are scoped by lifetime. Automatically synthesizing correct and safe Rust code is challenging, as the generated code must not only satisfy ownership, borrowing, and lifetime constraints, but also meet type and interface requirements at compile time. This work proposes a synthesis method based on our newly defined Pushdown Colored Petri Net (PCPN) that models these compilation constraints directly from public API signatures to synthesize valid call sequences. Token colors encode dynamic resource states together with a scope level indicating the lifetime region in which a borrow is valid. The pushdown stack tracks the entering or leaving of lifetime parameter via pushing and popping tokens. A transition is enabled only when type matching and interface obligations both hold and the required resource states are available. Based on the bisimulation theory, we prove that the enabling and firing rules of PCPN are consistent with the compile-time check of these three constraints. We develop an automatic synthesis tool based on PCPN and the experimental results show that the synthesized codes are all correct.
Global and Local Confidence Based Fraud Detection Graph Neural Network
Jul 24, 2024This paper presents the Global and Local Confidence Graph Neural Network (GLC-GNN), an innovative approach to graph-based anomaly detection that addresses the challenges of heterophily and camouflage in fraudulent activities. By introducing a prototype to encapsulate the global features of a graph and calculating a Global Confidence (GC) value for each node, GLC-GNN effectively distinguishes between benign and fraudulent nodes. The model leverages GC to generate attention values for message aggregation, enhancing its ability to capture both homophily and heterophily. Through extensive experiments on four open datasets, GLC-GNN demonstrates superior performance over state-of-the-art models in accuracy and convergence speed, while maintaining a compact model size and expedited training process. The integration of global and local confidence measures in GLC-GNN offers a robust solution for detecting anomalies in graphs, with significant implications for fraud detection across diverse domains.
Transaction Fraud Detection via Spatial-Temporal-Aware Graph Transformer
Jul 11, 2023



How to obtain informative representations of transactions and then perform the identification of fraudulent transactions is a crucial part of ensuring financial security. Recent studies apply Graph Neural Networks (GNNs) to the transaction fraud detection problem. Nevertheless, they encounter challenges in effectively learning spatial-temporal information due to structural limitations. Moreover, few prior GNN-based detectors have recognized the significance of incorporating global information, which encompasses similar behavioral patterns and offers valuable insights for discriminative representation learning. Therefore, we propose a novel heterogeneous graph neural network called Spatial-Temporal-Aware Graph Transformer (STA-GT) for transaction fraud detection problems. Specifically, we design a temporal encoding strategy to capture temporal dependencies and incorporate it into the graph neural network framework, enhancing spatial-temporal information modeling and improving expressive ability. Furthermore, we introduce a transformer module to learn local and global information. Pairwise node-node interactions overcome the limitation of the GNN structure and build up the interactions with the target node and long-distance ones. Experimental results on two financial datasets compared to general GNN models and GNN-based fraud detectors demonstrate that our proposed method STA-GT is effective on the transaction fraud detection task.
Transaction Fraud Detection via an Adaptive Graph Neural Network
Jul 11, 2023



Many machine learning methods have been proposed to achieve accurate transaction fraud detection, which is essential to the financial security of individuals and banks. However, most existing methods leverage original features only or require manual feature engineering. They lack the ability to learn discriminative representations from transaction data. Moreover, criminals often commit fraud by imitating cardholders' behaviors, which causes the poor performance of existing detection models. In this paper, we propose an Adaptive Sampling and Aggregation-based Graph Neural Network (ASA-GNN) that learns discriminative representations to improve the performance of transaction fraud detection. A neighbor sampling strategy is performed to filter noisy nodes and supplement information for fraudulent nodes. Specifically, we leverage cosine similarity and edge weights to adaptively select neighbors with similar behavior patterns for target nodes and then find multi-hop neighbors for fraudulent nodes. A neighbor diversity metric is designed by calculating the entropy among neighbors to tackle the camouflage issue of fraudsters and explicitly alleviate the over-smoothing phenomena. Extensive experiments on three real financial datasets demonstrate that the proposed method ASA-GNN outperforms state-of-the-art ones.
Enhancing the Robustness of QMIX against State-adversarial Attacks
Jul 03, 2023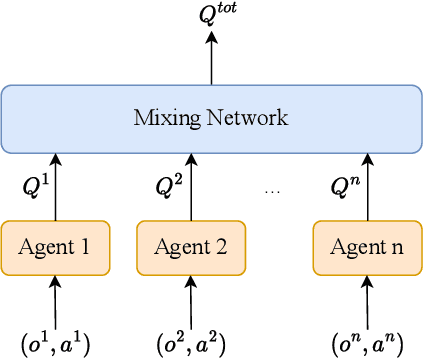
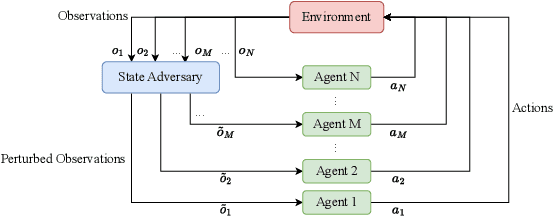
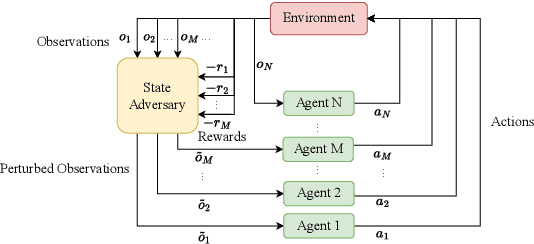
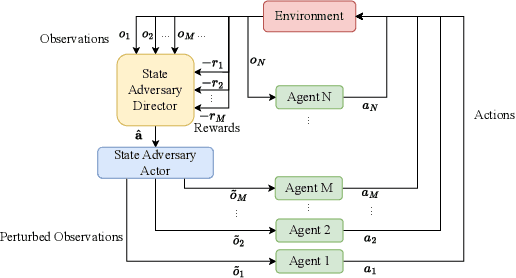
Deep reinforcement learning (DRL) performance is generally impacted by state-adversarial attacks, a perturbation applied to an agent's observation. Most recent research has concentrated on robust single-agent reinforcement learning (SARL) algorithms against state-adversarial attacks. Still, there has yet to be much work on robust multi-agent reinforcement learning. Using QMIX, one of the popular cooperative multi-agent reinforcement algorithms, as an example, we discuss four techniques to improve the robustness of SARL algorithms and extend them to multi-agent scenarios. To increase the robustness of multi-agent reinforcement learning (MARL) algorithms, we train models using a variety of attacks in this research. We then test the models taught using the other attacks by subjecting them to the corresponding attacks throughout the training phase. In this way, we organize and summarize techniques for enhancing robustness when used with MARL.
Robustness Testing for Multi-Agent Reinforcement Learning: State Perturbations on Critical Agents
Jun 09, 2023Multi-Agent Reinforcement Learning (MARL) has been widely applied in many fields such as smart traffic and unmanned aerial vehicles. However, most MARL algorithms are vulnerable to adversarial perturbations on agent states. Robustness testing for a trained model is an essential step for confirming the trustworthiness of the model against unexpected perturbations. This work proposes a novel Robustness Testing framework for MARL that attacks states of Critical Agents (RTCA). The RTCA has two innovations: 1) a Differential Evolution (DE) based method to select critical agents as victims and to advise the worst-case joint actions on them; and 2) a team cooperation policy evaluation method employed as the objective function for the optimization of DE. Then, adversarial state perturbations of the critical agents are generated based on the worst-case joint actions. This is the first robustness testing framework with varying victim agents. RTCA demonstrates outstanding performance in terms of the number of victim agents and destroying cooperation policies.
Multi-Agent Reinforcement Learning: Methods, Applications, Visionary Prospects, and Challenges
May 17, 2023
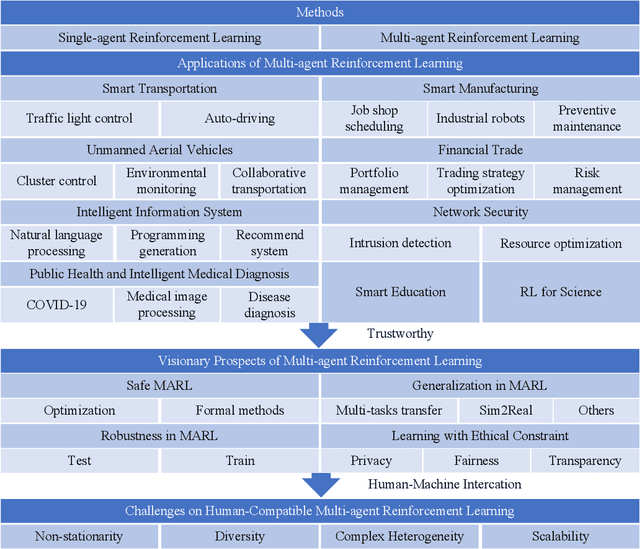


Multi-agent reinforcement learning (MARL) is a widely used Artificial Intelligence (AI) technique. However, current studies and applications need to address its scalability, non-stationarity, and trustworthiness. This paper aims to review methods and applications and point out research trends and visionary prospects for the next decade. First, this paper summarizes the basic methods and application scenarios of MARL. Second, this paper outlines the corresponding research methods and their limitations on safety, robustness, generalization, and ethical constraints that need to be addressed in the practical applications of MARL. In particular, we believe that trustworthy MARL will become a hot research topic in the next decade. In addition, we suggest that considering human interaction is essential for the practical application of MARL in various societies. Therefore, this paper also analyzes the challenges while MARL is applied to human-machine interaction.
Partially Observable Mean Field Multi-Agent Reinforcement Learning Based on Graph-Attention
Apr 25, 2023



Traditional multi-agent reinforcement learning algorithms are difficultly applied in a large-scale multi-agent environment. The introduction of mean field theory has enhanced the scalability of multi-agent reinforcement learning in recent years. This paper considers partially observable multi-agent reinforcement learning (MARL), where each agent can only observe other agents within a fixed range. This partial observability affects the agent's ability to assess the quality of the actions of surrounding agents. This paper focuses on developing a method to capture more effective information from local observations in order to select more effective actions. Previous work in this field employs probability distributions or weighted mean field to update the average actions of neighborhood agents, but it does not fully consider the feature information of surrounding neighbors and leads to a local optimum. In this paper, we propose a novel multi-agent reinforcement learning algorithm, Partially Observable Mean Field Multi-Agent Reinforcement Learning based on Graph--Attention (GAMFQ) to remedy this flaw. GAMFQ uses a graph attention module and a mean field module to describe how an agent is influenced by the actions of other agents at each time step. This graph attention module consists of a graph attention encoder and a differentiable attention mechanism, and this mechanism outputs a dynamic graph to represent the effectiveness of neighborhood agents against central agents. The mean--field module approximates the effect of a neighborhood agent on a central agent as the average effect of effective neighborhood agents. We evaluate GAMFQ on three challenging tasks in the MAgents framework. Experiments show that GAMFQ outperforms baselines including the state-of-the-art partially observable mean-field reinforcement learning algorithms.
RoMFAC: A Robust Mean-Field Actor-Critic Reinforcement Learning against Adversarial Perturbations on States
May 15, 2022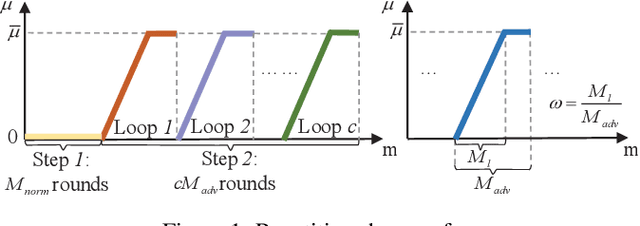
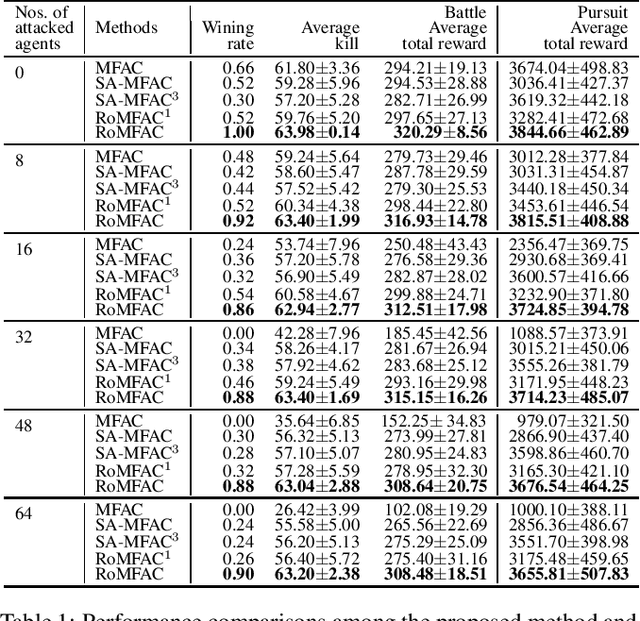
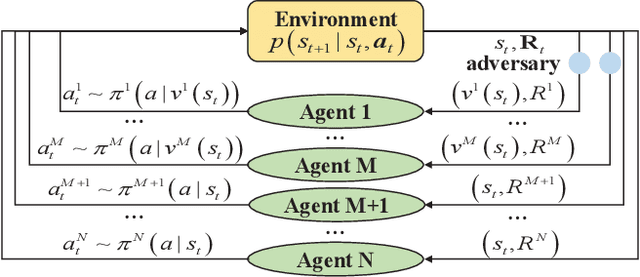
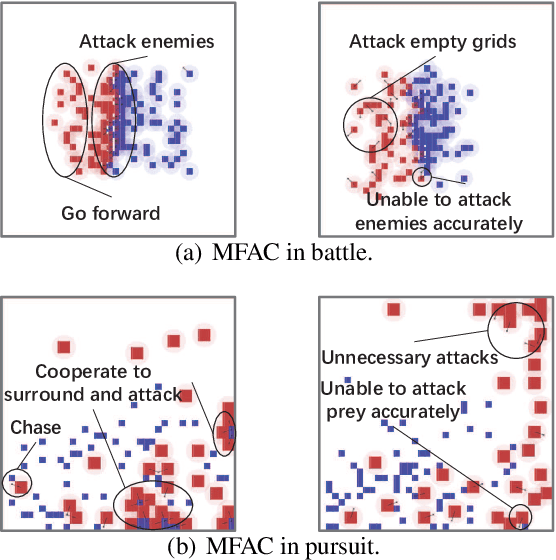
Deep reinforcement learning methods for multi-agent systems make optimal decisions dependent on states observed by agents, but a little uncertainty on the observations can possibly mislead agents into taking wrong actions. The mean-field actor-critic reinforcement learning (MFAC) is very famous in the multi-agent field since it can effectively handle the scalability problem. However, this paper finds that it is also sensitive to state perturbations which can significantly degrade the team rewards. This paper proposes a robust learning framework for MFAC called RoMFAC that has two innovations: 1) a new objective function of training actors, composed of a \emph{policy gradient function} that is related to the expected cumulative discount reward on sampled clean states and an \emph{action loss function} that represents the difference between actions taken on clean and adversarial states; and 2) a repetitive regularization of the action loss that ensures the trained actors obtain a good performance. Furthermore, we prove that the proposed action loss function is convergent. Experiments show that RoMFAC is robust against adversarial perturbations while maintaining its good performance in environments without perturbations.