 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoMFAC: A Robust Mean-Field Actor-Critic Reinforcement Learning against Adversarial Perturbations on States
Paper and Code
May 15, 2022
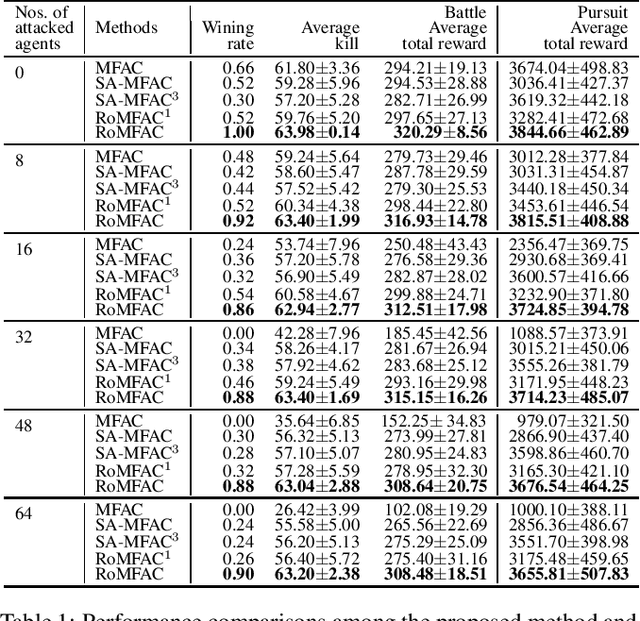
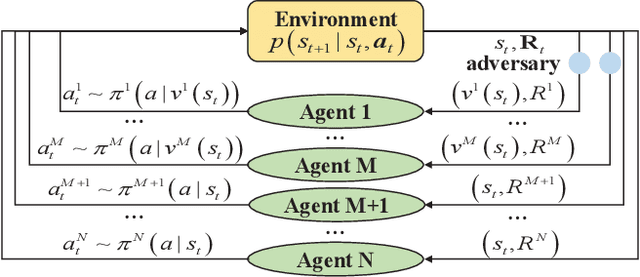
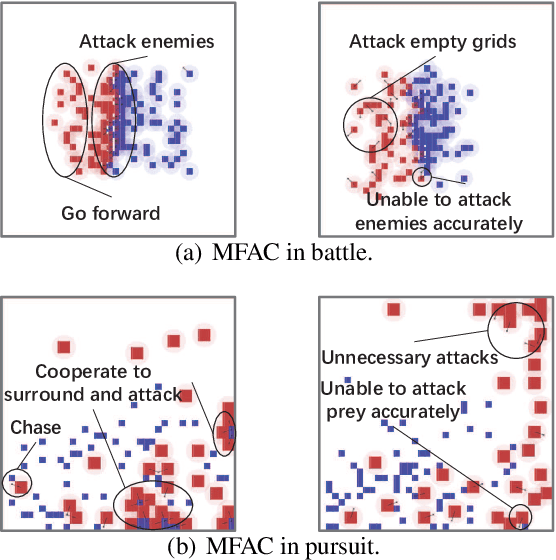
Deep reinforcement learning methods for multi-agent systems make optimal decisions dependent on states observed by agents, but a little uncertainty on the observations can possibly mislead agents into taking wrong actions. The mean-field actor-critic reinforcement learning (MFAC) is very famous in the multi-agent field since it can effectively handle the scalability problem. However, this paper finds that it is also sensitive to state perturbations which can significantly degrade the team rewards. This paper proposes a robust learning framework for MFAC called RoMFAC that has two innovations: 1) a new objective function of training actors, composed of a \emph{policy gradient function} that is related to the expected cumulative discount reward on sampled clean states and an \emph{action loss function} that represents the difference between actions taken on clean and adversarial states; and 2) a repetitive regularization of the action loss that ensures the trained actors obtain a good performance. Furthermore, we prove that the proposed action loss function is convergent. Experiments show that RoMFAC is robust against adversarial perturbations while maintaining its good performance in environments without perturbations.