 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Evolution and Future Perspectives of Artificial Intelligence Generated Content
Dec 02, 2024



Artificial intelligence generated content (AIGC), a rapidly advancing technology, is transforming content creation across domains, such as text, images, audio, and video. Its growing potential has attracted more and more researchers and investors to explore and expand its possibilities. This review traces AIGC's evolution through four developmental milestones-ranging from early rule-based systems to modern transfer learning models-within a unified framework that highlights how each milestone contributes uniquely to content generation. In particular, the paper employs a common example across all milestones to illustrate the capabilities and limitations of methods within each phase, providing a consistent evaluation of AIGC methodologies and their development. Furthermore, this paper addresses critical challenges associated with AIGC and proposes actionable strategies to mitigate them. This study aims to guide researchers and practitioners in selecting and optimizing AIGC models to enhance the quality and efficiency of content creation across diverse domains.
TL-CLIP: A Power-specific Multimodal Pre-trained Visual Foundation Model for Transmission Line Defect Recognition
Nov 18, 2024



Transmission line defect recognition models have traditionally used general pre-trained weights as the initial basis for their training. These models often suffer weak generalization capability due to the lack of domain knowledge in the pre-training dataset. To address this issue, we propose a two-stage transmission-line-oriented contrastive language-image pre-training (TL-CLIP) framework, which lays a more effective foundation for transmission line defect recognition. The pre-training process employs a novel power-specific multimodal algorithm assisted with two power-specific pre-training tasks for better modeling the power-related semantic knowledge contained in the inspection data. To fine-tune the pre-trained model, we develop a transfer learning strategy, namely fine-tuning with pre-training objective (FTP), to alleviate the overfitting problem caused by limited inspection data. Experimental results demonstrate that the proposed method significantly improves the performance of transmission line defect recognition in both classification and detection tasks, indicating clear advantages over traditional pre-trained models in the scene of transmission line inspection.
Transaction Fraud Detection via an Adaptive Graph Neural Network
Jul 11, 2023



Many machine learning methods have been proposed to achieve accurate transaction fraud detection, which is essential to the financial security of individuals and banks. However, most existing methods leverage original features only or require manual feature engineering. They lack the ability to learn discriminative representations from transaction data. Moreover, criminals often commit fraud by imitating cardholders' behaviors, which causes the poor performance of existing detection models. In this paper, we propose an Adaptive Sampling and Aggregation-based Graph Neural Network (ASA-GNN) that learns discriminative representations to improve the performance of transaction fraud detection. A neighbor sampling strategy is performed to filter noisy nodes and supplement information for fraudulent nodes. Specifically, we leverage cosine similarity and edge weights to adaptively select neighbors with similar behavior patterns for target nodes and then find multi-hop neighbors for fraudulent nodes. A neighbor diversity metric is designed by calculating the entropy among neighbors to tackle the camouflage issue of fraudsters and explicitly alleviate the over-smoothing phenomena. Extensive experiments on three real financial datasets demonstrate that the proposed method ASA-GNN outperforms state-of-the-art ones.
Enhancing the Robustness of QMIX against State-adversarial Attacks
Jul 03, 2023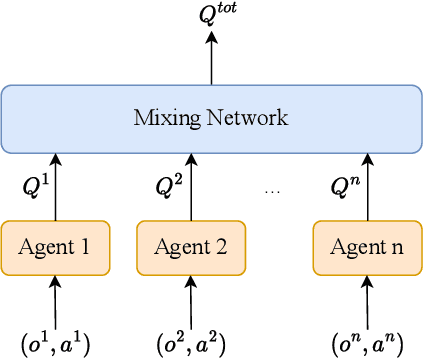
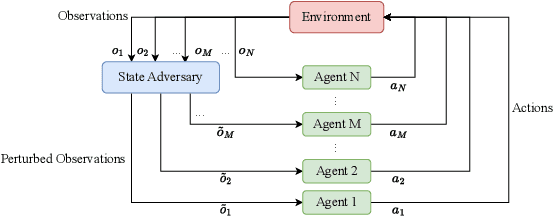
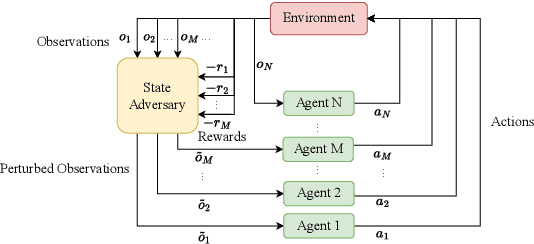
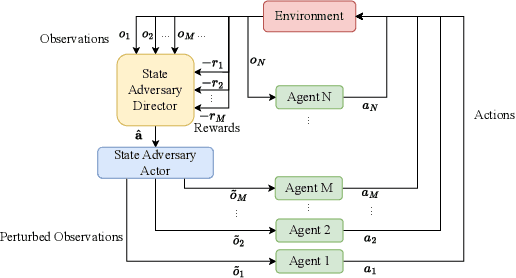
Deep reinforcement learning (DRL) performance is generally impacted by state-adversarial attacks, a perturbation applied to an agent's observation. Most recent research has concentrated on robust single-agent reinforcement learning (SARL) algorithms against state-adversarial attacks. Still, there has yet to be much work on robust multi-agent reinforcement learning. Using QMIX, one of the popular cooperative multi-agent reinforcement algorithms, as an example, we discuss four techniques to improve the robustness of SARL algorithms and extend them to multi-agent scenarios. To increase the robustness of multi-agent reinforcement learning (MARL) algorithms, we train models using a variety of attacks in this research. We then test the models taught using the other attacks by subjecting them to the corresponding attacks throughout the training phase. In this way, we organize and summarize techniques for enhancing robustness when used with MARL.