 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShow, Don't Tell: Morphing Latent Reasoning into Image Generation
Feb 02, 2026Text-to-image (T2I) generation has achieved remarkable progress, yet existing methods often lack the ability to dynamically reason and refine during generation--a hallmark of human creativity. Current reasoning-augmented paradigms most rely on explicit thought processes, where intermediate reasoning is decoded into discrete text at fixed steps with frequent image decoding and re-encoding, leading to inefficiencies, information loss, and cognitive mismatches. To bridge this gap, we introduce LatentMorph, a novel framework that seamlessly integrates implicit latent reasoning into the T2I generation process. At its core, LatentMorph introduces four lightweight components: (i) a condenser for summarizing intermediate generation states into compact visual memory, (ii) a translator for converting latent thoughts into actionable guidance, (iii) a shaper for dynamically steering next image token predictions, and (iv) an RL-trained invoker for adaptively determining when to invoke reasoning. By performing reasoning entirely in continuous latent spaces, LatentMorph avoids the bottlenecks of explicit reasoning and enables more adaptive self-refinement. Extensive experiments demonstrate that LatentMorph (I) enhances the base model Janus-Pro by $16\%$ on GenEval and $25\%$ on T2I-CompBench; (II) outperforms explicit paradigms (e.g., TwiG) by $15\%$ and $11\%$ on abstract reasoning tasks like WISE and IPV-Txt, (III) while reducing inference time by $44\%$ and token consumption by $51\%$; and (IV) exhibits $71\%$ cognitive alignment with human intuition on reasoning invocation.
A4-Agent: An Agentic Framework for Zero-Shot Affordance Reasoning
Dec 16, 2025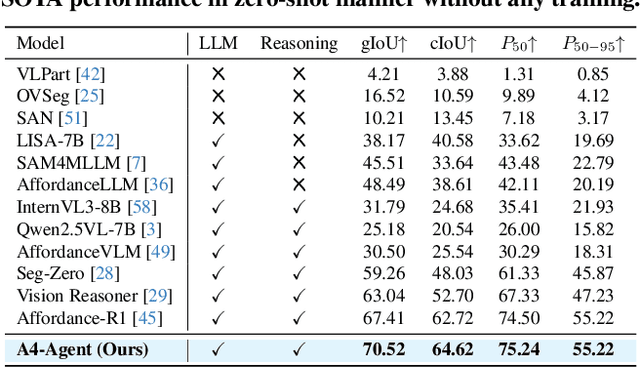
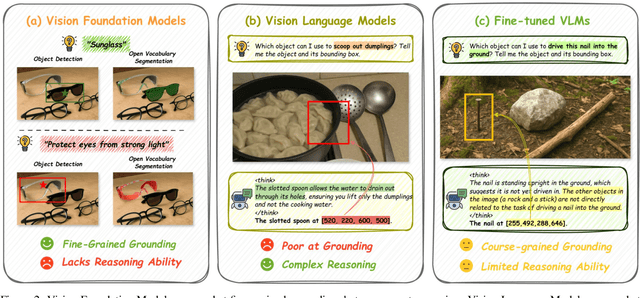
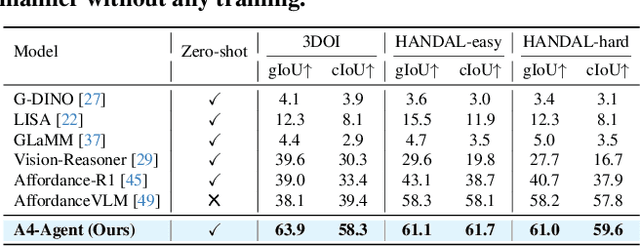
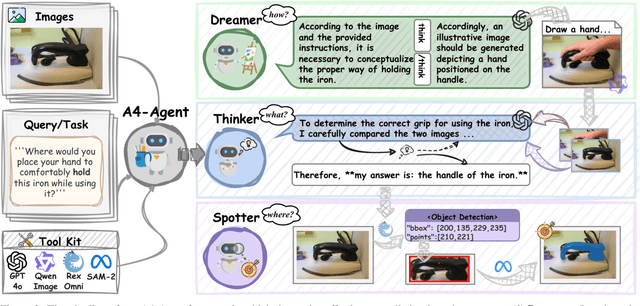
Affordance prediction, which identifies interaction regions on objects based on language instructions, is critical for embodied AI. Prevailing end-to-end models couple high-level reasoning and low-level grounding into a single monolithic pipeline and rely on training over annotated datasets, which leads to poor generalization on novel objects and unseen environments. In this paper, we move beyond this paradigm by proposing A4-Agent, a training-free agentic framework that decouples affordance prediction into a three-stage pipeline. Our framework coordinates specialized foundation models at test time: (1) a $\textbf{Dreamer}$ that employs generative models to visualize $\textit{how}$ an interaction would look; (2) a $\textbf{Thinker}$ that utilizes large vision-language models to decide $\textit{what}$ object part to interact with; and (3) a $\textbf{Spotter}$ that orchestrates vision foundation models to precisely locate $\textit{where}$ the interaction area is. By leveraging the complementary strengths of pre-trained models without any task-specific fine-tuning, our zero-shot framework significantly outperforms state-of-the-art supervised methods across multiple benchmarks and demonstrates robust generalization to real-world settings.
PresentCoach: Dual-Agent Presentation Coaching through Exemplars and Interactive Feedback
Nov 19, 2025Effective presentation skills are essential in education, professional communication, and public speaking, yet learners often lack access to high-quality exemplars or personalized coaching. Existing AI tools typically provide isolated functionalities such as speech scoring or script generation without integrating reference modeling and interactive feedback into a cohesive learning experience. We introduce a dual-agent system that supports presentation practice through two complementary roles: the Ideal Presentation Agent and the Coach Agent. The Ideal Presentation Agent converts user-provided slides into model presentation videos by combining slide processing, visual-language analysis, narration script generation, personalized voice synthesis, and synchronized video assembly. The Coach Agent then evaluates user-recorded presentations against these exemplars, conducting multimodal speech analysis and delivering structured feedback in an Observation-Impact-Suggestion (OIS) format. To enhance the authenticity of the learning experience, the Coach Agent incorporates an Audience Agent, which simulates the perspective of a human listener and provides humanized feedback reflecting audience reactions and engagement. Together, these agents form a closed loop of observation, practice, and feedback. Implemented on a robust backend with multi-model integration, voice cloning, and error handling mechanisms, the system demonstrates how AI-driven agents can provide engaging, human-centered, and scalable support for presentation skill development in both educational and professional contexts.
PhysToolBench: Benchmarking Physical Tool Understanding for MLLMs
Oct 10, 2025The ability to use, understand, and create tools is a hallmark of human intelligence, enabling sophisticated interaction with the physical world. For any general-purpose intelligent agent to achieve true versatility, it must also master these fundamental skills. While modern Multimodal Large Language Models (MLLMs) leverage their extensive common knowledge for high-level planning in embodied AI and in downstream Vision-Language-Action (VLA) models, the extent of their true understanding of physical tools remains unquantified. To bridge this gap, we present PhysToolBench, the first benchmark dedicated to evaluating the comprehension of physical tools by MLLMs. Our benchmark is structured as a Visual Question Answering (VQA) dataset comprising over 1,000 image-text pairs. It assesses capabilities across three distinct difficulty levels: (1) Tool Recognition: Requiring the recognition of a tool's primary function. (2) Tool Understanding: Testing the ability to grasp the underlying principles of a tool's operation. (3) Tool Creation: Challenging the model to fashion a new tool from surrounding objects when conventional options are unavailable. Our comprehensive evaluation of 32 MLLMs-spanning proprietary, open-source, specialized embodied, and backbones in VLAs-reveals a significant deficiency in tool understanding. Furthermore, we provide an in-depth analysis and propose preliminary solutions. Code and dataset are publicly available.
Enhancing Vector Quantization with Distributional Matching: A Theoretical and Empirical Study
Jun 18, 2025The success of autoregressive models largely depends on the effectiveness of vector quantization, a technique that discretizes continuous features by mapping them to the nearest code vectors within a learnable codebook. Two critical issues in existing vector quantization methods are training instability and codebook collapse. Training instability arises from the gradient discrepancy introduced by the straight-through estimator, especially in the presence of significant quantization errors, while codebook collapse occurs when only a small subset of code vectors are utilized during training. A closer examination of these issues reveals that they are primarily driven by a mismatch between the distributions of the features and code vectors, leading to unrepresentative code vectors and significant data information loss during compression. To address this, we employ the Wasserstein distance to align these two distributions, achieving near 100\% codebook utilization and significantly reducing the quantization error. Both empirical and theoretical analyses validate the effectiveness of the proposed approach.
ComfyMind: Toward General-Purpose Generation via Tree-Based Planning and Reactive Feedback
May 23, 2025With the rapid advancement of generative models, general-purpose generation has gained increasing attention as a promising approach to unify diverse tasks across modalities within a single system. Despite this progress, existing open-source frameworks often remain fragile and struggle to support complex real-world applications due to the lack of structured workflow planning and execution-level feedback. To address these limitations, we present ComfyMind, a collaborative AI system designed to enable robust and scalable general-purpose generation, built on the ComfyUI platform. ComfyMind introduces two core innovations: Semantic Workflow Interface (SWI) that abstracts low-level node graphs into callable functional modules described in natural language, enabling high-level composition and reducing structural errors; Search Tree Planning mechanism with localized feedback execution, which models generation as a hierarchical decision process and allows adaptive correction at each stage. Together, these components improve the stability and flexibility of complex generative workflows. We evaluate ComfyMind on three public benchmarks: ComfyBench, GenEval, and Reason-Edit, which span generation, editing, and reasoning tasks. Results show that ComfyMind consistently outperforms existing open-source baselines and achieves performance comparable to GPT-Image-1. ComfyMind paves a promising path for the development of open-source general-purpose generative AI systems. Project page: https://github.com/LitaoGuo/ComfyMind
Make-A-Storyboard: A General Framework for Storyboard with Disentangled and Merged Control
Dec 06, 2023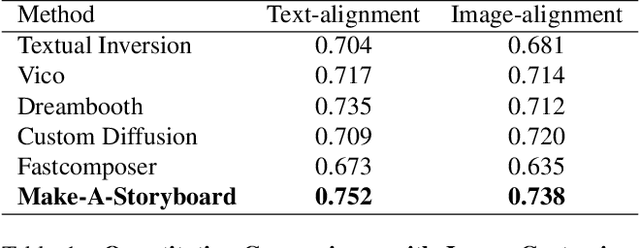
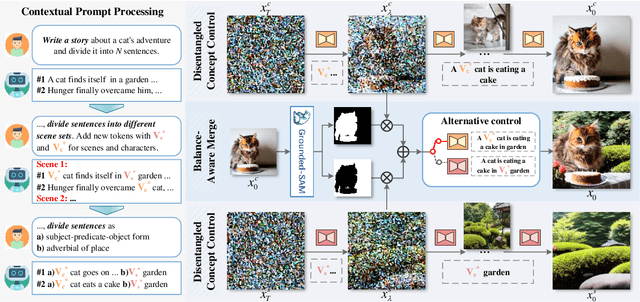


Story Visualization aims to generate images aligned with story prompts, reflecting the coherence of storybooks through visual consistency among characters and scenes.Whereas current approaches exclusively concentrate on characters and neglect the visual consistency among contextually correlated scenes, resulting in independent character images without inter-image coherence.To tackle this issue, we propose a new presentation form for Story Visualization called Storyboard, inspired by film-making, as illustrated in Fig.1.Specifically, a Storyboard unfolds a story into visual representations scene by scene. Within each scene in Storyboard, characters engage in activities at the same location, necessitating both visually consistent scenes and characters.For Storyboard, we design a general framework coined as Make-A-Storyboard that applies disentangled control over the consistency of contextual correlated characters and scenes and then merge them to form harmonized images.Extensive experiments demonstrate 1) Effectiveness.the effectiveness of the method in story alignment, character consistency, and scene correlation; 2) Generalization. Our method could be seamlessly integrated into mainstream Image Customization methods, empowering them with the capability of story visualization.
MotionZero:Exploiting Motion Priors for Zero-shot Text-to-Video Generation
Nov 28, 2023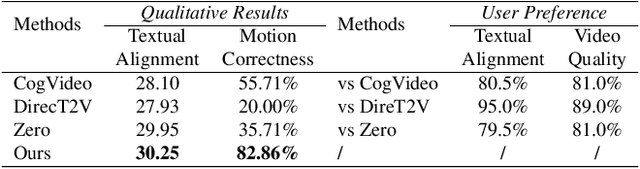
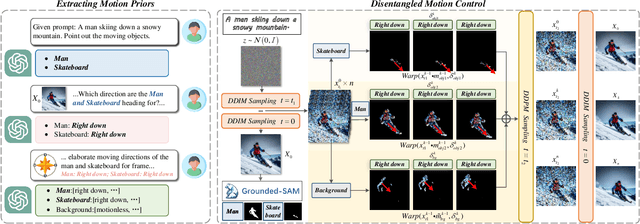
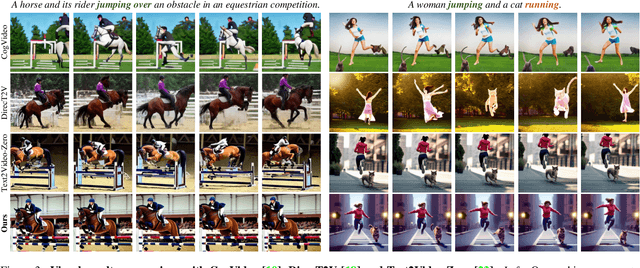

Zero-shot Text-to-Video synthesis generates videos based on prompts without any videos. Without motion information from videos, motion priors implied in prompts are vital guidance. For example, the prompt "airplane landing on the runway" indicates motion priors that the "airplane" moves downwards while the "runway" stays static. Whereas the motion priors are not fully exploited in previous approaches, thus leading to two nontrivial issues: 1) the motion variation pattern remains unaltered and prompt-agnostic for disregarding motion priors; 2) the motion control of different objects is inaccurate and entangled without considering the independent motion priors of different objects. To tackle the two issues, we propose a prompt-adaptive and disentangled motion control strategy coined as MotionZero, which derives motion priors from prompts of different objects by Large-Language-Models and accordingly applies motion control of different objects to corresponding regions in disentanglement. Furthermore, to facilitate videos with varying degrees of motion amplitude, we propose a Motion-Aware Attention scheme which adjusts attention among frames by motion amplitude. Extensive experiments demonstrate that our strategy could correctly control motion of different objects and support versatile applications including zero-shot video edit.