 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotionZero:Exploiting Motion Priors for Zero-shot Text-to-Video Generation
Paper and Code
Nov 28, 2023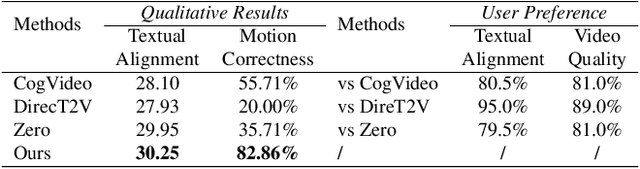
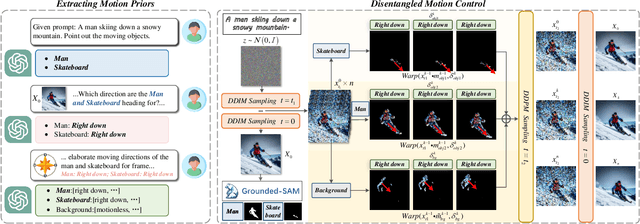
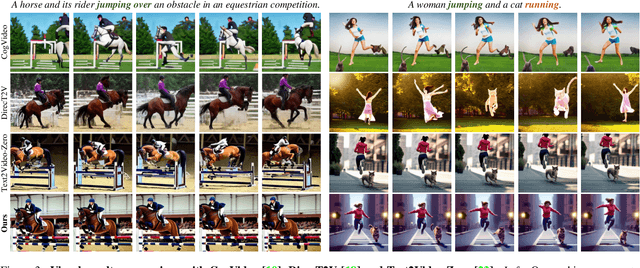

Zero-shot Text-to-Video synthesis generates videos based on prompts without any videos. Without motion information from videos, motion priors implied in prompts are vital guidance. For example, the prompt "airplane landing on the runway" indicates motion priors that the "airplane" moves downwards while the "runway" stays static. Whereas the motion priors are not fully exploited in previous approaches, thus leading to two nontrivial issues: 1) the motion variation pattern remains unaltered and prompt-agnostic for disregarding motion priors; 2) the motion control of different objects is inaccurate and entangled without considering the independent motion priors of different objects. To tackle the two issues, we propose a prompt-adaptive and disentangled motion control strategy coined as MotionZero, which derives motion priors from prompts of different objects by Large-Language-Models and accordingly applies motion control of different objects to corresponding regions in disentanglement. Furthermore, to facilitate videos with varying degrees of motion amplitude, we propose a Motion-Aware Attention scheme which adjusts attention among frames by motion amplitude. Extensive experiments demonstrate that our strategy could correctly control motion of different objects and support versatile applications including zero-shot video edit.