 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedverse: A Universal Model for Full-Resolution 3D Medical Image Segmentation, Transformation and Enhancement
Sep 11, 2025In-context learning (ICL) offers a promising paradigm for universal medical image analysis, enabling models to perform diverse image processing tasks without retraining. However, current ICL models for medical imaging remain limited in two critical aspects: they cannot simultaneously achieve high-fidelity predictions and global anatomical understanding, and there is no unified model trained across diverse medical imaging tasks (e.g., segmentation and enhancement) and anatomical regions. As a result, the full potential of ICL in medical imaging remains underexplored. Thus, we present \textbf{Medverse}, a universal ICL model for 3D medical imaging, trained on 22 datasets covering diverse tasks in universal image segmentation, transformation, and enhancement across multiple organs, imaging modalities, and clinical centers. Medverse employs a next-scale autoregressive in-context learning framework that progressively refines predictions from coarse to fine, generating consistent, full-resolution volumetric outputs and enabling multi-scale anatomical awareness. We further propose a blockwise cross-attention module that facilitates long-range interactions between context and target inputs while preserving computational efficiency through spatial sparsity. Medverse is extensively evaluated on a broad collection of held-out datasets covering previously unseen clinical centers, organs, species, and imaging modalities. Results demonstrate that Medverse substantially outperforms existing ICL baselines and establishes a novel paradigm for in-context learning. Code and model weights will be made publicly available. Our model are publicly available at https://github.com/jiesihu/Medverse.
DLTTA: Dynamic Learning Rate for Test-time Adaptation on Cross-domain Medical Images
May 27, 2022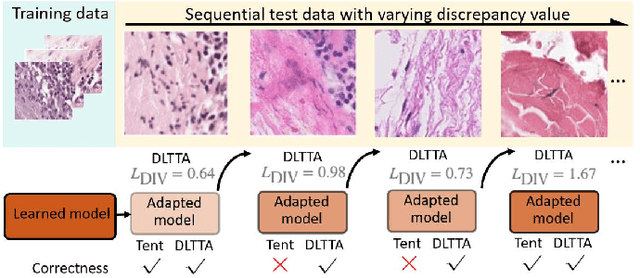
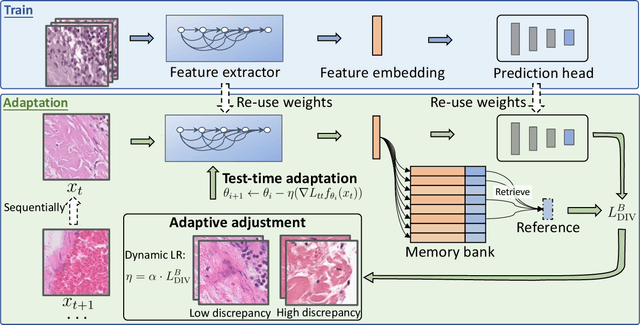
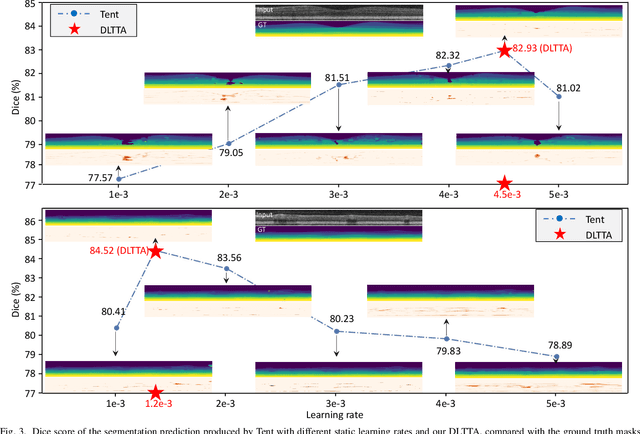
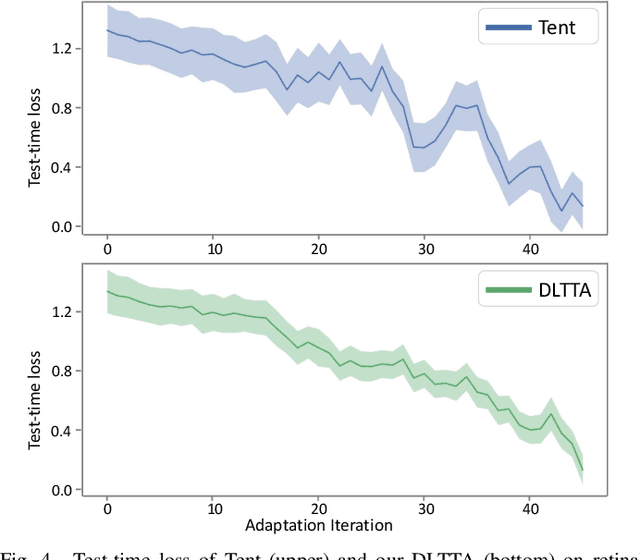
Test-time adaptation (TTA) has increasingly been an important topic to efficiently tackle the cross-domain distribution shift at test time for medical images from different institutions. Previous TTA methods have a common limitation of using a fixed learning rate for all the test samples. Such a practice would be sub-optimal for TTA, because test data may arrive sequentially therefore the scale of distribution shift would change frequently. To address this problem, we propose a novel dynamic learning rate adjustment method for test-time adaptation, called DLTTA, which dynamically modulates the amount of weights update for each test image to account for the differences in their distribution shift. Specifically, our DLTTA is equipped with a memory bank based estimation scheme to effectively measure the discrepancy of a given test sample. Based on this estimated discrepancy, a dynamic learning rate adjustment strategy is then developed to achieve a suitable degree of adaptation for each test sample. The effectiveness and general applicability of our DLTTA is extensively demonstrated on three tasks including retinal optical coherence tomography (OCT) segmentation, histopathological image classification, and prostate 3D MRI segmentation. Our method achieves effective and fast test-time adaptation with consistent performance improvement over current state-of-the-art test-time adaptation methods. Code is available at: https://github.com/med-air/DLTTA.
Integrating Artificial Intelligence and Augmented Reality in Robotic Surgery: An Initial dVRK Study Using a Surgical Education Scenario
Jan 02, 2022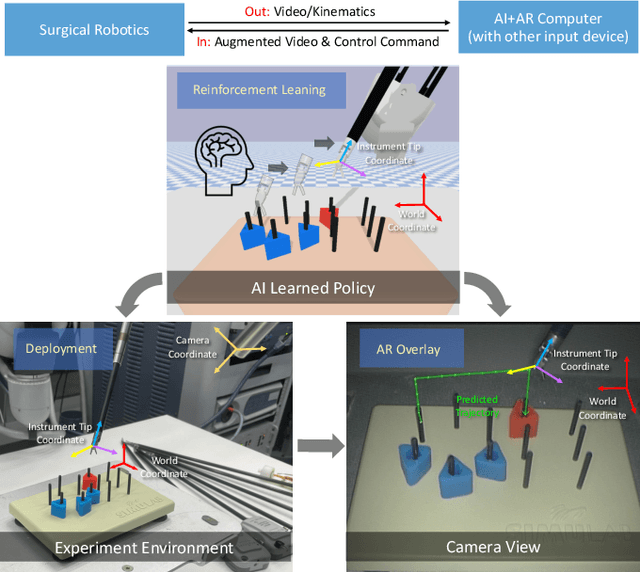
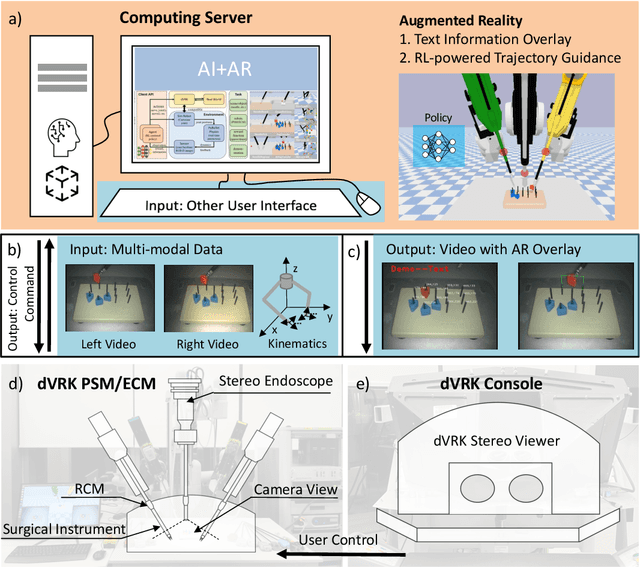

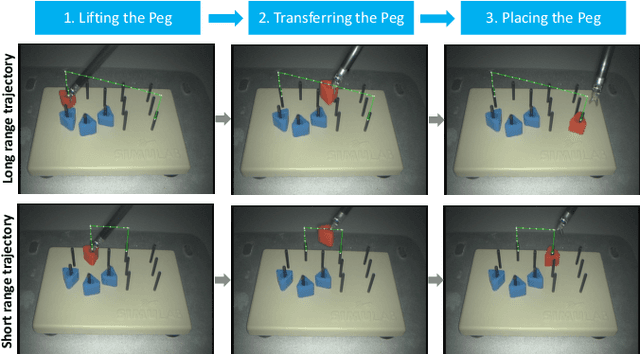
The demand of competent robot assisted surgeons is progressively expanding, because robot-assisted surgery has become progressively more popular due to its clinical advantages. To meet this demand and provide a better surgical education for surgeon, we develop a novel robotic surgery education system by integrating artificial intelligence surgical module and augmented reality visualization. The artificial intelligence incorporates reinforcement leaning to learn from expert demonstration and then generate 3D guidance trajectory, providing surgical context awareness of the complete surgical procedure. The trajectory information is further visualized in stereo viewer in the dVRK along with other information such as text hint, where the user can perceive the 3D guidance and learn the procedure. The proposed system is evaluated through a preliminary experiment on surgical education task peg-transfer, which proves its feasibility and potential as the next generation of robot-assisted surgery education solution.
Instance segmentation with the number of clusters incorporated in embedding learning
Mar 27, 2021
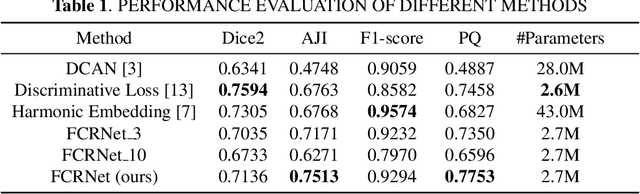
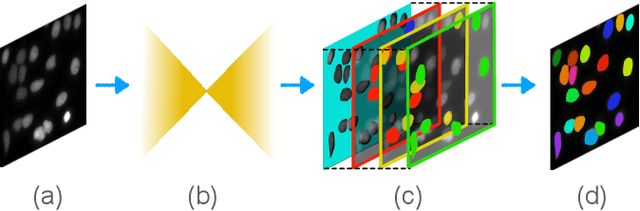
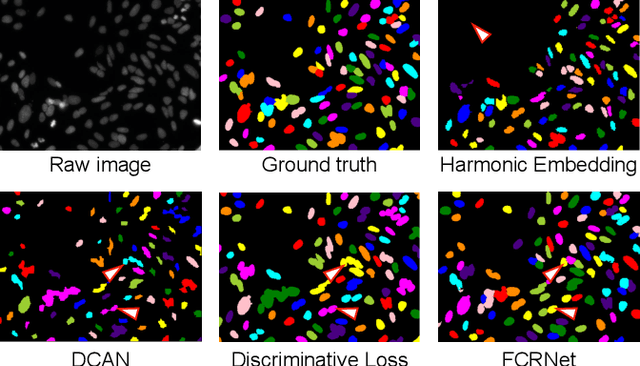
Semantic and instance segmentation algorithms are two general yet distinct image segmentation solutions powered by Convolution Neural Network. While semantic segmentation benefits extensively from the end-to-end training strategy, instance segmentation is frequently framed as a multi-stage task, supported by learning-based discrimination and post-process clustering. Independent optimizations on substages instigate the accumulation of segmentation errors. In this work, we propose to embed prior clustering information into an embedding learning framework FCRNet, stimulating the one-stage instance segmentation. FCRNet relieves the complexity of post process by incorporating the number of clustering groups into the embedding space. The superior performance of FCRNet is verified and compared with other methods on the nucleus dataset BBBC006.