 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounded Knowledge-Enhanced Medical VLP for Chest X-Ray
Apr 23, 2024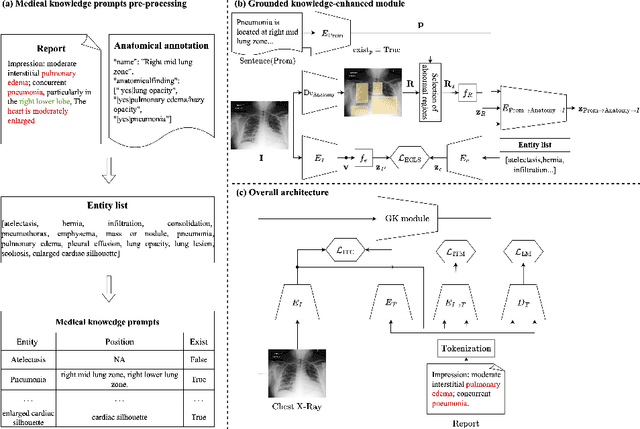
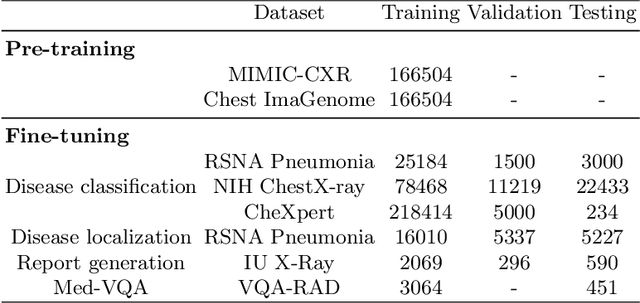
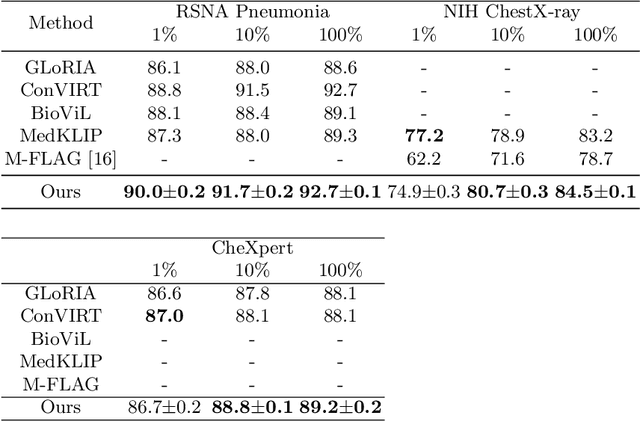
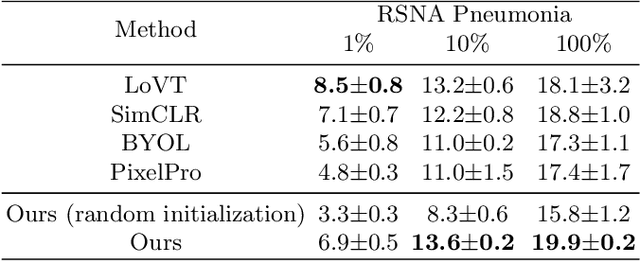
Medical vision-language pre-training has emerged as a promising approach for learning domain-general representations of medical image and text. Current algorithms that exploit the global and local alignment between medical image and text could however be marred by the redundant information in medical data. To address this issue, we propose a grounded knowledge-enhanced medical vision-language pre-training (GK-MVLP) framework for chest X-ray. In this framework, medical knowledge is grounded to the appropriate anatomical regions by using a transformer-based grounded knowledge-enhanced module for fine-grained alignment between anatomical region-level visual features and the textural features of medical knowledge. The performance of GK-MVLP is competitive with or exceeds the state of the art on downstream chest X-ray disease classification, disease localization, report generation, and medical visual question-answering tasks. Our results show the advantage of incorporating grounding mechanism to remove biases and improve the alignment between chest X-ray image and radiology report.