 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross Prompting Consistency with Segment Anything Model for Semi-supervised Medical Image Segmentation
Jul 07, 2024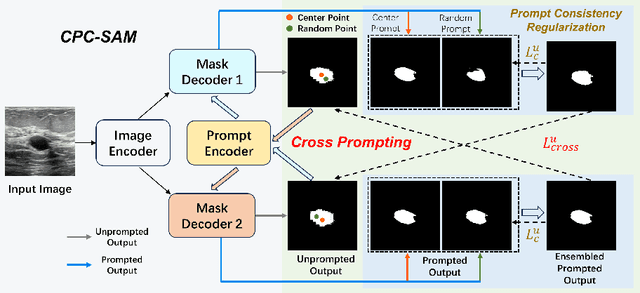
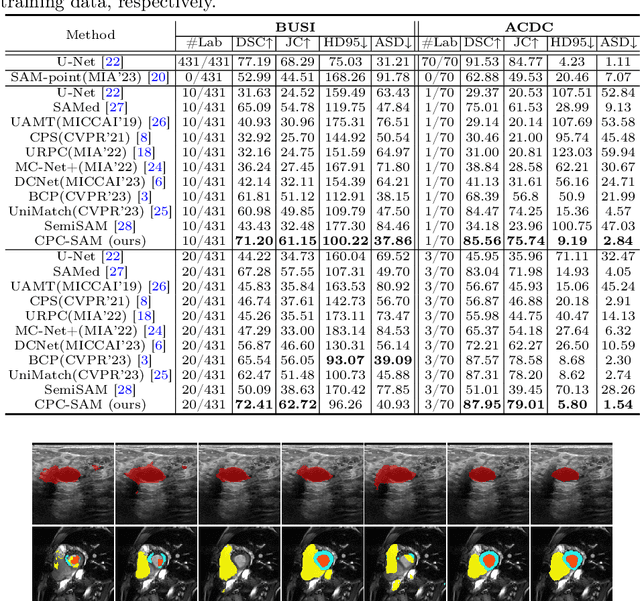
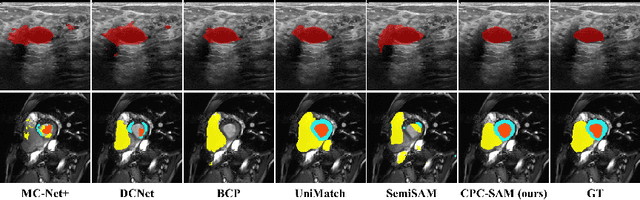

Semi-supervised learning (SSL) has achieved notable progress in medical image segmentation. To achieve effective SSL, a model needs to be able to efficiently learn from limited labeled data and effectively exploiting knowledge from abundant unlabeled data. Recent developments in visual foundation models, such as the Segment Anything Model (SAM), have demonstrated remarkable adaptability with improved sample efficiency. To harness the power of foundation models for application in SSL, we propose a cross prompting consistency method with segment anything model (CPC-SAM) for semi-supervised medical image segmentation. Our method employs SAM's unique prompt design and innovates a cross-prompting strategy within a dual-branch framework to automatically generate prompts and supervisions across two decoder branches, enabling effectively learning from both scarce labeled and valuable unlabeled data. We further design a novel prompt consistency regularization, to reduce the prompt position sensitivity and to enhance the output invariance under different prompts. We validate our method on two medical image segmentation tasks. The extensive experiments with different labeled-data ratios and modalities demonstrate the superiority of our proposed method over the state-of-the-art SSL methods, with more than 9% Dice improvement on the breast cancer segmentation task.
FM-OSD: Foundation Model-Enabled One-Shot Detection of Anatomical Landmarks
Jul 07, 2024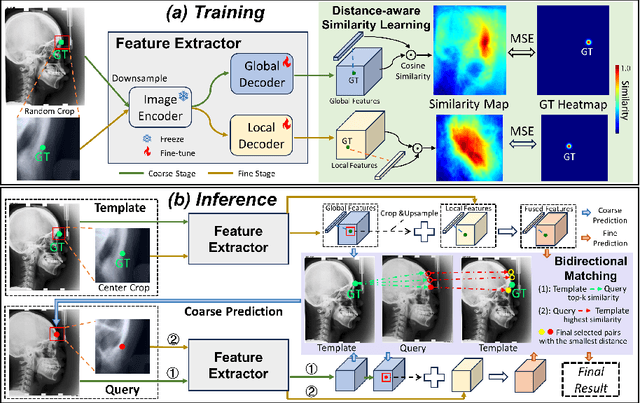
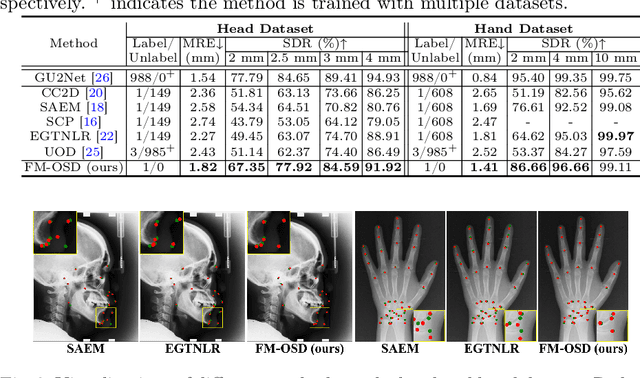

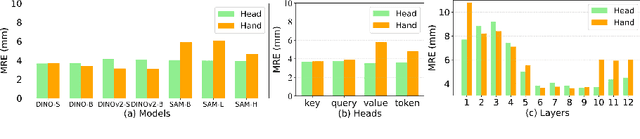
One-shot detection of anatomical landmarks is gaining significant attention for its efficiency in using minimal labeled data to produce promising results. However, the success of current methods heavily relies on the employment of extensive unlabeled data to pre-train an effective feature extractor, which limits their applicability in scenarios where a substantial amount of unlabeled data is unavailable. In this paper, we propose the first foundation model-enabled one-shot landmark detection (FM-OSD) framework for accurate landmark detection in medical images by utilizing solely a single template image without any additional unlabeled data. Specifically, we use the frozen image encoder of visual foundation models as the feature extractor, and introduce dual-branch global and local feature decoders to increase the resolution of extracted features in a coarse to fine manner. The introduced feature decoders are efficiently trained with a distance-aware similarity learning loss to incorporate domain knowledge from the single template image. Moreover, a novel bidirectional matching strategy is developed to improve both robustness and accuracy of landmark detection in the case of scattered similarity map obtained by foundation models. We validate our method on two public anatomical landmark detection datasets. By using solely a single template image, our method demonstrates significant superiority over strong state-of-the-art one-shot landmark detection methods.
Efficient Bayesian Optimization with Deep Kernel Learning and Transformer Pre-trained on Multiple Heterogeneous Datasets
Aug 09, 2023



Bayesian optimization (BO) is widely adopted in black-box optimization problems and it relies on a surrogate model to approximate the black-box response function. With the increasing number of black-box optimization tasks solved and even more to solve, the ability to learn from multiple prior tasks to jointly pre-train a surrogate model is long-awaited to further boost optimization efficiency. In this paper, we propose a simple approach to pre-train a surrogate, which is a Gaussian process (GP) with a kernel defined on deep features learned from a Transformer-based encoder, using datasets from prior tasks with possibly heterogeneous input spaces. In addition, we provide a simple yet effective mix-up initialization strategy for input tokens corresponding to unseen input variables and therefore accelerate new tasks' convergence. Experiments on both synthetic and real benchmark problems demonstrate the effectiveness of our proposed pre-training and transfer BO strategy over existing methods.
Neighbor Auto-Grouping Graph Neural Networks for Handover Parameter Configuration in Cellular Network
Dec 29, 2022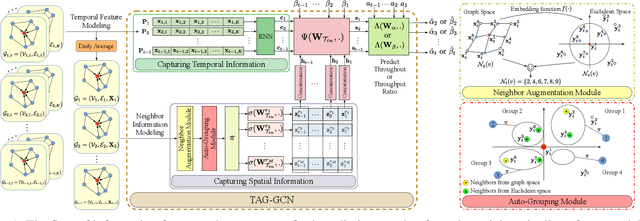

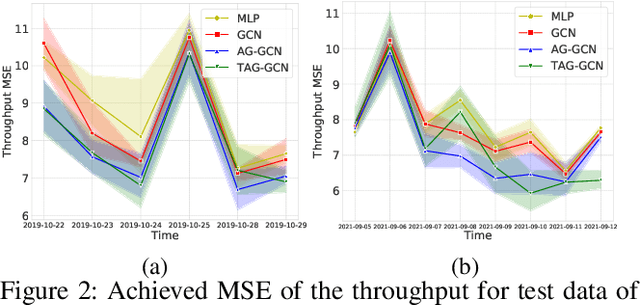
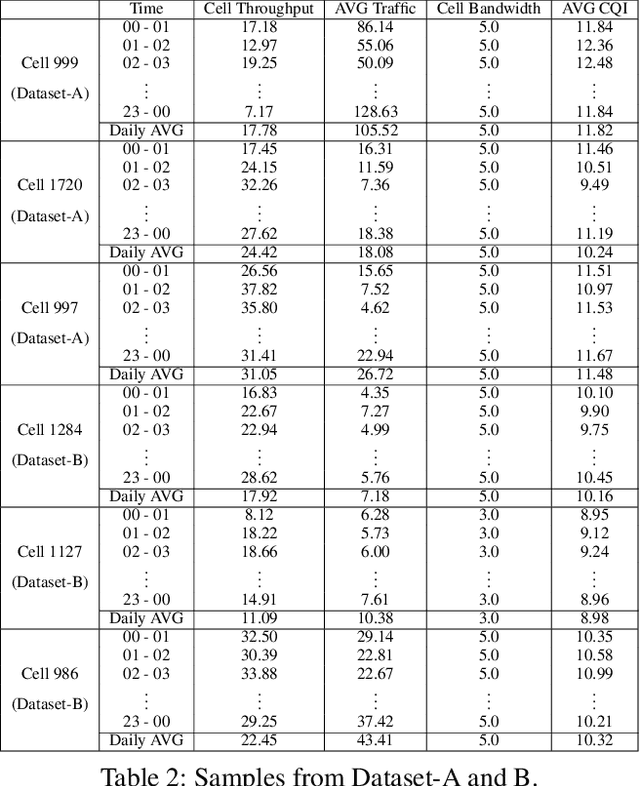
The mobile communication enabled by cellular networks is the one of the main foundations of our modern society. Optimizing the performance of cellular networks and providing massive connectivity with improved coverage and user experience has a considerable social and economic impact on our daily life. This performance relies heavily on the configuration of the network parameters. However, with the massive increase in both the size and complexity of cellular networks, network management, especially parameter configuration, is becoming complicated. The current practice, which relies largely on experts' prior knowledge, is not adequate and will require lots of domain experts and high maintenance costs. In this work, we propose a learning-based framework for handover parameter configuration. The key challenge, in this case, is to tackle the complicated dependencies between neighboring cells and jointly optimize the whole network. Our framework addresses this challenge in two ways. First, we introduce a novel approach to imitate how the network responds to different network states and parameter values, called auto-grouping graph convolutional network (AG-GCN). During the parameter configuration stage, instead of solving the global optimization problem, we design a local multi-objective optimization strategy where each cell considers several local performance metrics to balance its own performance and its neighbors. We evaluate our proposed algorithm via a simulator constructed using real network data. We demonstrate that the handover parameters our model can find, achieve better average network throughput compared to those recommended by experts as well as alternative baselines, which can bring better network quality and stability. It has the potential to massively reduce costs arising from human expert intervention and maintenance.
Kernel-based Multi-Task Contextual Bandits in Cellular Network Configuration
Nov 27, 2018

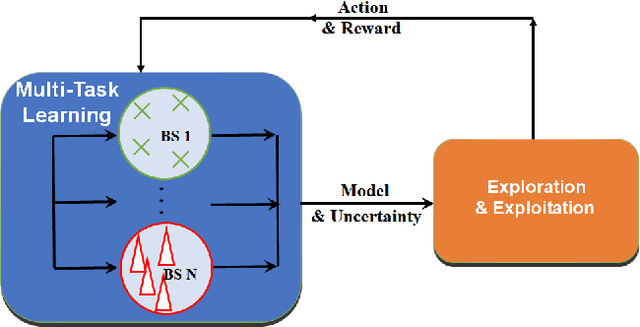
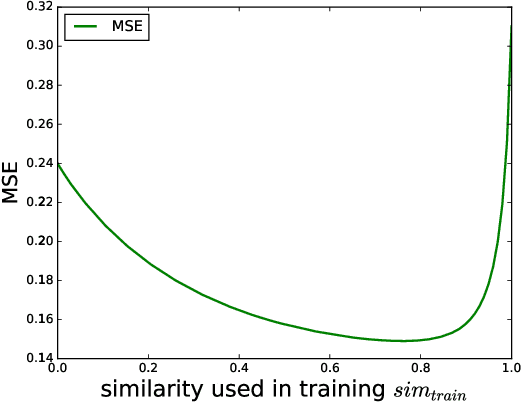
Cellular network configuration plays a critical role in network performance. In current practice, network configuration depends heavily on field experience of engineers and often remains static for a long period of time. This practice is far from optimal. To address this limitation, online-learning-based approaches have great potentials to automate and optimize network configuration. Learning-based approaches face the challenges of learning a highly complex function for each base station and balancing the fundamental exploration-exploitation tradeoff while minimizing the exploration cost. Fortunately, in cellular networks, base stations (BSs) often have similarities even though they are not identical. To leverage such similarities, we propose kernel-based multi-BS contextual bandit algorithm based on multi-task learning. In the algorithm, we leverage the similarity among different BSs defined by conditional kernel embedding. We present theoretical analysis of the proposed algorithm in terms of regret and multi-task-learning efficiency. We evaluate the effectiveness of our algorithm based on a simulator built by real traces.