 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeighbor Auto-Grouping Graph Neural Networks for Handover Parameter Configuration in Cellular Network
Dec 29, 2022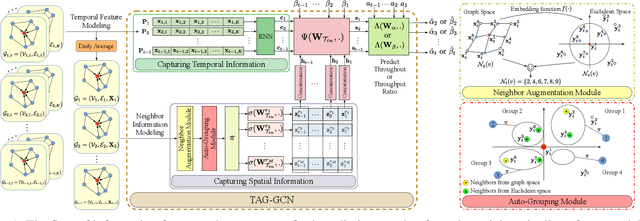

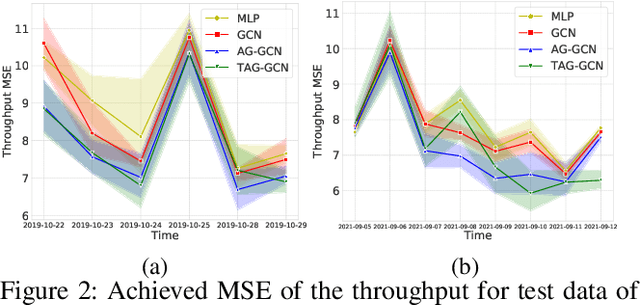
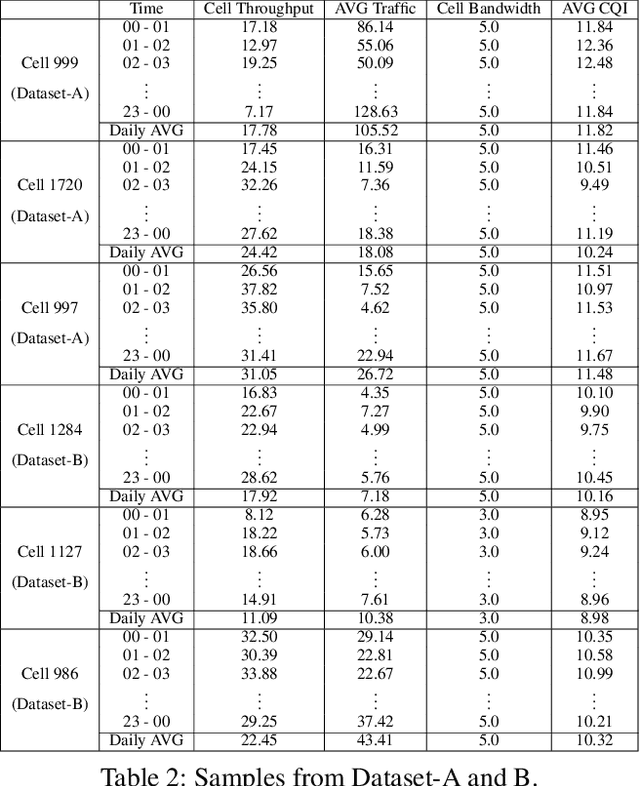
The mobile communication enabled by cellular networks is the one of the main foundations of our modern society. Optimizing the performance of cellular networks and providing massive connectivity with improved coverage and user experience has a considerable social and economic impact on our daily life. This performance relies heavily on the configuration of the network parameters. However, with the massive increase in both the size and complexity of cellular networks, network management, especially parameter configuration, is becoming complicated. The current practice, which relies largely on experts' prior knowledge, is not adequate and will require lots of domain experts and high maintenance costs. In this work, we propose a learning-based framework for handover parameter configuration. The key challenge, in this case, is to tackle the complicated dependencies between neighboring cells and jointly optimize the whole network. Our framework addresses this challenge in two ways. First, we introduce a novel approach to imitate how the network responds to different network states and parameter values, called auto-grouping graph convolutional network (AG-GCN). During the parameter configuration stage, instead of solving the global optimization problem, we design a local multi-objective optimization strategy where each cell considers several local performance metrics to balance its own performance and its neighbors. We evaluate our proposed algorithm via a simulator constructed using real network data. We demonstrate that the handover parameters our model can find, achieve better average network throughput compared to those recommended by experts as well as alternative baselines, which can bring better network quality and stability. It has the potential to massively reduce costs arising from human expert intervention and maintenance.
Activity Detection for Grant-Free NOMA in Massive IoT Networks
Dec 23, 2022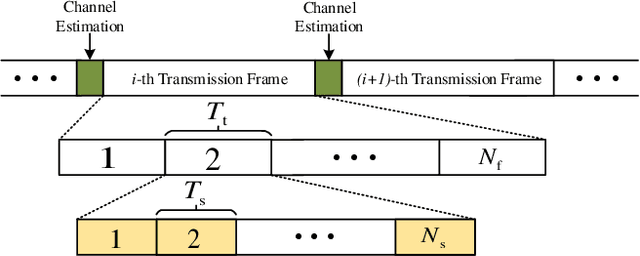

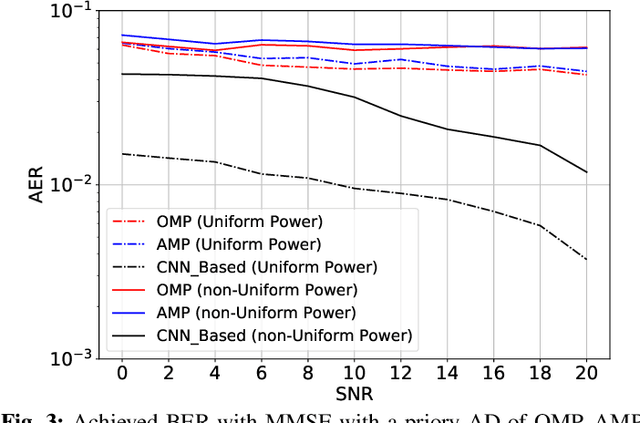
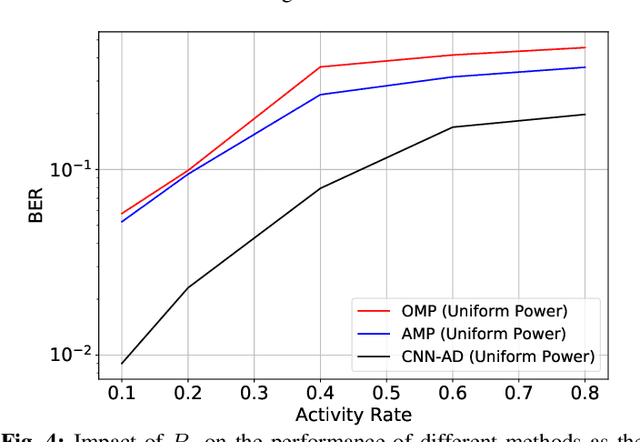
Recently, grant-free transmission paradigm has been introduced for massive Internet of Things (IoT) networks to save both time and bandwidth and transmit the message with low latency. In order to accurately decode the message of each device at the base station (BS), first, the active devices at each transmission frame must be identified. In this work, first we investigate the problem of activity detection as a threshold comparing problem. We show the convexity of the activity detection method through analyzing its probability of error which makes it possible to find the optimal threshold for minimizing the activity detection error. Consequently, to achieve an optimum solution, we propose a deep learning (DL)-based method called convolutional neural network (CNN)-activity detection (AD). In order to make it more practical, we consider unknown and time-varying activity rate for the IoT devices. Our simulations verify that our proposed CNN-AD method can achieve higher performance compared to the existing non-Bayesian greedy-based methods. This is while existing methods need to know the activity rate of IoT devices, while our method works for unknown and even time-varying activity rates
Sub-Graph Learning for Spatiotemporal Forecasting via Knowledge Distillation
Nov 17, 2022One of the challenges in studying the interactions in large graphs is to learn their diverse pattern and various interaction types. Hence, considering only one distribution and model to study all nodes and ignoring their diversity and local features in their neighborhoods, might severely affect the overall performance. Based on the structural information of the nodes in the graph and the interactions between them, the main graph can be divided into multiple sub-graphs. This graph partitioning can tremendously affect the learning process, however the overall performance is highly dependent on the clustering method to avoid misleading the model. In this work, we present a new framework called KD-SGL to effectively learn the sub-graphs, where we define one global model to learn the overall structure of the graph and multiple local models for each sub-graph. We assess the performance of the proposed framework and evaluate it on public datasets. Based on the achieved results, it can improve the performance of the state-of-the-arts spatiotemporal models with comparable results compared to ensemble of models with less complexity.
Deep Learning Based Sphere Decoding
Jul 06, 2018
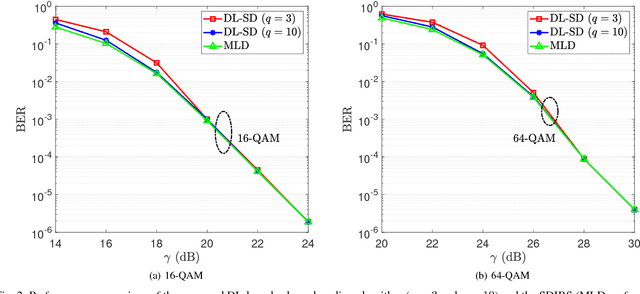
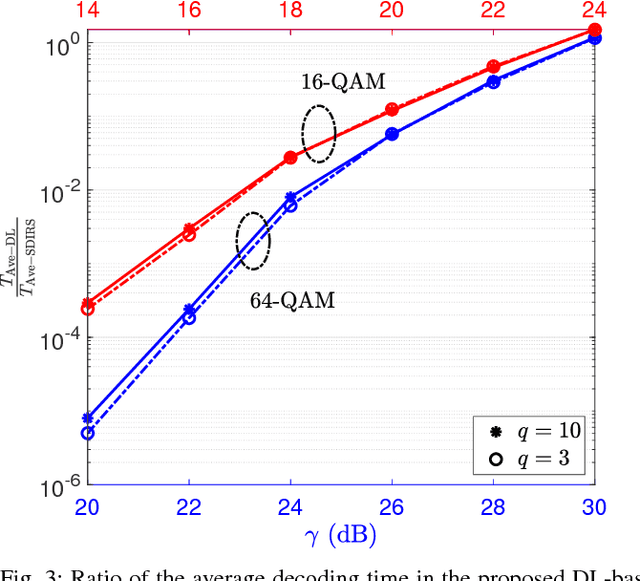
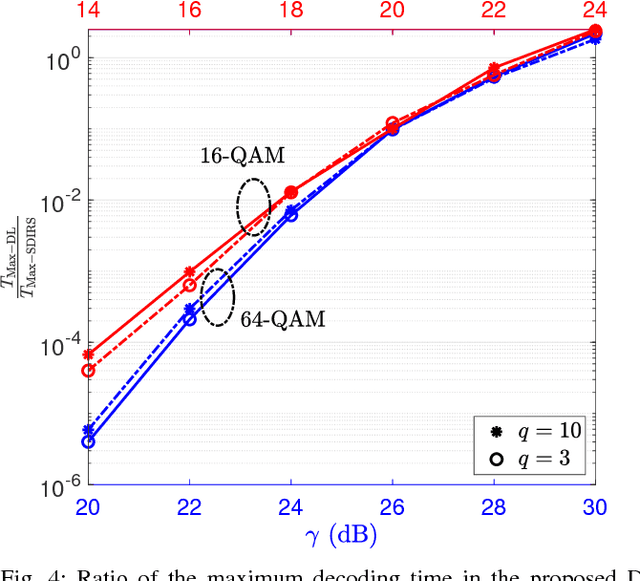
In this paper, a deep learning (DL)-based sphere decoding algorithm is proposed, where the radius of the decoding hypersphere is learnt by a deep neural network (DNN). The performance achieved by the proposed algorithm is very close to the optimal maximum likelihood decoding (MLD) over a wide range of signal-to-noise ratios (SNRs), while the computational complexity, compared to existing sphere decoding variants, is significantly reduced. This improvement is attributed to DNN's ability of intelligently learning the radius of the hypersphere used in decoding. The expected complexity of the proposed DL-based algorithm is analytically derived and compared with existing ones. It is shown that the number of lattice points inside the decoding hypersphere drastically reduces in the DL- based algorithm in both the average and worst-case senses. The effectiveness of the proposed algorithm is shown through simulation for high-dimensional multiple-input multiple-output (MIMO) systems, using high-order modulations.