 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJamming Detection and Channel Estimation for Spatially Correlated Beamspace Massive MIMO
Oct 18, 2024



In this paper, we investigate the problem of jamming detection and channel estimation during multi-user uplink beam training under random pilot jamming attacks in beamspace massive multi-input-multi-output (MIMO) systems. For jamming detection, we distinguish the signals from the jammer and the user by projecting the observation signals onto the pilot space. By using the multiple projected observation vectors corresponding to the unused pilots, we propose a jamming detection scheme based on the locally most powerful test (LMPT) for systems with general channel conditions. Analytical expressions for the probability of detection and false alarms are derived using the second-order statistics and likelihood functions of the projected observation vectors. For the detected jammer along with users, we propose a two-step minimum mean square error (MMSE) channel estimation using the projected observation vectors. As a part of the channel estimation, we develop schemes to estimate the norm and the phase of the inner-product of the legitimate pilot vector and the random jamming pilot vector, which can be obtained using linear MMSE estimation and a bilinear form of the multiple projected observation vectors. From simulations under different system parameters, we observe that the proposed technique improves the detection probability by 32.22% compared to the baseline at medium channel correlation level, and the channel estimation achieves a mean square error of -15.93dB.
Interleaved Training for Massive MIMO Downlink via Exploring Spatial Correlation
Jul 31, 2023



Interleaved training has been studied for single-user and multi-user massive MIMO downlink with either fully-digital or hybrid beamforming. However, the impact of channel correlation on its average training overhead is rarely addressed. In this paper, we explore the channel correlation to improve the interleaved training for single-user massive MIMO downlink. For the beam-domain interleaved training, we propose a modified scheme by optimizing the beam training codebook. The basic antenna-domain interleaved training is also improved by dynamically adjusting the training order of the base station (BS) antennas during the training process based on the values of the already trained channels. Exact and simplified approximate expressions of the average training length are derived in closed-form for the basic and modified beam-domain schemes and the basic antenna-domain scheme in correlated channels. For the modified antenna-domain scheme, a deep neural network (DNN)-based approximation is provided for fast performance evaluation. Analytical results and simulations verify the accuracy of our derived training length expressions and explicitly reveal the impact of system parameters on the average training length. In addition, the modified beam/antenna-domain schemes are shown to have a shorter average training length compared to the basic schemes.
Joint Port Selection Based Channel Acquisition for FDD Cell-Free Massive MIMO
Jul 20, 2023In frequency division duplexing (FDD) cell-free massive MIMO, the acquisition of the channel state information (CSI) is very challenging because of the large overhead required for the training and feedback of the downlink channels of multiple cooperating base stations (BSs). In this paper, for systems with partial uplink-downlink channel reciprocity, and a general spatial domain channel model with variations in the average port power and correlation among port coefficients, we propose a joint-port-selection-based CSI acquisition and feedback scheme for the downlink transmission with zero-forcing precoding. The scheme uses an eigenvalue-decomposition-based transformation to reduce the feedback overhead by exploring the port correlation. We derive the sum-rate of the system for any port selection. Based on the sum-rate result, we propose a low-complexity greedy-search-based joint port selection (GS-JPS) algorithm. Moreover, to adapt to fast time-varying scenarios, a supervised deep learning-enhanced joint port selection (DL-JPS) algorithm is proposed. Simulations verify the effectiveness of our proposed schemes and their advantage over existing port-selection channel acquisition schemes.
Deep Learning Based Sphere Decoding
Jul 06, 2018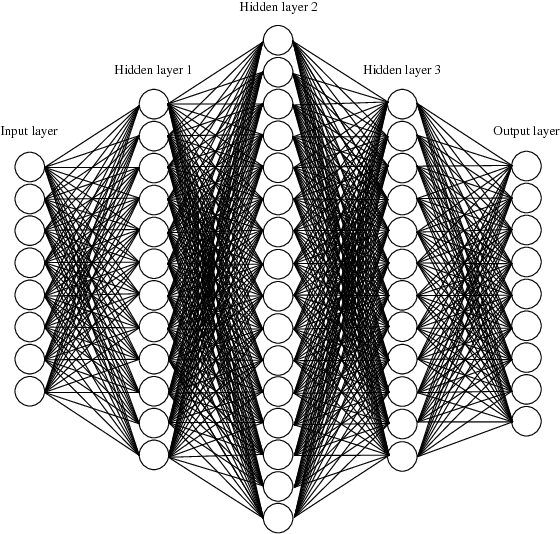
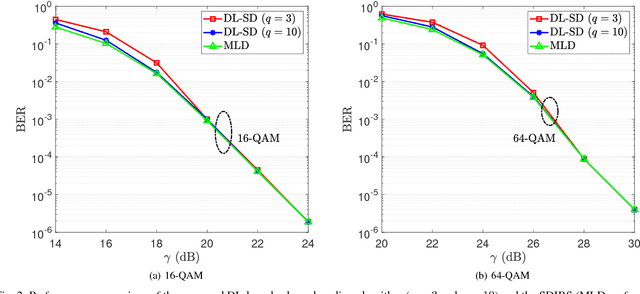
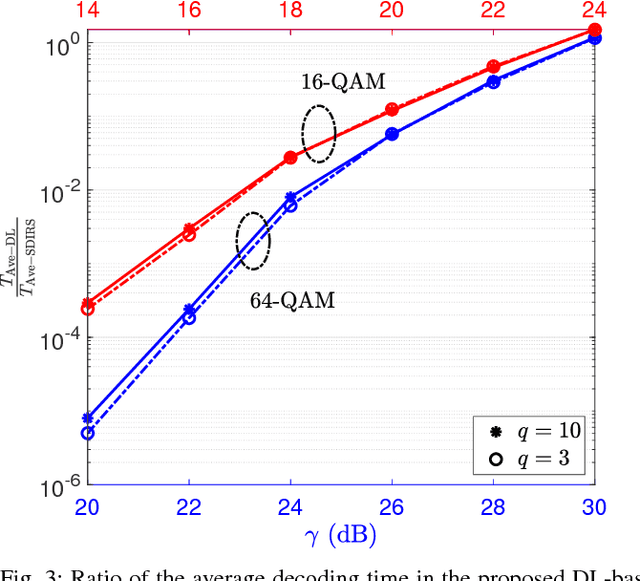
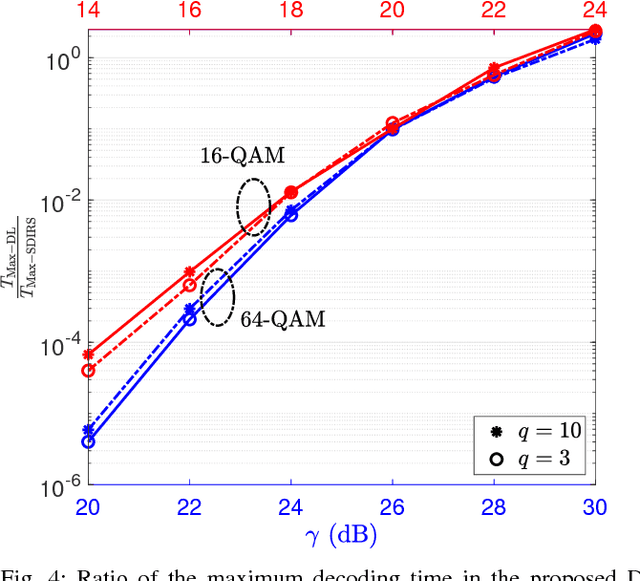
In this paper, a deep learning (DL)-based sphere decoding algorithm is proposed, where the radius of the decoding hypersphere is learnt by a deep neural network (DNN). The performance achieved by the proposed algorithm is very close to the optimal maximum likelihood decoding (MLD) over a wide range of signal-to-noise ratios (SNRs), while the computational complexity, compared to existing sphere decoding variants, is significantly reduced. This improvement is attributed to DNN's ability of intelligently learning the radius of the hypersphere used in decoding. The expected complexity of the proposed DL-based algorithm is analytically derived and compared with existing ones. It is shown that the number of lattice points inside the decoding hypersphere drastically reduces in the DL- based algorithm in both the average and worst-case senses. The effectiveness of the proposed algorithm is shown through simulation for high-dimensional multiple-input multiple-output (MIMO) systems, using high-order modulations.