 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing On-Device Large Language Model: Empirical Results and Implications for AI PC
May 22, 2025The increasing deployment of Large Language Models (LLMs) on edge devices, driven by model advancements and hardware improvements, offers significant privacy benefits. However, these on-device LLMs inherently face performance limitations due to reduced model capacity and necessary compression techniques. To address this, we introduce a systematic methodology -- encompassing model capability, development efficiency, and system resources -- for evaluating on-device LLMs. Our comprehensive evaluation, encompassing models from 0.5B to 14B parameters and seven post-training quantization (PTQ) methods on commodity laptops, yields several critical insights: 1) System-level metrics exhibit near-linear scaling with effective bits-per-weight (BPW). 2) A practical threshold exists around $\sim$3.5 effective BPW, larger models subjected to low-bit quantization consistently outperform smaller models utilizing higher bit-precision. 3) Quantization with low BPW incurs marginal accuracy loss but significant memory savings. 4) Determined by low-level implementation specifics power consumption on CPU, where computation-intensive operations spend more power than memory-intensive ones. These findings offer crucial insights and practical guidelines for the efficient deployment and optimized configuration of LLMs on resource-constrained edge devices. Our codebase is available at https://github.com/simmonssong/LLMOnDevice.
Harnessing Large Language Models Locally: Empirical Results and Implications for AI PC
May 21, 2025The increasing deployment of Large Language Models (LLMs) on edge devices, driven by model advancements and hardware improvements, offers significant privacy benefits. However, these on-device LLMs inherently face performance limitations due to reduced model capacity and necessary compression techniques. To address this, we introduce a systematic methodology -- encompassing model capability, development efficiency, and system resources -- for evaluating on-device LLMs. Our comprehensive evaluation, encompassing models from 0.5B to 14B parameters and seven post-training quantization (PTQ) methods on commodity laptops, yields several critical insights: 1) System-level metrics exhibit near-linear scaling with effective bits-per-weight (BPW). 2) A practical threshold exists around $\sim$3.5 effective BPW, larger models subjected to low-bit quantization consistently outperform smaller models utilizing higher bit-precision. 3) Quantization with low BPW incurs marginal accuracy loss but significant memory savings. 4) Determined by low-level implementation specifics power consumption on CPU, where computation-intensive operations spend more power than memory-intensive ones. These findings offer crucial insights and practical guidelines for the efficient deployment and optimized configuration of LLMs on resource-constrained edge devices. Our codebase is available at https://github.com/simmonssong/LLMOnDevice.
Evolution of Optimization Algorithms for Global Placement via Large Language Models
Apr 18, 2025Optimization algorithms are widely employed to tackle complex problems, but designing them manually is often labor-intensive and requires significant expertise. Global placement is a fundamental step in electronic design automation (EDA). While analytical approaches represent the state-of-the-art (SOTA) in global placement, their core optimization algorithms remain heavily dependent on heuristics and customized components, such as initialization strategies, preconditioning methods, and line search techniques. This paper presents an automated framework that leverages large language models (LLM) to evolve optimization algorithms for global placement. We first generate diverse candidate algorithms using LLM through carefully crafted prompts. Then we introduce an LLM-based genetic flow to evolve selected candidate algorithms. The discovered optimization algorithms exhibit substantial performance improvements across many benchmarks. Specifically, Our design-case-specific discovered algorithms achieve average HPWL improvements of \textbf{5.05\%}, \text{5.29\%} and \textbf{8.30\%} on MMS, ISPD2005 and ISPD2019 benchmarks, and up to \textbf{17\%} improvements on individual cases. Additionally, the discovered algorithms demonstrate good generalization ability and are complementary to existing parameter-tuning methods.
p-Laplacian Adaptation for Generative Pre-trained Vision-Language Models
Dec 17, 2023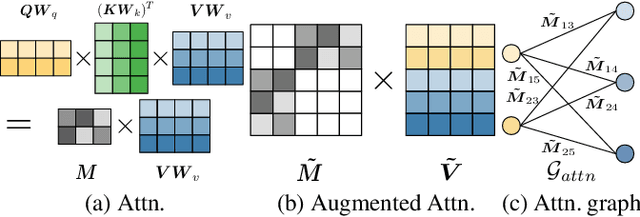



Vision-Language models (VLMs) pre-trained on large corpora have demonstrated notable success across a range of downstream tasks. In light of the rapidly increasing size of pre-trained VLMs, parameter-efficient transfer learning (PETL) has garnered attention as a viable alternative to full fine-tuning. One such approach is the adapter, which introduces a few trainable parameters into the pre-trained models while preserving the original parameters during adaptation. In this paper, we present a novel modeling framework that recasts adapter tuning after attention as a graph message passing process on attention graphs, where the projected query and value features and attention matrix constitute the node features and the graph adjacency matrix, respectively. Within this framework, tuning adapters in VLMs necessitates handling heterophilic graphs, owing to the disparity between the projected query and value space. To address this challenge, we propose a new adapter architecture, $p$-adapter, which employs $p$-Laplacian message passing in Graph Neural Networks (GNNs). Specifically, the attention weights are re-normalized based on the features, and the features are then aggregated using the calibrated attention matrix, enabling the dynamic exploitation of information with varying frequencies in the heterophilic attention graphs. We conduct extensive experiments on different pre-trained VLMs and multi-modal tasks, including visual question answering, visual entailment, and image captioning. The experimental results validate our method's significant superiority over other PETL methods.