 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multimodal Foundation Model to Enhance Generalizability and Data Efficiency for Pan-cancer Prognosis Prediction
Sep 16, 2025Multimodal data provides heterogeneous information for a holistic understanding of the tumor microenvironment. However, existing AI models often struggle to harness the rich information within multimodal data and extract poorly generalizable representations. Here we present MICE (Multimodal data Integration via Collaborative Experts), a multimodal foundation model that effectively integrates pathology images, clinical reports, and genomics data for precise pan-cancer prognosis prediction. Instead of conventional multi-expert modules, MICE employs multiple functionally diverse experts to comprehensively capture both cross-cancer and cancer-specific insights. Leveraging data from 11,799 patients across 30 cancer types, we enhanced MICE's generalizability by coupling contrastive and supervised learning. MICE outperformed both unimodal and state-of-the-art multi-expert-based multimodal models, demonstrating substantial improvements in C-index ranging from 3.8% to 11.2% on internal cohorts and 5.8% to 8.8% on independent cohorts, respectively. Moreover, it exhibited remarkable data efficiency across diverse clinical scenarios. With its enhanced generalizability and data efficiency, MICE establishes an effective and scalable foundation for pan-cancer prognosis prediction, holding strong potential to personalize tailored therapies and improve treatment outcomes.
Genome-Anchored Foundation Model Embeddings Improve Molecular Prediction from Histology Images
Jun 24, 2025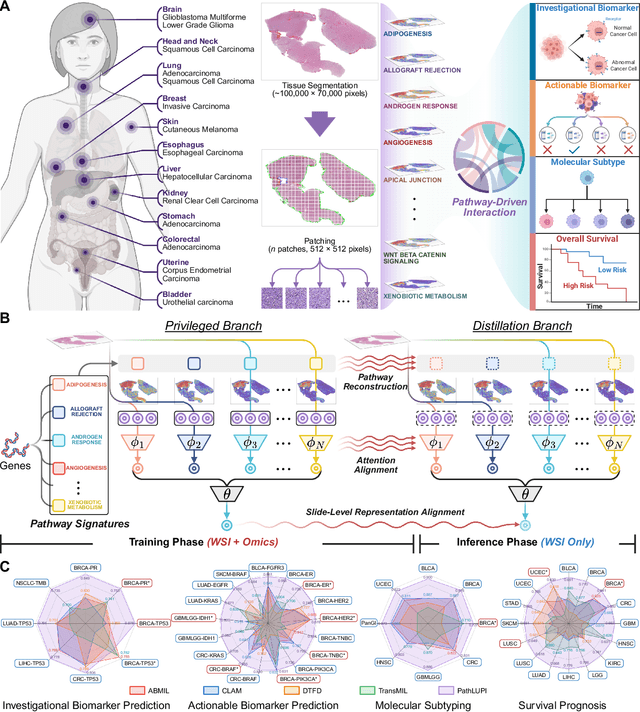
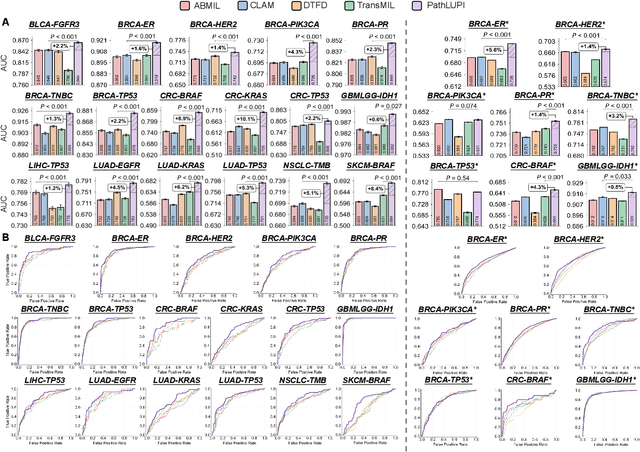
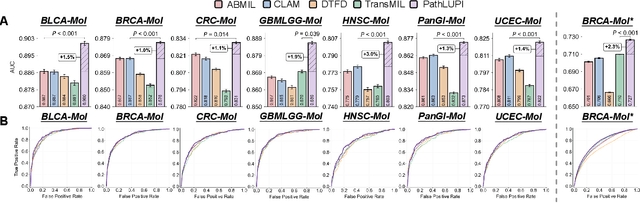
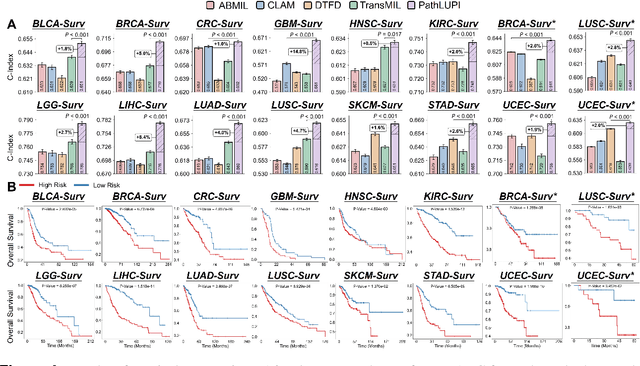
Precision oncology requires accurate molecular insights, yet obtaining these directly from genomics is costly and time-consuming for broad clinical use. Predicting complex molecular features and patient prognosis directly from routine whole-slide images (WSI) remains a major challenge for current deep learning methods. Here we introduce PathLUPI, which uses transcriptomic privileged information during training to extract genome-anchored histological embeddings, enabling effective molecular prediction using only WSIs at inference. Through extensive evaluation across 49 molecular oncology tasks using 11,257 cases among 20 cohorts, PathLUPI demonstrated superior performance compared to conventional methods trained solely on WSIs. Crucially, it achieves AUC $\geq$ 0.80 in 14 of the biomarker prediction and molecular subtyping tasks and C-index $\geq$ 0.70 in survival cohorts of 5 major cancer types. Moreover, PathLUPI embeddings reveal distinct cellular morphological signatures associated with specific genotypes and related biological pathways within WSIs. By effectively encoding molecular context to refine WSI representations, PathLUPI overcomes a key limitation of existing models and offers a novel strategy to bridge molecular insights with routine pathology workflows for wider clinical application.
PathBench: A comprehensive comparison benchmark for pathology foundation models towards precision oncology
May 26, 2025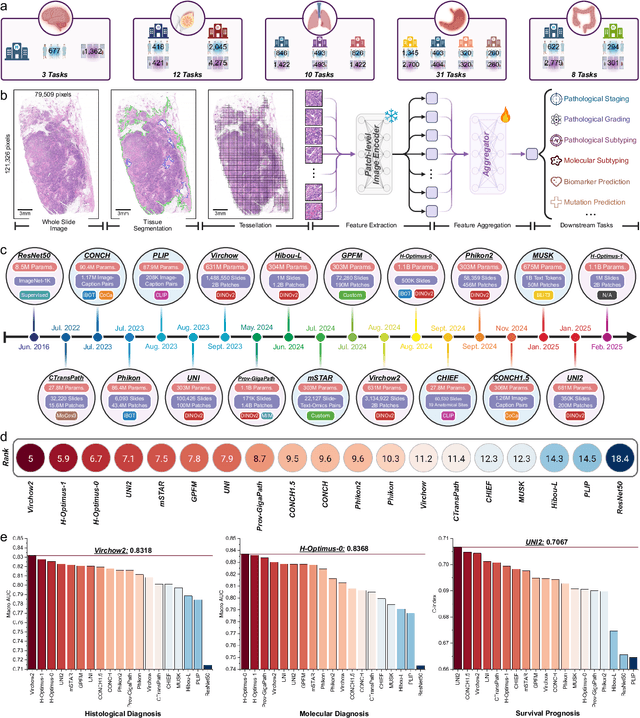



The emergence of pathology foundation models has revolutionized computational histopathology, enabling highly accurate, generalized whole-slide image analysis for improved cancer diagnosis, and prognosis assessment. While these models show remarkable potential across cancer diagnostics and prognostics, their clinical translation faces critical challenges including variability in optimal model across cancer types, potential data leakage in evaluation, and lack of standardized benchmarks. Without rigorous, unbiased evaluation, even the most advanced PFMs risk remaining confined to research settings, delaying their life-saving applications. Existing benchmarking efforts remain limited by narrow cancer-type focus, potential pretraining data overlaps, or incomplete task coverage. We present PathBench, the first comprehensive benchmark addressing these gaps through: multi-center in-hourse datasets spanning common cancers with rigorous leakage prevention, evaluation across the full clinical spectrum from diagnosis to prognosis, and an automated leaderboard system for continuous model assessment. Our framework incorporates large-scale data, enabling objective comparison of PFMs while reflecting real-world clinical complexity. All evaluation data comes from private medical providers, with strict exclusion of any pretraining usage to avoid data leakage risks. We have collected 15,888 WSIs from 8,549 patients across 10 hospitals, encompassing over 64 diagnosis and prognosis tasks. Currently, our evaluation of 19 PFMs shows that Virchow2 and H-Optimus-1 are the most effective models overall. This work provides researchers with a robust platform for model development and offers clinicians actionable insights into PFM performance across diverse clinical scenarios, ultimately accelerating the translation of these transformative technologies into routine pathology practice.
An Arbitrary-Modal Fusion Network for Volumetric Cranial Nerves Tract Segmentation
May 05, 2025The segmentation of cranial nerves (CNs) tract provides a valuable quantitative tool for the analysis of the morphology and trajectory of individual CNs. Multimodal CNs tract segmentation networks, e.g., CNTSeg, which combine structural Magnetic Resonance Imaging (MRI) and diffusion MRI, have achieved promising segmentation performance. However, it is laborious or even infeasible to collect complete multimodal data in clinical practice due to limitations in equipment, user privacy, and working conditions. In this work, we propose a novel arbitrary-modal fusion network for volumetric CNs tract segmentation, called CNTSeg-v2, which trains one model to handle different combinations of available modalities. Instead of directly combining all the modalities, we select T1-weighted (T1w) images as the primary modality due to its simplicity in data acquisition and contribution most to the results, which supervises the information selection of other auxiliary modalities. Our model encompasses an Arbitrary-Modal Collaboration Module (ACM) designed to effectively extract informative features from other auxiliary modalities, guided by the supervision of T1w images. Meanwhile, we construct a Deep Distance-guided Multi-stage (DDM) decoder to correct small errors and discontinuities through signed distance maps to improve segmentation accuracy. We evaluate our CNTSeg-v2 on the Human Connectome Project (HCP) dataset and the clinical Multi-shell Diffusion MRI (MDM) dataset. Extensive experimental results show that our CNTSeg-v2 achieves state-of-the-art segmentation performance, outperforming all competing methods.
Multimodal Data Integration for Precision Oncology: Challenges and Future Directions
Jun 28, 2024The essence of precision oncology lies in its commitment to tailor targeted treatments and care measures to each patient based on the individual characteristics of the tumor. The inherent heterogeneity of tumors necessitates gathering information from diverse data sources to provide valuable insights from various perspectives, fostering a holistic comprehension of the tumor. Over the past decade, multimodal data integration technology for precision oncology has made significant strides, showcasing remarkable progress in understanding the intricate details within heterogeneous data modalities. These strides have exhibited tremendous potential for improving clinical decision-making and model interpretation, contributing to the advancement of cancer care and treatment. Given the rapid progress that has been achieved, we provide a comprehensive overview of about 300 papers detailing cutting-edge multimodal data integration techniques in precision oncology. In addition, we conclude the primary clinical applications that have reaped significant benefits, including early assessment, diagnosis, prognosis, and biomarker discovery. Finally, derived from the findings of this survey, we present an in-depth analysis that explores the pivotal challenges and reveals essential pathways for future research in the field of multimodal data integration for precision oncology.
Cohort-Individual Cooperative Learning for Multimodal Cancer Survival Analysis
Apr 03, 2024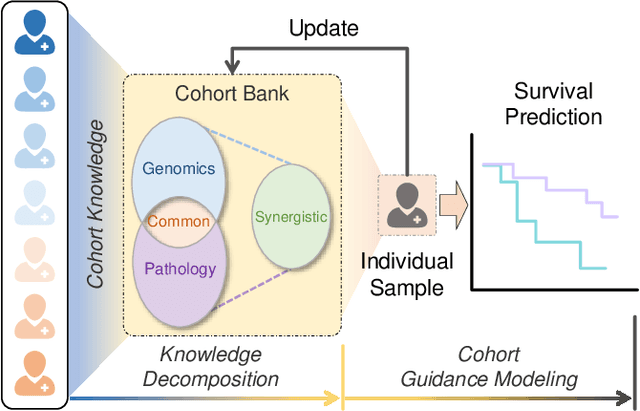
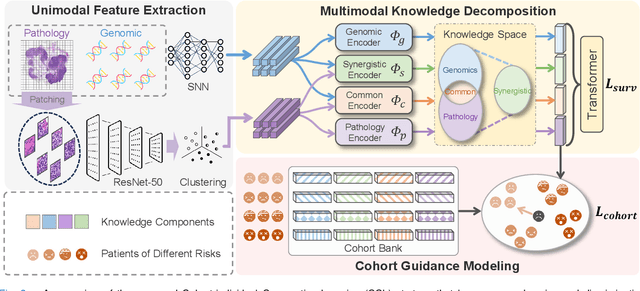
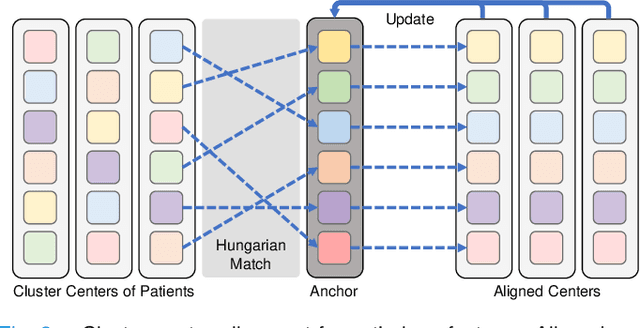
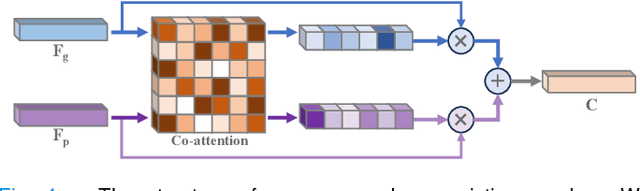
Recently, we have witnessed impressive achievements in cancer survival analysis by integrating multimodal data, e.g., pathology images and genomic profiles. However, the heterogeneity and high dimensionality of these modalities pose significant challenges for extracting discriminative representations while maintaining good generalization. In this paper, we propose a Cohort-individual Cooperative Learning (CCL) framework to advance cancer survival analysis by collaborating knowledge decomposition and cohort guidance. Specifically, first, we propose a Multimodal Knowledge Decomposition (MKD) module to explicitly decompose multimodal knowledge into four distinct components: redundancy, synergy and uniqueness of the two modalities. Such a comprehensive decomposition can enlighten the models to perceive easily overlooked yet important information, facilitating an effective multimodal fusion. Second, we propose a Cohort Guidance Modeling (CGM) to mitigate the risk of overfitting task-irrelevant information. It can promote a more comprehensive and robust understanding of the underlying multimodal data, while avoiding the pitfalls of overfitting and enhancing the generalization ability of the model. By cooperating the knowledge decomposition and cohort guidance methods, we develop a robust multimodal survival analysis model with enhanced discrimination and generalization abilities. Extensive experimental results on five cancer datasets demonstrate the effectiveness of our model in integrating multimodal data for survival analysis.
Anatomy-guided fiber trajectory distribution estimation for cranial nerves tractography
Feb 29, 2024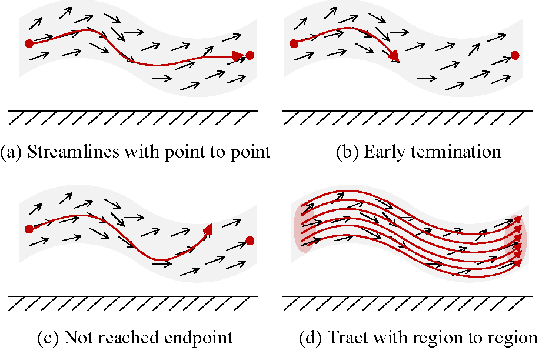


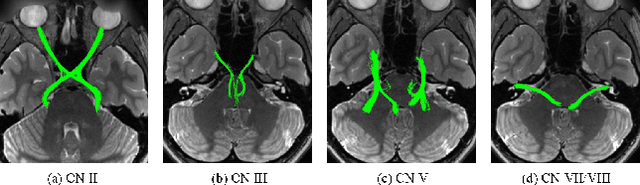
Diffusion MRI tractography is an important tool for identifying and analyzing the intracranial course of cranial nerves (CNs). However, the complex environment of the skull base leads to ambiguous spatial correspondence between diffusion directions and fiber geometry, and existing diffusion tractography methods of CNs identification are prone to producing erroneous trajectories and missing true positive connections. To overcome the above challenge, we propose a novel CNs identification framework with anatomy-guided fiber trajectory distribution, which incorporates anatomical shape prior knowledge during the process of CNs tracing to build diffusion tensor vector fields. We introduce higher-order streamline differential equations for continuous flow field representations to directly characterize the fiber trajectory distribution of CNs from the tract-based level. The experimental results on the vivo HCP dataset and the clinical MDM dataset demonstrate that the proposed method reduces false-positive fiber production compared to competing methods and produces reconstructed CNs (i.e. CN II, CN III, CN V, and CN VII/VIII) that are judged to better correspond to the known anatomy.
Appearance-guided Attentive Self-Paced Learning for Unsupervised Salient Object Detection
Jul 13, 2022

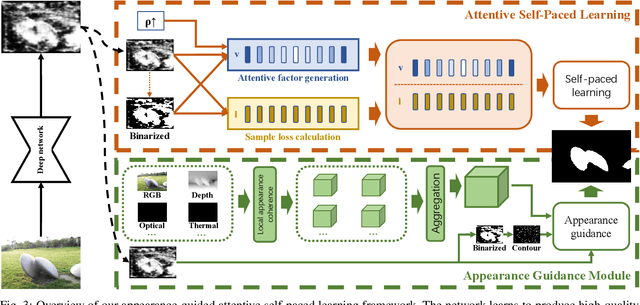
Existing Deep-Learning-based (DL-based) Unsupervised Salient Object Detection (USOD) methods learn saliency information in images based on the prior knowledge of traditional saliency methods and pretrained deep networks. However, these methods employ a simple learning strategy to train deep networks and therefore cannot properly incorporate the "hidden" information of the training samples into the learning process. Moreover, appearance information, which is crucial for segmenting objects, is only used as post-process after the network training process. To address these two issues, we propose a novel appearance-guided attentive self-paced learning framework for unsupervised salient object detection. The proposed framework integrates both self-paced learning (SPL) and appearance guidance into a unified learning framework. Specifically, for the first issue, we propose an Attentive Self-Paced Learning (ASPL) paradigm that organizes the training samples in a meaningful order to excavate gradually more detailed saliency information. Our ASPL facilitates our framework capable of automatically producing soft attention weights that measure the learning difficulty of training samples in a purely self-learning way. For the second issue, we propose an Appearance Guidance Module (AGM), which formulates the local appearance contrast of each pixel as the probability of saliency boundary and finds the potential boundary of the target objects by maximizing the probability. Furthermore, we further extend our framework to other multi-modality SOD tasks by aggregating the appearance vectors of other modality data, such as depth map, thermal image or optical flow. Extensive experiments on RGB, RGB-D, RGB-T and video SOD benchmarks prove that our framework achieves state-of-the-art performance against existing USOD methods and is comparable to the latest supervised SOD methods.
Benchmarking Deep Models for Salient Object Detection
Feb 07, 2022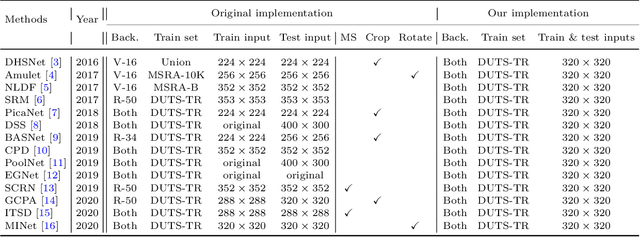

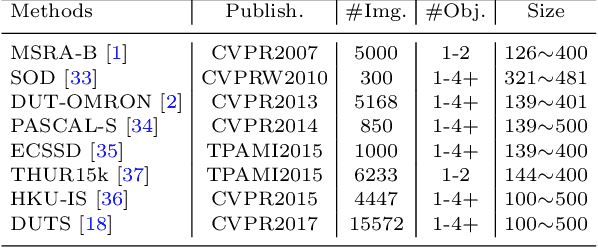

In recent years, deep network-based methods have continuously refreshed state-of-the-art performance on Salient Object Detection (SOD) task. However, the performance discrepancy caused by different implementation details may conceal the real progress in this task. Making an impartial comparison is required for future researches. To meet this need, we construct a general SALient Object Detection (SALOD) benchmark to conduct a comprehensive comparison among several representative SOD methods. Specifically, we re-implement 14 representative SOD methods by using consistent settings for training. Moreover, two additional protocols are set up in our benchmark to investigate the robustness of existing methods in some limited conditions. In the first protocol, we enlarge the difference between objectness distributions of train and test sets to evaluate the robustness of these SOD methods. In the second protocol, we build multiple train subsets with different scales to validate whether these methods can extract discriminative features from only a few samples. In the above experiments, we find that existing loss functions usually specialized in some metrics but reported inferior results on the others. Therefore, we propose a novel Edge-Aware (EA) loss that promotes deep networks to learn more discriminative features by integrating both pixel- and image-level supervision signals. Experiments prove that our EA loss reports more robust performances compared to existing losses.
Activation to Saliency: Forming High-Quality Labels for Completely Unsupervised Salient Object Detection
Dec 24, 2021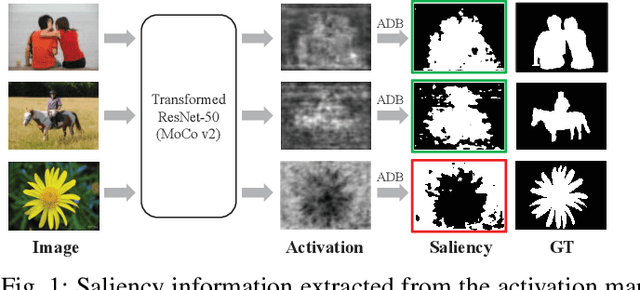
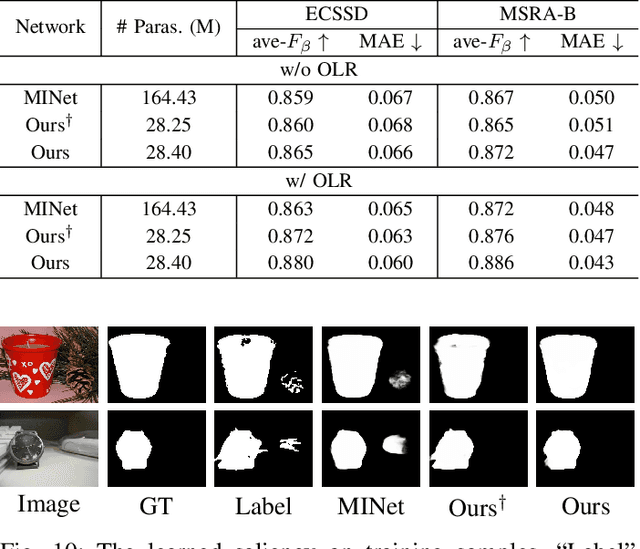
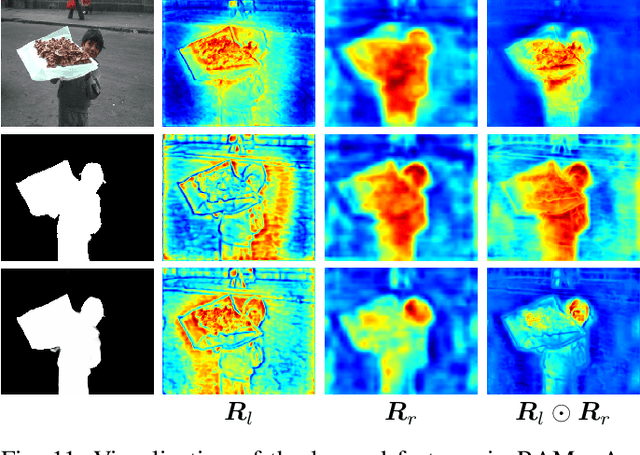

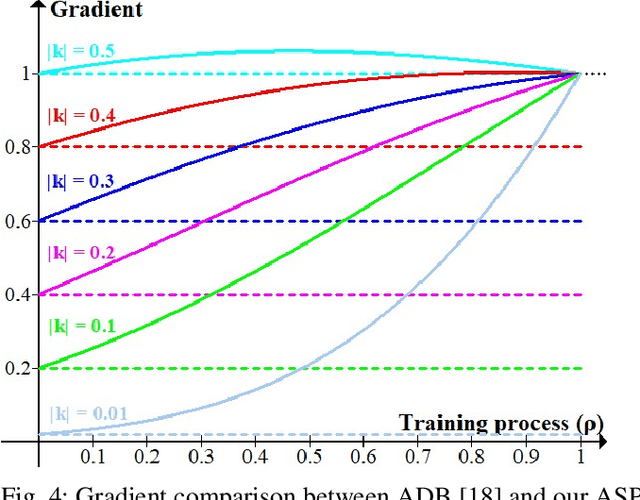
Existing deep learning-based Unsupervised Salient Object Detection (USOD) methods rely on supervised pre-trained deep models. Moreover, they generate pseudo labels based on hand-crafted features, which lack high-level semantic information. In order to overcome these shortcomings, we propose a new two-stage Activation-to-Saliency (A2S) framework that effectively excavates high-quality saliency cues to train a robust saliency detector. It is worth noting that our method does not require any manual annotation, even in the pre-training phase. In the first stage, we transform an unsupervisedly pre-trained network to aggregate multi-level features to a single activation map, where an Adaptive Decision Boundary (ADB) is proposed to assist the training of the transformed network. Moreover, a new loss function is proposed to facilitate the generation of high-quality pseudo labels. In the second stage, a self-rectification learning paradigm strategy is developed to train a saliency detector and refine the pseudo labels online. In addition, we construct a lightweight saliency detector using two Residual Attention Modules (RAMs) to largely reduce the risk of overfitting. Extensive experiments on several SOD benchmarks prove that our framework reports significant performance compared with existing USOD methods. Moreover, training our framework on 3,000 images consumes about 1 hour, which is over 30$\times$ faster than previous state-of-the-art methods.