 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActivation to Saliency: Forming High-Quality Labels for Completely Unsupervised Salient Object Detection
Paper and Code
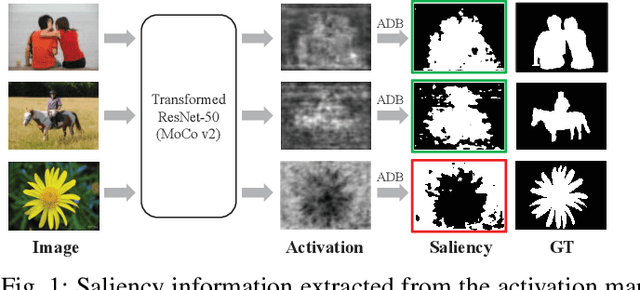
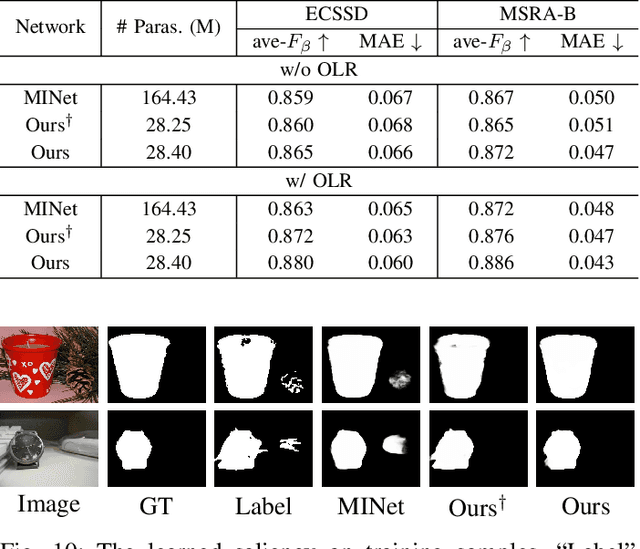
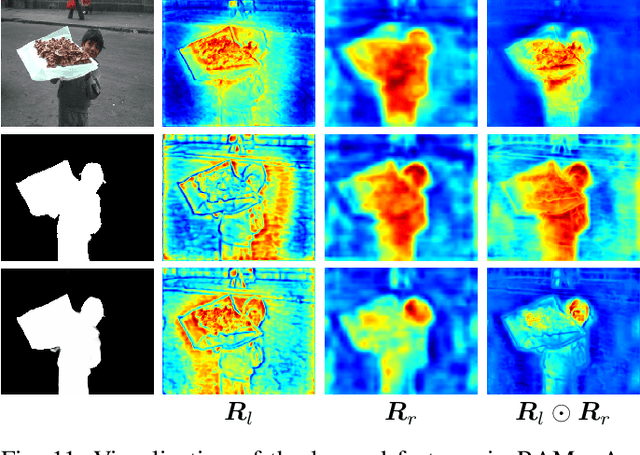

Existing deep learning-based Unsupervised Salient Object Detection (USOD) methods rely on supervised pre-trained deep models. Moreover, they generate pseudo labels based on hand-crafted features, which lack high-level semantic information. In order to overcome these shortcomings, we propose a new two-stage Activation-to-Saliency (A2S) framework that effectively excavates high-quality saliency cues to train a robust saliency detector. It is worth noting that our method does not require any manual annotation, even in the pre-training phase. In the first stage, we transform an unsupervisedly pre-trained network to aggregate multi-level features to a single activation map, where an Adaptive Decision Boundary (ADB) is proposed to assist the training of the transformed network. Moreover, a new loss function is proposed to facilitate the generation of high-quality pseudo labels. In the second stage, a self-rectification learning paradigm strategy is developed to train a saliency detector and refine the pseudo labels online. In addition, we construct a lightweight saliency detector using two Residual Attention Modules (RAMs) to largely reduce the risk of overfitting. Extensive experiments on several SOD benchmarks prove that our framework reports significant performance compared with existing USOD methods. Moreover, training our framework on 3,000 images consumes about 1 hour, which is over 30$\times$ faster than previous state-of-the-art methods.