 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActivation to Saliency: Forming High-Quality Labels for Completely Unsupervised Salient Object Detection
Dec 24, 2021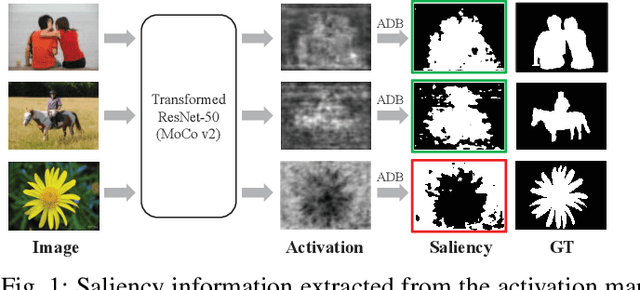
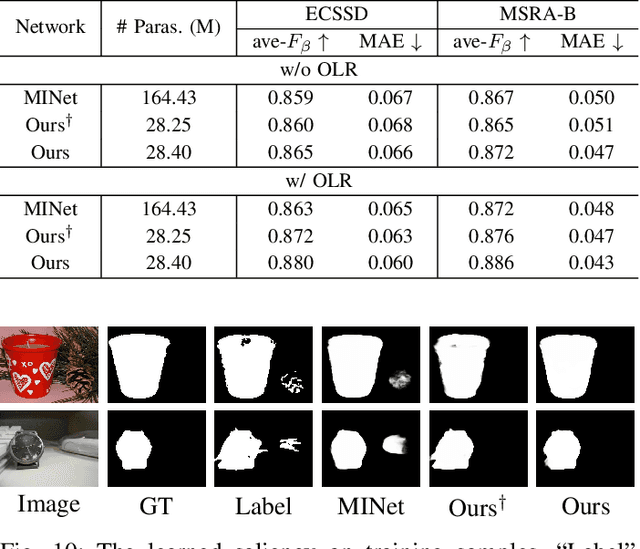
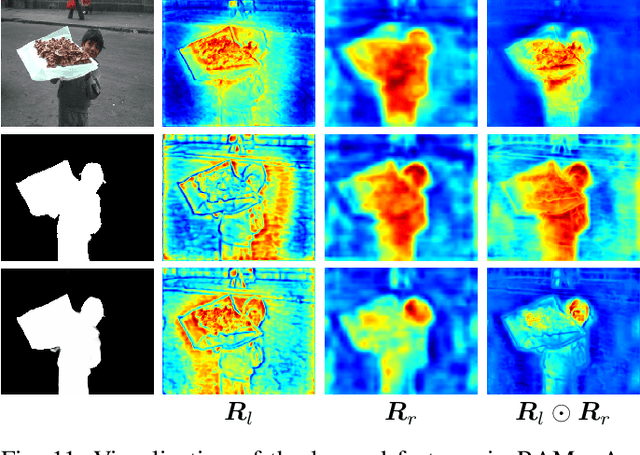

Existing deep learning-based Unsupervised Salient Object Detection (USOD) methods rely on supervised pre-trained deep models. Moreover, they generate pseudo labels based on hand-crafted features, which lack high-level semantic information. In order to overcome these shortcomings, we propose a new two-stage Activation-to-Saliency (A2S) framework that effectively excavates high-quality saliency cues to train a robust saliency detector. It is worth noting that our method does not require any manual annotation, even in the pre-training phase. In the first stage, we transform an unsupervisedly pre-trained network to aggregate multi-level features to a single activation map, where an Adaptive Decision Boundary (ADB) is proposed to assist the training of the transformed network. Moreover, a new loss function is proposed to facilitate the generation of high-quality pseudo labels. In the second stage, a self-rectification learning paradigm strategy is developed to train a saliency detector and refine the pseudo labels online. In addition, we construct a lightweight saliency detector using two Residual Attention Modules (RAMs) to largely reduce the risk of overfitting. Extensive experiments on several SOD benchmarks prove that our framework reports significant performance compared with existing USOD methods. Moreover, training our framework on 3,000 images consumes about 1 hour, which is over 30$\times$ faster than previous state-of-the-art methods.
Confidence-guided Adaptive Gate and Dual Differential Enhancement for Video Salient Object Detection
May 14, 2021
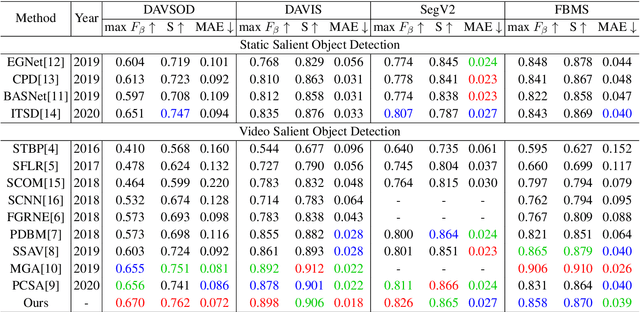

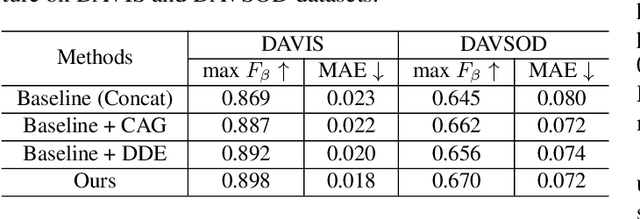
Video salient object detection (VSOD) aims to locate and segment the most attractive object by exploiting both spatial cues and temporal cues hidden in video sequences. However, spatial and temporal cues are often unreliable in real-world scenarios, such as low-contrast foreground, fast motion, and multiple moving objects. To address these problems, we propose a new framework to adaptively capture available information from spatial and temporal cues, which contains Confidence-guided Adaptive Gate (CAG) modules and Dual Differential Enhancement (DDE) modules. For both RGB features and optical flow features, CAG estimates confidence scores supervised by the IoU between predictions and the ground truths to re-calibrate the information with a gate mechanism. DDE captures the differential feature representation to enrich the spatial and temporal information and generate the fused features. Experimental results on four widely used datasets demonstrate the effectiveness of the proposed method against thirteen state-of-the-art methods.
A Novel Teacher-Student Learning Framework For Occluded Person Re-Identification
Jul 07, 2019
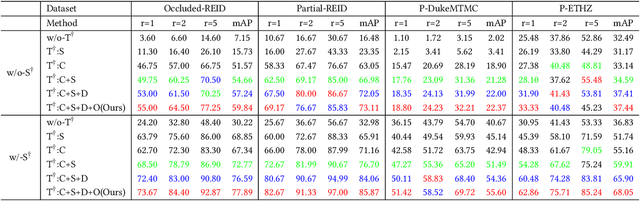

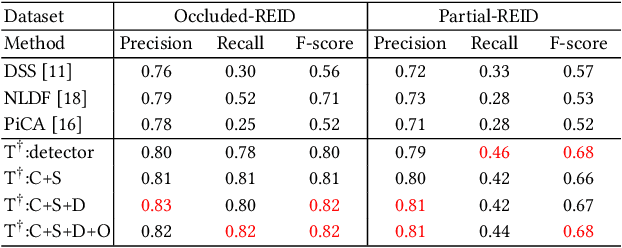
Person re-identification (re-id) has made great progress in recent years, but occlusion is still a challenging problem which significantly degenerates the identification performance. In this paper, we design a teacher-student learning framework to learn an occlusion-robust model from the full-body person domain to the occluded person domain. Notably, the teacher network only uses large-scale full-body person data to simulate the learning process of occluded person re-id. Based on the teacher network, the student network then trains a better model by using inadequate real-world occluded person data. In order to transfer more knowledge from the teacher network to the student network, we equip the proposed framework with a co-saliency network and a cross-domain simulator. The co-saliency network extracts the backbone features, and two separated collaborative branches are followed by the backbone. One branch is a classification branch for identity recognition and the other is a co-saliency branch for guiding the network to highlight meaningful parts without any manual annotation. The cross-domain simulator generates artificial occlusions on full-body person data under a growing probability so that the teacher network could train a cross-domain model by observing more and more occluded cases. Experiments on four occluded person re-id benchmarks show that our method outperforms other state-of-the-art methods.